 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDPI: Exploiting Parameter Heterogeneity for Interference-Free Fine-Tuning
Jan 25, 2026Supervised fine-tuning (SFT) is a crucial step for adapting large language models (LLMs) to downstream tasks. However, conflicting objectives across heterogeneous SFT tasks often induce the "seesaw effect": optimizing for one task may degrade performance on others, particularly when model parameters are updated indiscriminately. In this paper, we propose a principled approach to disentangle and isolate task-specific parameter regions, motivated by the hypothesis that parameter heterogeneity underlies cross-task interference. Specifically, we first independently fine-tune LLMs on diverse SFT tasks and identify each task's core parameter region as the subset of parameters exhibiting the largest updates. Tasks with highly overlapping core parameter regions are merged for joint training, while disjoint tasks are organized into different stages. During multi-stage SFT, core parameters acquired in prior tasks are frozen, thereby preventing overwriting by subsequent tasks. To verify the effectiveness of our method, we conducted intensive experiments on multiple public datasets. The results showed that our dynamic parameter isolation strategy consistently reduced data conflicts and achieved consistent performance improvements compared to multi-stage and multi-task tuning baselines.
Who Stole Your Data? A Method for Detecting Unauthorized RAG Theft
Oct 09, 2025Retrieval-augmented generation (RAG) enhances Large Language Models (LLMs) by mitigating hallucinations and outdated information issues, yet simultaneously facilitates unauthorized data appropriation at scale. This paper addresses this challenge through two key contributions. First, we introduce RPD, a novel dataset specifically designed for RAG plagiarism detection that encompasses diverse professional domains and writing styles, overcoming limitations in existing resources. Second, we develop a dual-layered watermarking system that embeds protection at both semantic and lexical levels, complemented by an interrogator-detective framework that employs statistical hypothesis testing on accumulated evidence. Extensive experimentation demonstrates our approach's effectiveness across varying query volumes, defense prompts, and retrieval parameters, while maintaining resilience against adversarial evasion techniques. This work establishes a foundational framework for intellectual property protection in retrieval-augmented AI systems.
R-Capsule: Compressing High-Level Plans for Efficient Large Language Model Reasoning
Sep 26, 2025Chain-of-Thought (CoT) prompting helps Large Language Models (LLMs) tackle complex reasoning by eliciting explicit step-by-step rationales. However, CoT's verbosity increases latency and memory usage and may propagate early errors across long chains. We propose the Reasoning Capsule (R-Capsule), a framework that aims to combine the efficiency of latent reasoning with the transparency of explicit CoT. The core idea is to compress the high-level plan into a small set of learned latent tokens (a Reasoning Capsule) while keeping execution steps lightweight or explicit. This hybrid approach is inspired by the Information Bottleneck (IB) principle, where we encourage the capsule to be approximately minimal yet sufficient for the task. Minimality is encouraged via a low-capacity bottleneck, which helps improve efficiency. Sufficiency is encouraged via a dual objective: a primary task loss for answer accuracy and an auxiliary plan-reconstruction loss that encourages the capsule to faithfully represent the original textual plan. The reconstruction objective helps ground the latent space, thereby improving interpretability and reducing the use of uninformative shortcuts. Our framework strikes a balance between efficiency, accuracy, and interpretability, thereby reducing the visible token footprint of reasoning while maintaining or improving accuracy on complex benchmarks. Our codes are available at: https://anonymous.4open.science/r/Reasoning-Capsule-7BE0
HoPE: Hyperbolic Rotary Positional Encoding for Stable Long-Range Dependency Modeling in Large Language Models
Sep 05, 2025Positional encoding mechanisms enable Transformers to model sequential structure and long-range dependencies in text. While absolute positional encodings struggle with extrapolation to longer sequences due to fixed positional representations, and relative approaches like Alibi exhibit performance degradation on extremely long contexts, the widely-used Rotary Positional Encoding (RoPE) introduces oscillatory attention patterns that hinder stable long-distance dependency modelling. We address these limitations through a geometric reformulation of positional encoding. Drawing inspiration from Lorentz transformations in hyperbolic geometry, we propose Hyperbolic Rotary Positional Encoding (HoPE), which leverages hyperbolic functions to implement Lorentz rotations on token representations. Theoretical analysis demonstrates that RoPE is a special case of our generalized formulation. HoPE fundamentally resolves RoPE's slation issues by enforcing monotonic decay of attention weights with increasing token distances. Extensive experimental results, including perplexity evaluations under several extended sequence benchmarks, show that HoPE consistently exceeds existing positional encoding methods. These findings underscore HoPE's enhanced capacity for representing and generalizing long-range dependencies. Data and code will be available.
Not All Parameters Are Created Equal: Smart Isolation Boosts Fine-Tuning Performance
Aug 29, 2025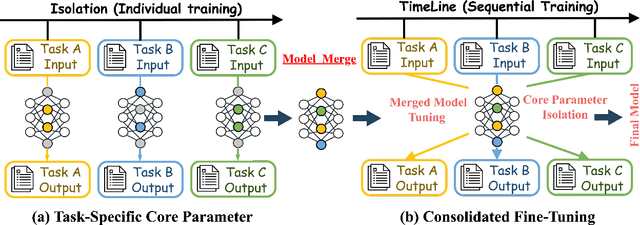
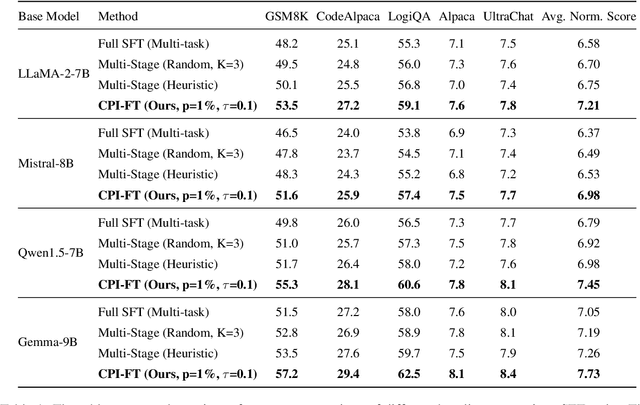

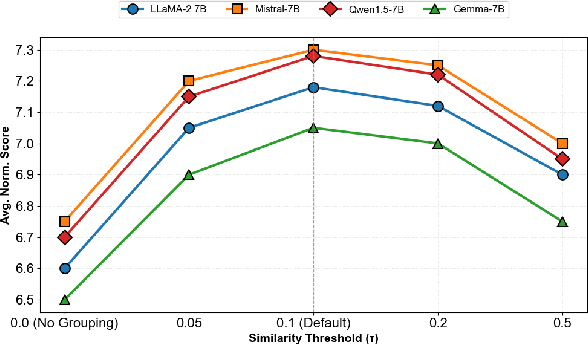
Supervised fine-tuning (SFT) is a pivotal approach to adapting large language models (LLMs) for downstream tasks; however, performance often suffers from the ``seesaw phenomenon'', where indiscriminate parameter updates yield progress on certain tasks at the expense of others. To address this challenge, we propose a novel \emph{Core Parameter Isolation Fine-Tuning} (CPI-FT) framework. Specifically, we first independently fine-tune the LLM on each task to identify its core parameter regions by quantifying parameter update magnitudes. Tasks with similar core regions are then grouped based on region overlap, forming clusters for joint modeling. We further introduce a parameter fusion technique: for each task, core parameters from its individually fine-tuned model are directly transplanted into a unified backbone, while non-core parameters from different tasks are smoothly integrated via Spherical Linear Interpolation (SLERP), mitigating destructive interference. A lightweight, pipelined SFT training phase using mixed-task data is subsequently employed, while freezing core regions from prior tasks to prevent catastrophic forgetting. Extensive experiments on multiple public benchmarks demonstrate that our approach significantly alleviates task interference and forgetting, consistently outperforming vanilla multi-task and multi-stage fine-tuning baselines.
Progressive Mastery: Customized Curriculum Learning with Guided Prompting for Mathematical Reasoning
Jun 04, 2025Large Language Models (LLMs) have achieved remarkable performance across various reasoning tasks, yet post-training is constrained by inefficient sample utilization and inflexible difficulty samples processing. To address these limitations, we propose Customized Curriculum Learning (CCL), a novel framework with two key innovations. First, we introduce model-adaptive difficulty definition that customizes curriculum datasets based on each model's individual capabilities rather than using predefined difficulty metrics. Second, we develop "Guided Prompting," which dynamically reduces sample difficulty through strategic hints, enabling effective utilization of challenging samples that would otherwise degrade performance. Comprehensive experiments on supervised fine-tuning and reinforcement learning demonstrate that CCL significantly outperforms uniform training approaches across five mathematical reasoning benchmarks, confirming its effectiveness across both paradigms in enhancing sample utilization and model performance.
Comateformer: Combined Attention Transformer for Semantic Sentence Matching
Dec 10, 2024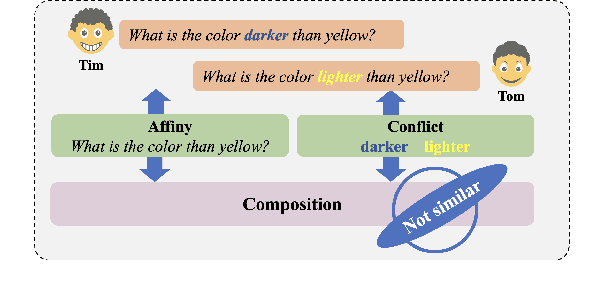



The Transformer-based model have made significant strides in semantic matching tasks by capturing connections between phrase pairs. However, to assess the relevance of sentence pairs, it is insufficient to just examine the general similarity between the sentences. It is crucial to also consider the tiny subtleties that differentiate them from each other. Regrettably, attention softmax operations in transformers tend to miss these subtle differences. To this end, in this work, we propose a novel semantic sentence matching model named Combined Attention Network based on Transformer model (Comateformer). In Comateformer model, we design a novel transformer-based quasi-attention mechanism with compositional properties. Unlike traditional attention mechanisms that merely adjust the weights of input tokens, our proposed method learns how to combine, subtract, or resize specific vectors when building a representation. Moreover, our proposed approach builds on the intuition of similarity and dissimilarity (negative affinity) when calculating dual affinity scores. This allows for a more meaningful representation of relationships between sentences. To evaluate the performance of our proposed model, we conducted extensive experiments on ten public real-world datasets and robustness testing. Experimental results show that our method achieves consistent improvements.
LS-EEND: Long-Form Streaming End-to-End Neural Diarization with Online Attractor Extraction
Oct 09, 2024



This work proposes a frame-wise online/streaming end-to-end neural diarization (EEND) method, which detects speaker activities in a frame-in-frame-out fashion. The proposed model mainly consists of a causal embedding encoder and an online attractor decoder. Speakers are modeled in the self-attention-based decoder along both the time and speaker dimensions, and frame-wise speaker attractors are automatically generated and updated for new speakers and existing speakers, respectively. Retention mechanism is employed and especially adapted for long-form diarization with a linear temporal complexity. A multi-step progressive training strategy is proposed for gradually learning from easy tasks to hard tasks in terms of the number of speakers and audio length. Finally, the proposed model (referred to as long-form streaming EEND, LS-EEND) is able to perform streaming diarization for a high (up to 8) and flexible number speakers and very long (say one hour) audio recordings. Experiments on various simulated and real-world datasets show that: 1) when not using oracle speech activity information, the proposed model achieves new state-of-the-art online diarization error rate on all datasets, including CALLHOME (12.11%), DIHARD II (27.58%), DIHARD III (19.61%), and AMI (20.76%); 2) Due to the frame-in-frame-out processing fashion and the linear temporal complexity, the proposed model achieves several times lower real-time-factor than comparison online diarization models.
TableBench: A Comprehensive and Complex Benchmark for Table Question Answering
Aug 17, 2024
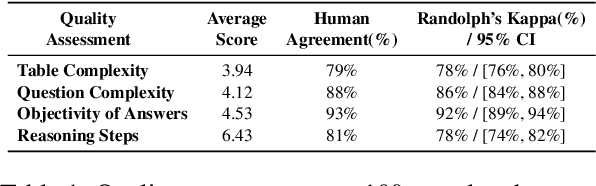
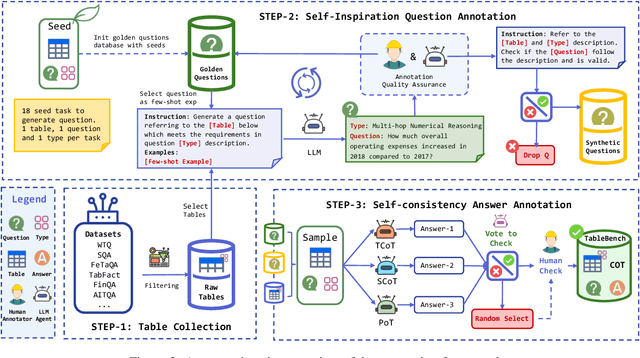
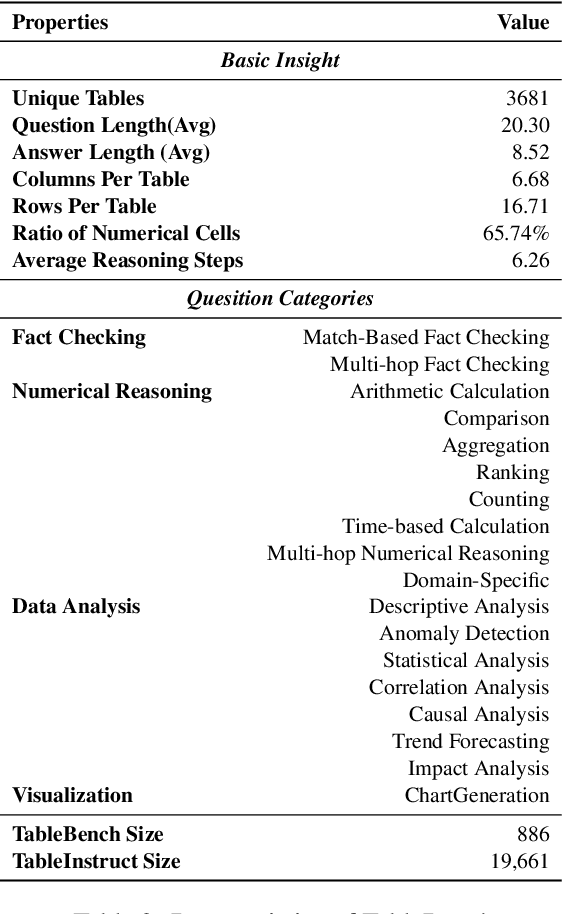
Recent advancements in Large Language Models (LLMs) have markedly enhanced the interpretation and processing of tabular data, introducing previously unimaginable capabilities. Despite these achievements, LLMs still encounter significant challenges when applied in industrial scenarios, particularly due to the increased complexity of reasoning required with real-world tabular data, underscoring a notable disparity between academic benchmarks and practical applications. To address this discrepancy, we conduct a detailed investigation into the application of tabular data in industrial scenarios and propose a comprehensive and complex benchmark TableBench, including 18 fields within four major categories of table question answering (TableQA) capabilities. Furthermore, we introduce TableLLM, trained on our meticulously constructed training set TableInstruct, achieving comparable performance with GPT-3.5. Massive experiments conducted on TableBench indicate that both open-source and proprietary LLMs still have significant room for improvement to meet real-world demands, where the most advanced model, GPT-4, achieves only a modest score compared to humans.
Resolving Word Vagueness with Scenario-guided Adapter for Natural Language Inference
May 21, 2024


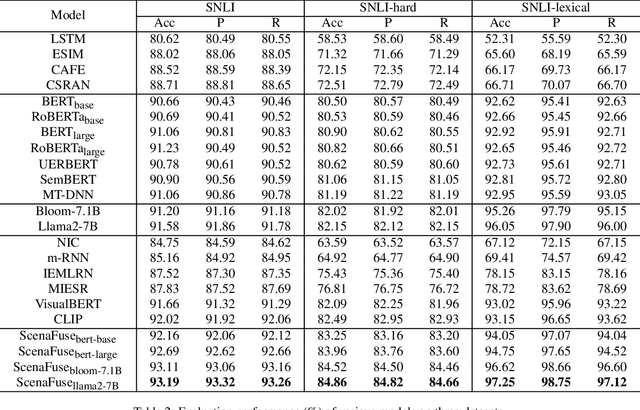
Natural Language Inference (NLI) is a crucial task in natural language processing that involves determining the relationship between two sentences, typically referred to as the premise and the hypothesis. However, traditional NLI models solely rely on the semantic information inherent in independent sentences and lack relevant situational visual information, which can hinder a complete understanding of the intended meaning of the sentences due to the ambiguity and vagueness of language. To address this challenge, we propose an innovative ScenaFuse adapter that simultaneously integrates large-scale pre-trained linguistic knowledge and relevant visual information for NLI tasks. Specifically, we first design an image-sentence interaction module to incorporate visuals into the attention mechanism of the pre-trained model, allowing the two modalities to interact comprehensively. Furthermore, we introduce an image-sentence fusion module that can adaptively integrate visual information from images and semantic information from sentences. By incorporating relevant visual information and leveraging linguistic knowledge, our approach bridges the gap between language and vision, leading to improved understanding and inference capabilities in NLI tasks. Extensive benchmark experiments demonstrate that our proposed ScenaFuse, a scenario-guided approach, consistently boosts NLI performance.