 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA transformer-BiGRU-based framework with data augmentation and confident learning for network intrusion detection
Sep 05, 2025



In today's fast-paced digital communication, the surge in network traffic data and frequency demands robust and precise network intrusion solutions. Conventional machine learning methods struggle to grapple with complex patterns within the vast network intrusion datasets, which suffer from data scarcity and class imbalance. As a result, we have integrated machine learning and deep learning techniques within the network intrusion detection system to bridge this gap. This study has developed TrailGate, a novel framework that combines machine learning and deep learning techniques. By integrating Transformer and Bidirectional Gated Recurrent Unit (BiGRU) architectures with advanced feature selection strategies and supplemented by data augmentation techniques, TrailGate can identifies common attack types and excels at detecting and mitigating emerging threats. This algorithmic fusion excels at detecting common and well-understood attack types and has the unique ability to swiftly identify and neutralize emerging threats that stem from existing paradigms.
DeepSelective: Feature Gating and Representation Matching for Interpretable Clinical Prediction
Apr 15, 2025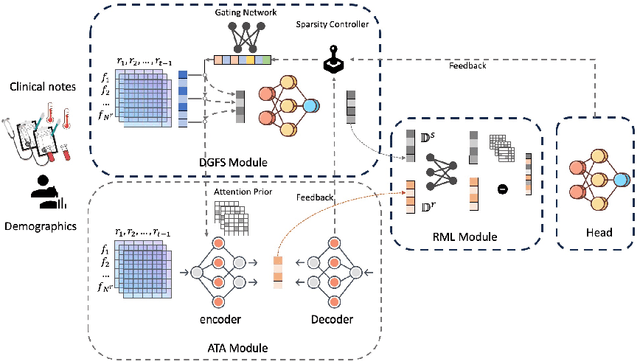

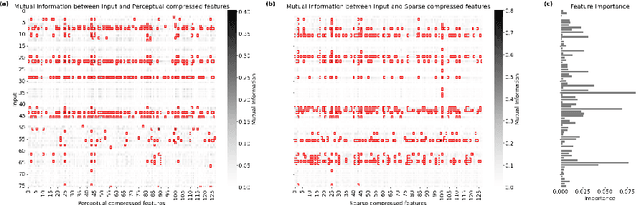
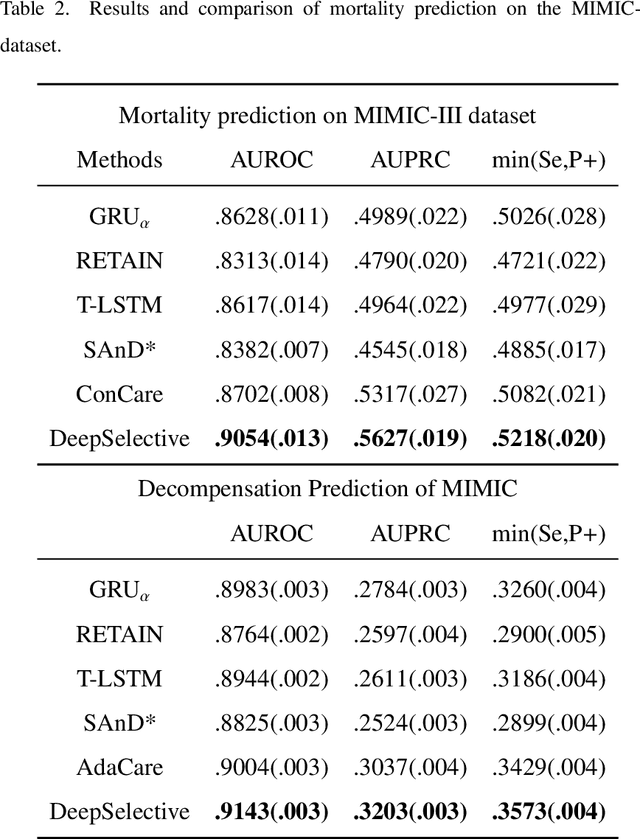
The rapid accumulation of Electronic Health Records (EHRs) has transformed healthcare by providing valuable data that enhance clinical predictions and diagnoses. While conventional machine learning models have proven effective, they often lack robust representation learning and depend heavily on expert-crafted features. Although deep learning offers powerful solutions, it is often criticized for its lack of interpretability. To address these challenges, we propose DeepSelective, a novel end to end deep learning framework for predicting patient prognosis using EHR data, with a strong emphasis on enhancing model interpretability. DeepSelective combines data compression techniques with an innovative feature selection approach, integrating custom-designed modules that work together to improve both accuracy and interpretability. Our experiments demonstrate that DeepSelective not only enhances predictive accuracy but also significantly improves interpretability, making it a valuable tool for clinical decision-making. The source code is freely available at http://www.healthinformaticslab.org/supp/resources.php .
Dual-level Mixup for Graph Few-shot Learning with Fewer Tasks
Feb 19, 2025



Graph neural networks have been demonstrated as a powerful paradigm for effectively learning graph-structured data on the web and mining content from it.Current leading graph models require a large number of labeled samples for training, which unavoidably leads to overfitting in few-shot scenarios. Recent research has sought to alleviate this issue by simultaneously leveraging graph learning and meta-learning paradigms. However, these graph meta-learning models assume the availability of numerous meta-training tasks to learn transferable meta-knowledge. Such assumption may not be feasible in the real world due to the difficulty of constructing tasks and the substantial costs involved. Therefore, we propose a SiMple yet effectIve approach for graph few-shot Learning with fEwer tasks, named SMILE. We introduce a dual-level mixup strategy, encompassing both within-task and across-task mixup, to simultaneously enrich the available nodes and tasks in meta-learning. Moreover, we explicitly leverage the prior information provided by the node degrees in the graph to encode expressive node representations. Theoretically, we demonstrate that SMILE can enhance the model generalization ability. Empirically, SMILE consistently outperforms other competitive models by a large margin across all evaluated datasets with in-domain and cross-domain settings. Our anonymous code can be found here.
Boosting Short Text Classification with Multi-Source Information Exploration and Dual-Level Contrastive Learning
Jan 16, 2025



Short text classification, as a research subtopic in natural language processing, is more challenging due to its semantic sparsity and insufficient labeled samples in practical scenarios. We propose a novel model named MI-DELIGHT for short text classification in this work. Specifically, it first performs multi-source information (i.e., statistical information, linguistic information, and factual information) exploration to alleviate the sparsity issues. Then, the graph learning approach is adopted to learn the representation of short texts, which are presented in graph forms. Moreover, we introduce a dual-level (i.e., instance-level and cluster-level) contrastive learning auxiliary task to effectively capture different-grained contrastive information within massive unlabeled data. Meanwhile, previous models merely perform the main task and auxiliary tasks in parallel, without considering the relationship among tasks. Therefore, we introduce a hierarchical architecture to explicitly model the correlations between tasks. We conduct extensive experiments across various benchmark datasets, demonstrating that MI-DELIGHT significantly surpasses previous competitive models. It even outperforms popular large language models on several datasets.
A Simple Graph Contrastive Learning Framework for Short Text Classification
Jan 16, 2025



Short text classification has gained significant attention in the information age due to its prevalence and real-world applications. Recent advancements in graph learning combined with contrastive learning have shown promising results in addressing the challenges of semantic sparsity and limited labeled data in short text classification. However, existing models have certain limitations. They rely on explicit data augmentation techniques to generate contrastive views, resulting in semantic corruption and noise. Additionally, these models only focus on learning the intrinsic consistency between the generated views, neglecting valuable discriminative information from other potential views. To address these issues, we propose a Simple graph contrastive learning framework for Short Text Classification (SimSTC). Our approach involves performing graph learning on multiple text-related component graphs to obtain multi-view text embeddings. Subsequently, we directly apply contrastive learning on these embeddings. Notably, our method eliminates the need for data augmentation operations to generate contrastive views while still leveraging the benefits of multi-view contrastive learning. Despite its simplicity, our model achieves outstanding performance, surpassing large language models on various datasets.
Information Entropy Invariance: Enhancing Length Extrapolation in Attention Mechanisms
Jan 15, 2025Improving the length extrapolation capabilities of Large Language Models (LLMs) remains a critical challenge in natural language processing. Many recent efforts have focused on modifying the scaled dot-product attention mechanism, and often introduce scaled temperatures without rigorous theoretical justification. To fill this gap, we introduce a novel approach based on information entropy invariance. We propose two new scaled temperatures to enhance length extrapolation. First, a training-free method InfoScale is designed for dot-product attention, and preserves focus on original tokens during length extrapolation by ensuring information entropy remains consistent. Second, we theoretically analyze the impact of scaling (CosScale) on cosine attention. Experimental data demonstrates that combining InfoScale and CosScale achieves state-of-the-art performance on the GAU-{\alpha} model with a context window extended to 64 times the training length, and outperforms seven existing methods. Our analysis reveals that significantly increasing CosScale approximates windowed attention, and highlights the significance of attention score dilution as a key challenge in long-range context handling. The code and data are available at https://github.com/HT-NEKO/InfoScale.
Enhancing Unsupervised Graph Few-shot Learning via Set Functions and Optimal Transport
Jan 10, 2025



Graph few-shot learning has garnered significant attention for its ability to rapidly adapt to downstream tasks with limited labeled data, sparking considerable interest among researchers. Recent advancements in graph few-shot learning models have exhibited superior performance across diverse applications. Despite their successes, several limitations still exist. First, existing models in the meta-training phase predominantly focus on instance-level features within tasks, neglecting crucial set-level features essential for distinguishing between different categories. Second, these models often utilize query sets directly on classifiers trained with support sets containing only a few labeled examples, overlooking potential distribution shifts between these sets and leading to suboptimal performance. Finally, previous models typically require necessitate abundant labeled data from base classes to extract transferable knowledge, which is typically infeasible in real-world scenarios. To address these issues, we propose a novel model named STAR, which leverages Set funcTions and optimAl tRansport for enhancing unsupervised graph few-shot learning. Specifically, STAR utilizes expressive set functions to obtain set-level features in an unsupervised manner and employs optimal transport principles to align the distributions of support and query sets, thereby mitigating distribution shift effects. Theoretical analysis demonstrates that STAR can capture more task-relevant information and enhance generalization capabilities. Empirically, extensive experiments across multiple datasets validate the effectiveness of STAR. Our code can be found here.
Meta-GPS++: Enhancing Graph Meta-Learning with Contrastive Learning and Self-Training
Jul 20, 2024



Node classification is an essential problem in graph learning. However, many models typically obtain unsatisfactory performance when applied to few-shot scenarios. Some studies have attempted to combine meta-learning with graph neural networks to solve few-shot node classification on graphs. Despite their promising performance, some limitations remain. First, they employ the node encoding mechanism of homophilic graphs to learn node embeddings, even in heterophilic graphs. Second, existing models based on meta-learning ignore the interference of randomness in the learning process. Third, they are trained using only limited labeled nodes within the specific task, without explicitly utilizing numerous unlabeled nodes. Finally, they treat almost all sampled tasks equally without customizing them for their uniqueness. To address these issues, we propose a novel framework for few-shot node classification called Meta-GPS++. Specifically, we first adopt an efficient method to learn discriminative node representations on homophilic and heterophilic graphs. Then, we leverage a prototype-based approach to initialize parameters and contrastive learning for regularizing the distribution of node embeddings. Moreover, we apply self-training to extract valuable information from unlabeled nodes. Additionally, we adopt S$^2$ (scaling & shifting) transformation to learn transferable knowledge from diverse tasks. The results on real-world datasets show the superiority of Meta-GPS++. Our code is available here.
Resolving Word Vagueness with Scenario-guided Adapter for Natural Language Inference
May 21, 2024


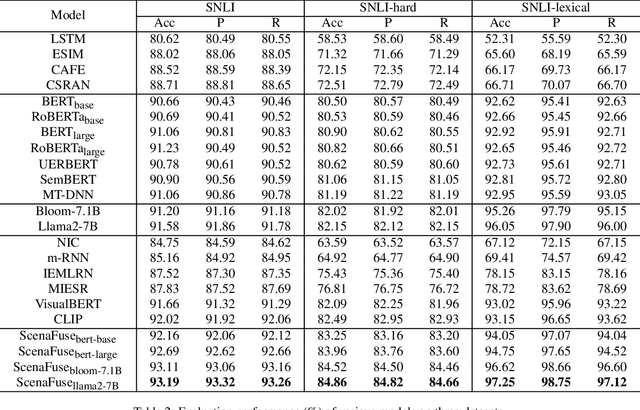
Natural Language Inference (NLI) is a crucial task in natural language processing that involves determining the relationship between two sentences, typically referred to as the premise and the hypothesis. However, traditional NLI models solely rely on the semantic information inherent in independent sentences and lack relevant situational visual information, which can hinder a complete understanding of the intended meaning of the sentences due to the ambiguity and vagueness of language. To address this challenge, we propose an innovative ScenaFuse adapter that simultaneously integrates large-scale pre-trained linguistic knowledge and relevant visual information for NLI tasks. Specifically, we first design an image-sentence interaction module to incorporate visuals into the attention mechanism of the pre-trained model, allowing the two modalities to interact comprehensively. Furthermore, we introduce an image-sentence fusion module that can adaptively integrate visual information from images and semantic information from sentences. By incorporating relevant visual information and leveraging linguistic knowledge, our approach bridges the gap between language and vision, leading to improved understanding and inference capabilities in NLI tasks. Extensive benchmark experiments demonstrate that our proposed ScenaFuse, a scenario-guided approach, consistently boosts NLI performance.
AMPCliff: quantitative definition and benchmarking of activity cliffs in antimicrobial peptides
Apr 15, 2024



Activity cliff (AC) is a phenomenon that a pair of similar molecules differ by a small structural alternation but exhibit a large difference in their biochemical activities. The AC of small molecules has been extensively investigated but limited knowledge is accumulated about the AC phenomenon in peptides with canonical amino acids. This study introduces a quantitative definition and benchmarking framework AMPCliff for the AC phenomenon in antimicrobial peptides (AMPs) composed by canonical amino acids. A comprehensive analysis of the existing AMP dataset reveals a significant prevalence of AC within AMPs. AMPCliff quantifies the activities of AMPs by the metric minimum inhibitory concentration (MIC), and defines 0.9 as the minimum threshold for the normalized BLOSUM62 similarity score between a pair of aligned peptides with at least two-fold MIC changes. This study establishes a benchmark dataset of paired AMPs in Staphylococcus aureus from the publicly available AMP dataset GRAMPA, and conducts a rigorous procedure to evaluate various AMP AC prediction models, including nine machine learning, four deep learning algorithms, four masked language models, and four generative language models. Our analysis reveals that these models are capable of detecting AMP AC events and the pre-trained protein language ESM2 model demonstrates superior performance across the evaluations. The predictive performance of AMP activity cliffs remains to be further improved, considering that ESM2 with 33 layers only achieves the Spearman correlation coefficient=0.50 for the regression task of the MIC values on the benchmark dataset. Source code and additional resources are available at https://www.healthinformaticslab.org/supp/ or https://github.com/Kewei2023/AMPCliff-generation.