 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResolving Word Vagueness with Scenario-guided Adapter for Natural Language Inference
Paper and Code
May 21, 2024


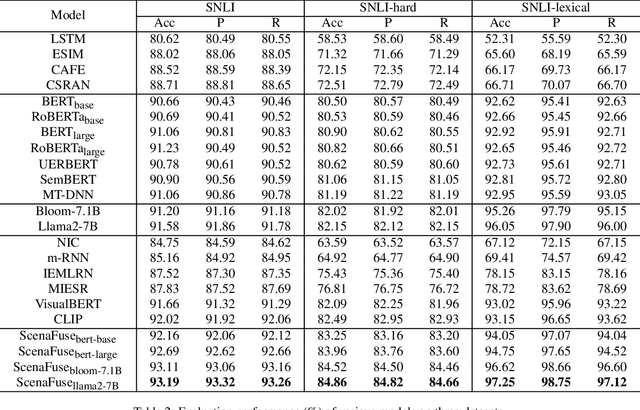
Natural Language Inference (NLI) is a crucial task in natural language processing that involves determining the relationship between two sentences, typically referred to as the premise and the hypothesis. However, traditional NLI models solely rely on the semantic information inherent in independent sentences and lack relevant situational visual information, which can hinder a complete understanding of the intended meaning of the sentences due to the ambiguity and vagueness of language. To address this challenge, we propose an innovative ScenaFuse adapter that simultaneously integrates large-scale pre-trained linguistic knowledge and relevant visual information for NLI tasks. Specifically, we first design an image-sentence interaction module to incorporate visuals into the attention mechanism of the pre-trained model, allowing the two modalities to interact comprehensively. Furthermore, we introduce an image-sentence fusion module that can adaptively integrate visual information from images and semantic information from sentences. By incorporating relevant visual information and leveraging linguistic knowledge, our approach bridges the gap between language and vision, leading to improved understanding and inference capabilities in NLI tasks. Extensive benchmark experiments demonstrate that our proposed ScenaFuse, a scenario-guided approach, consistently boosts NLI performance.