 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstaDrive: Instance-Aware Driving World Models for Realistic and Consistent Video Generation
Feb 03, 2026Autonomous driving relies on robust models trained on high-quality, large-scale multi-view driving videos. While world models offer a cost-effective solution for generating realistic driving videos, they struggle to maintain instance-level temporal consistency and spatial geometric fidelity. To address these challenges, we propose InstaDrive, a novel framework that enhances driving video realism through two key advancements: (1) Instance Flow Guider, which extracts and propagates instance features across frames to enforce temporal consistency, preserving instance identity over time. (2) Spatial Geometric Aligner, which improves spatial reasoning, ensures precise instance positioning, and explicitly models occlusion hierarchies. By incorporating these instance-aware mechanisms, InstaDrive achieves state-of-the-art video generation quality and enhances downstream autonomous driving tasks on the nuScenes dataset. Additionally, we utilize CARLA's autopilot to procedurally and stochastically simulate rare but safety-critical driving scenarios across diverse maps and regions, enabling rigorous safety evaluation for autonomous systems. Our project page is https://shanpoyang654.github.io/InstaDrive/page.html.
A Pragmatic VLA Foundation Model
Jan 26, 2026Offering great potential in robotic manipulation, a capable Vision-Language-Action (VLA) foundation model is expected to faithfully generalize across tasks and platforms while ensuring cost efficiency (e.g., data and GPU hours required for adaptation). To this end, we develop LingBot-VLA with around 20,000 hours of real-world data from 9 popular dual-arm robot configurations. Through a systematic assessment on 3 robotic platforms, each completing 100 tasks with 130 post-training episodes per task, our model achieves clear superiority over competitors, showcasing its strong performance and broad generalizability. We have also built an efficient codebase, which delivers a throughput of 261 samples per second per GPU with an 8-GPU training setup, representing a 1.5~2.8$\times$ (depending on the relied VLM base model) speedup over existing VLA-oriented codebases. The above features ensure that our model is well-suited for real-world deployment. To advance the field of robot learning, we provide open access to the code, base model, and benchmark data, with a focus on enabling more challenging tasks and promoting sound evaluation standards.
Text as a Universal Interface for Transferable Personalization
Jan 08, 2026We study the problem of personalization in large language models (LLMs). Prior work predominantly represents user preferences as implicit, model-specific vectors or parameters, yielding opaque ``black-box'' profiles that are difficult to interpret and transfer across models and tasks. In contrast, we advocate natural language as a universal, model- and task-agnostic interface for preference representation. The formulation leads to interpretable and reusable preference descriptions, while naturally supporting continual evolution as new interactions are observed. To learn such representations, we introduce a two-stage training framework that combines supervised fine-tuning on high-quality synthesized data with reinforcement learning to optimize long-term utility and cross-task transferability. Based on this framework, we develop AlignXplore+, a universal preference reasoning model that generates textual preference summaries. Experiments on nine benchmarks show that our 8B model achieves state-of-the-art performanc -- outperforming substantially larger open-source models -- while exhibiting strong transferability across tasks, model families, and interaction formats.
Anti-Length Shift: Dynamic Outlier Truncation for Training Efficient Reasoning Models
Jan 07, 2026Large reasoning models enhanced by reinforcement learning with verifiable rewards have achieved significant performance gains by extending their chain-of-thought. However, this paradigm incurs substantial deployment costs as models often exhibit excessive verbosity on simple queries. Existing efficient reasoning methods relying on explicit length penalties often introduce optimization conflicts and leave the generative mechanisms driving overthinking largely unexamined. In this paper, we identify a phenomenon termed length shift where models increasingly generate unnecessary reasoning on trivial inputs during training. To address this, we introduce Dynamic Outlier Truncation (DOT), a training-time intervention that selectively suppresses redundant tokens. This method targets only the extreme tail of response lengths within fully correct rollout groups while preserving long-horizon reasoning capabilities for complex problems. To complement this intervention and ensure stable convergence, we further incorporate auxiliary KL regularization and predictive dynamic sampling. Experimental results across multiple model scales demonstrate that our approach significantly pushes the efficiency-performance Pareto frontier outward. Notably, on the AIME-24, our method reduces inference token usage by 78% while simultaneously increasing accuracy compared to the initial policy and surpassing state-of-the-art efficient reasoning methods.
Universal Battery Degradation Forecasting Driven by Foundation Model Across Diverse Chemistries and Conditions
Dec 30, 2025Accurate forecasting of battery capacity fade is essential for the safety, reliability, and long-term efficiency of energy storage systems. However, the strong heterogeneity across cell chemistries, form factors, and operating conditions makes it difficult to build a single model that generalizes beyond its training domain. This work proposes a unified capacity forecasting framework that maintains robust performance across diverse chemistries and usage scenarios. We curate 20 public aging datasets into a large-scale corpus covering 1,704 cells and 3,961,195 charge-discharge cycle segments, spanning temperatures from $-5\,^{\circ}\mathrm{C}$ to $45\,^{\circ}\mathrm{C}$, multiple C-rates, and application-oriented profiles such as fast charging and partial cycling. On this corpus, we adopt a Time-Series Foundation Model (TSFM) backbone and apply parameter-efficient Low-Rank Adaptation (LoRA) together with physics-guided contrastive representation learning to capture shared degradation patterns. Experiments on both seen and deliberately held-out unseen datasets show that a single unified model achieves competitive or superior accuracy compared with strong per-dataset baselines, while retaining stable performance on chemistries, capacity scales, and operating conditions excluded from training. These results demonstrate the potential of TSFM-based architectures as a scalable and transferable solution for capacity degradation forecasting in real battery management systems.
Aerial World Model for Long-horizon Visual Generation and Navigation in 3D Space
Dec 26, 2025Unmanned aerial vehicles (UAVs) have emerged as powerful embodied agents. One of the core abilities is autonomous navigation in large-scale three-dimensional environments. Existing navigation policies, however, are typically optimized for low-level objectives such as obstacle avoidance and trajectory smoothness, lacking the ability to incorporate high-level semantics into planning. To bridge this gap, we propose ANWM, an aerial navigation world model that predicts future visual observations conditioned on past frames and actions, thereby enabling agents to rank candidate trajectories by their semantic plausibility and navigational utility. ANWM is trained on 4-DoF UAV trajectories and introduces a physics-inspired module: Future Frame Projection (FFP), which projects past frames into future viewpoints to provide coarse geometric priors. This module mitigates representational uncertainty in long-distance visual generation and captures the mapping between 3D trajectories and egocentric observations. Empirical results demonstrate that ANWM significantly outperforms existing world models in long-distance visual forecasting and improves UAV navigation success rates in large-scale environments.
Knowledge-Driven 3D Semantic Spectrum Map: KE-VQ-Transformer Based UAV Semantic Communication and Map Completion
Dec 24, 2025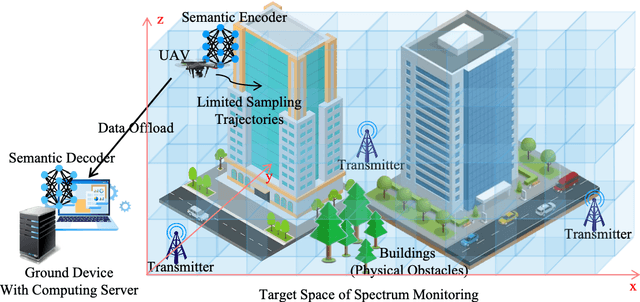
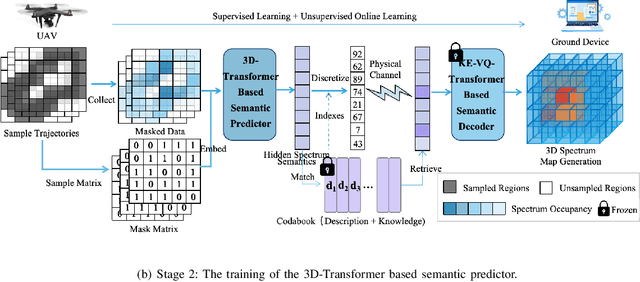
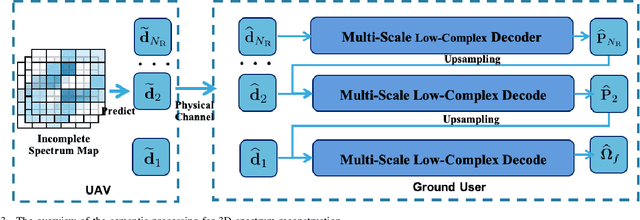
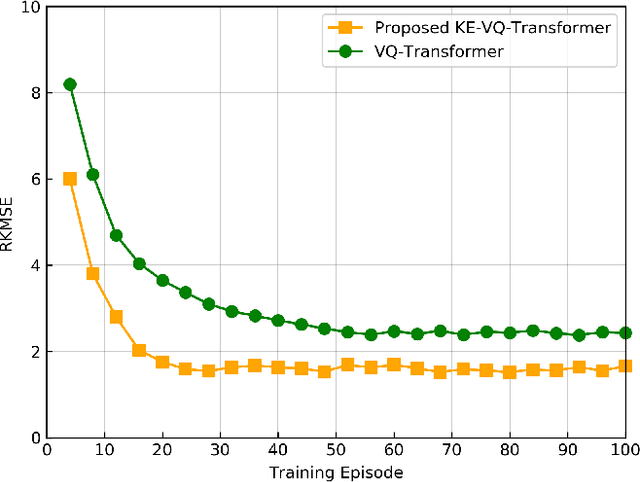
Artificial intelligence (AI)-native three-dimensional (3D) spectrum maps are crucial in spectrum monitoring for intelligent communication networks. However, it is challenging to obtain and transmit 3D spectrum maps in a spectrum-efficient, computation-efficient, and AI-driven manner, especially under complex communication environments and sparse sampling data. In this paper, we consider practical air-to-ground semantic communications for spectrum map completion, where the unmanned aerial vehicle (UAV) measures the spectrum at spatial points and extracts the spectrum semantics, which are then utilized to complete spectrum maps at the ground device. Since statistical machine learning can easily be misled by superficial data correlations with the lack of interpretability, we propose a novel knowledge-enhanced semantic spectrum map completion framework with two expert knowledge-driven constraints from physical signal propagation models. This framework can capture the real-world physics and avoid getting stuck in the mindset of superficial data distributions. Furthermore, a knowledge-enhanced vector-quantized Transformer (KE-VQ-Transformer) based multi-scale low-complex intelligent completion approach is proposed, where the sparse window is applied to avoid ultra-large 3D attention computation, and the multi-scale design improves the completion performance. The knowledge-enhanced mean square error (KMSE) and root KMSE (RKMSE) are introduced as novel metrics for semantic spectrum map completion that jointly consider the numerical precision and physical consistency with the signal propagation model, based on which a joint offline and online training method is developed with supervised and unsupervised knowledge loss. The simulation demonstrates that our proposed scheme outperforms the state-of-the-art benchmark schemes in terms of RKMSE.
ReFusion: A Diffusion Large Language Model with Parallel Autoregressive Decoding
Dec 15, 2025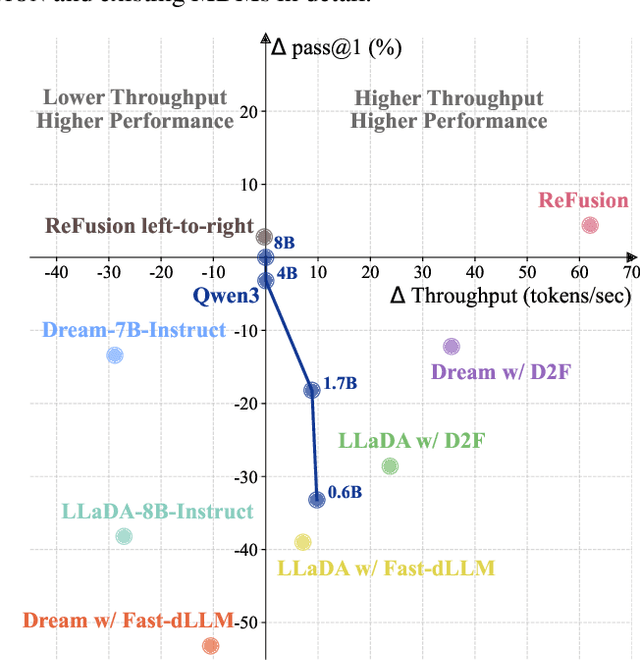
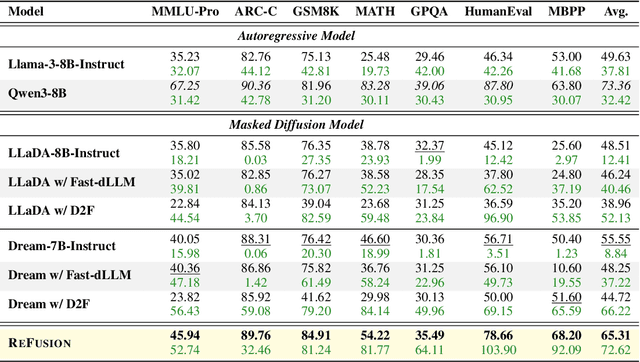
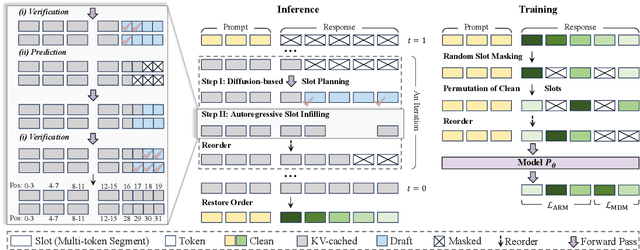
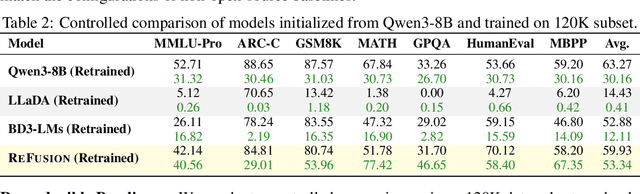
Autoregressive models (ARMs) are hindered by slow sequential inference. While masked diffusion models (MDMs) offer a parallel alternative, they suffer from critical drawbacks: high computational overhead from precluding Key-Value (KV) caching, and incoherent generation arising from learning dependencies over an intractable space of token combinations. To address these limitations, we introduce ReFusion, a novel masked diffusion model that achieves superior performance and efficiency by elevating parallel decoding from the token level to a higher slot level, where each slot is a fixed-length, contiguous sub-sequence. This is achieved through an iterative ``plan-and-infill'' decoding process: a diffusion-based planning step first identifies a set of weakly dependent slots, and an autoregressive infilling step then decodes these selected slots in parallel. The slot-based design simultaneously unlocks full KV cache reuse with a unified causal framework and reduces the learning complexity from the token combination space to a manageable slot-level permutation space. Extensive experiments on seven diverse benchmarks show that ReFusion not only overwhelmingly surpasses prior MDMs with 34% performance gains and an over 18$\times$ speedup on average, but also bridges the performance gap to strong ARMs while maintaining a 2.33$\times$ average speedup.
AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress
Nov 11, 2025Despite rapid development, large language models (LLMs) still encounter challenges in multi-turn decision-making tasks (i.e., agent tasks) like web shopping and browser navigation, which require making a sequence of intelligent decisions based on environmental feedback. Previous work for LLM agents typically relies on elaborate prompt engineering or fine-tuning with expert trajectories to improve performance. In this work, we take a different perspective: we explore constructing process reward models (PRMs) to evaluate each decision and guide the agent's decision-making process. Unlike LLM reasoning, where each step is scored based on correctness, actions in agent tasks do not have a clear-cut correctness. Instead, they should be evaluated based on their proximity to the goal and the progress they have made. Building on this insight, we propose a re-defined PRM for agent tasks, named AgentPRM, to capture both the interdependence between sequential decisions and their contribution to the final goal. This enables better progress tracking and exploration-exploitation balance. To scalably obtain labeled data for training AgentPRM, we employ a Temporal Difference-based (TD-based) estimation method combined with Generalized Advantage Estimation (GAE), which proves more sample-efficient than prior methods. Extensive experiments across different agentic tasks show that AgentPRM is over $8\times$ more compute-efficient than baselines, and it demonstrates robust improvement when scaling up test-time compute. Moreover, we perform detailed analyses to show how our method works and offer more insights, e.g., applying AgentPRM to the reinforcement learning of LLM agents.
DynaAct: Large Language Model Reasoning with Dynamic Action Spaces
Nov 11, 2025In modern sequential decision-making systems, the construction of an optimal candidate action space is critical to efficient inference. However, existing approaches either rely on manually defined action spaces that lack scalability or utilize unstructured spaces that render exhaustive search computationally prohibitive. In this paper, we propose a novel framework named \textsc{DynaAct} for automatically constructing a compact action space to enhance sequential reasoning in complex problem-solving scenarios. Our method first estimates a proxy for the complete action space by extracting general sketches observed in a corpus covering diverse complex reasoning problems using large language models. We then formulate a submodular function that jointly evaluates candidate actions based on their utility to the current state and their diversity, and employ a greedy algorithm to select an optimal candidate set. Extensive experiments on six diverse standard benchmarks demonstrate that our approach significantly improves overall performance, while maintaining efficient inference without introducing substantial latency. The implementation is available at https://github.com/zhaoxlpku/DynaAct.