 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning bounds for doubly-robust covariate shift adaptation
Nov 14, 2025Distribution shift between the training domain and the test domain poses a key challenge for modern machine learning. An extensively studied instance is the \emph{covariate shift}, where the marginal distribution of covariates differs across domains, while the conditional distribution of outcome remains the same. The doubly-robust (DR) estimator, recently introduced by \cite{kato2023double}, combines the density ratio estimation with a pilot regression model and demonstrates asymptotic normality and $\sqrt{n}$-consistency, even when the pilot estimates converge slowly. However, the prior arts has focused exclusively on deriving asymptotic results and has left open the question of non-asymptotic guarantees for the DR estimator. This paper establishes the first non-asymptotic learning bounds for the DR covariate shift adaptation. Our main contributions are two-fold: (\romannumeral 1) We establish \emph{structure-agnostic} high-probability upper bounds on the excess target risk of the DR estimator that depend only on the $L^2$-errors of the pilot estimates and the Rademacher complexity of the model class, without assuming specific procedures to obtain the pilot estimate, and (\romannumeral 2) under \emph{well-specified parameterized models}, we analyze the DR covariate shift adaptation based on modern techniques for non-asymptotic analysis of MLE, whose key terms governed by the Fisher information mismatch term between the source and target distributions. Together, these findings bridge asymptotic efficiency properties and a finite-sample out-of-distribution generalization bounds, providing a comprehensive theoretical underpinnings for the DR covariate shift adaptation.
The Adaptivity Barrier in Batched Nonparametric Bandits: Sharp Characterization of the Price of Unknown Margin
Nov 05, 2025We study batched nonparametric contextual bandits under a margin condition when the margin parameter $\alpha$ is unknown. To capture the statistical price of this ignorance, we introduce the regret inflation criterion, defined as the ratio between the regret of an adaptive algorithm and that of an oracle knowing $\alpha$. We show that the optimal regret inflation grows polynomial with the horizon $T$, with exponent precisely given by the value of a convex optimization problem involving the dimension, smoothness, and batch budget. Moreover, the minimizers of this optimization problem directly prescribe the batch allocation and exploration strategy of a rate-optimal algorithm. Building on this principle, we develop RoBIN (RObust batched algorithm with adaptive BINning), which achieves the optimal regret inflation up to logarithmic factors. These results reveal a new adaptivity barrier: under batching, adaptation to an unknown margin parameter inevitably incurs a polynomial penalty, sharply characterized by a variational problem. Remarkably, this barrier vanishes when the number of batches exceeds $\log \log T$; with only a doubly logarithmic number of updates, one can recover the oracle regret rate up to polylogarithmic factors.
Rethinking the long-range dependency in Mamba/SSM and transformer models
Sep 04, 2025Long-range dependency is one of the most desired properties of recent sequence models such as state-space models (particularly Mamba) and transformer models. New model architectures are being actively developed and benchmarked for prediction tasks requiring long-range dependency. However, the capability of modeling long-range dependencies of these models has not been investigated from a theoretical perspective, which hinders a systematic improvement on this aspect. In this work, we mathematically define long-range dependency using the derivative of hidden states with respect to past inputs and compare the capability of SSM and transformer models of modeling long-range dependency based on this definition. We showed that the long-range dependency of SSM decays exponentially with the sequence length, which aligns with the exponential decay of memory function in RNN. But the attention mechanism used in transformers is more flexible and is not constrained to exponential decay, which could in theory perform better at modeling long-range dependency with sufficient training data, computing resources, and proper training. To combine the flexibility of long-range dependency of attention mechanism and computation efficiency of SSM, we propose a new formulation for hidden state update in SSM and prove its stability under a standard Gaussian distribution of the input data.
Multi-modal contrastive learning adapts to intrinsic dimensions of shared latent variables
May 18, 2025Multi-modal contrastive learning as a self-supervised representation learning technique has achieved great success in foundation model training, such as CLIP~\citep{radford2021learning}. In this paper, we study the theoretical properties of the learned representations from multi-modal contrastive learning beyond linear representations and specific data distributions. Our analysis reveals that, enabled by temperature optimization, multi-modal contrastive learning not only maximizes mutual information between modalities but also adapts to intrinsic dimensions of data, which can be much lower than user-specified dimensions for representation vectors. Experiments on both synthetic and real-world datasets demonstrate the ability of contrastive learning to learn low-dimensional and informative representations, bridging theoretical insights and practical performance.
Auditing Differential Privacy in the Black-Box Setting
Mar 15, 2025This paper introduces a novel theoretical framework for auditing differential privacy (DP) in a black-box setting. Leveraging the concept of $f$-differential privacy, we explicitly define type I and type II errors and propose an auditing mechanism based on conformal inference. Our approach robustly controls the type I error rate under minimal assumptions. Furthermore, we establish a fundamental impossibility result, demonstrating the inherent difficulty of simultaneously controlling both type I and type II errors without additional assumptions. Nevertheless, under a monotone likelihood ratio (MLR) assumption, our auditing mechanism effectively controls both errors. We also extend our method to construct valid confidence bands for the trade-off function in the finite-sample regime.
UniMamba: Unified Spatial-Channel Representation Learning with Group-Efficient Mamba for LiDAR-based 3D Object Detection
Mar 15, 2025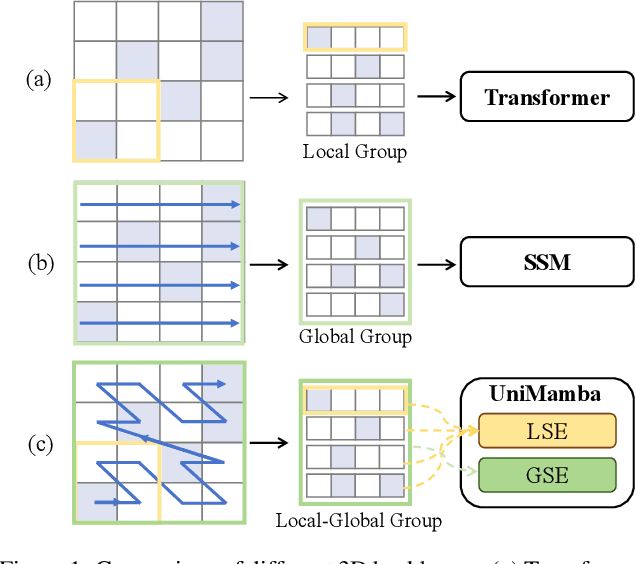
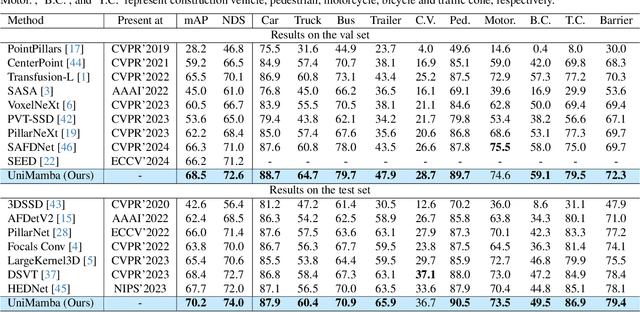
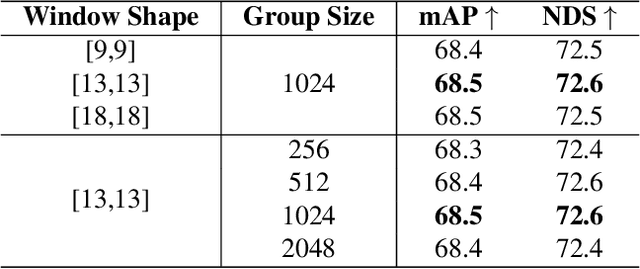
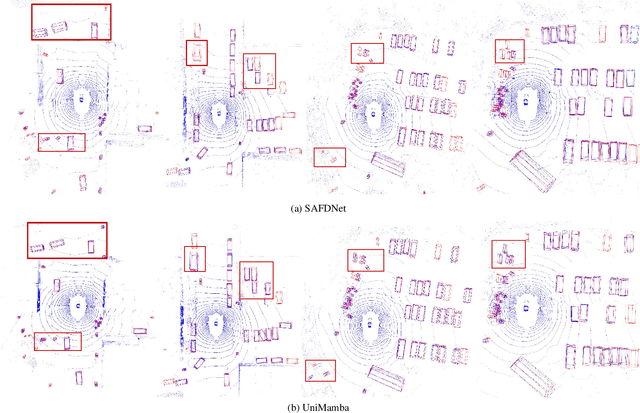
Recent advances in LiDAR 3D detection have demonstrated the effectiveness of Transformer-based frameworks in capturing the global dependencies from point cloud spaces, which serialize the 3D voxels into the flattened 1D sequence for iterative self-attention. However, the spatial structure of 3D voxels will be inevitably destroyed during the serialization process. Besides, due to the considerable number of 3D voxels and quadratic complexity of Transformers, multiple sequences are grouped before feeding to Transformers, leading to a limited receptive field. Inspired by the impressive performance of State Space Models (SSM) achieved in the field of 2D vision tasks, in this paper, we propose a novel Unified Mamba (UniMamba), which seamlessly integrates the merits of 3D convolution and SSM in a concise multi-head manner, aiming to perform "local and global" spatial context aggregation efficiently and simultaneously. Specifically, a UniMamba block is designed which mainly consists of spatial locality modeling, complementary Z-order serialization and local-global sequential aggregator. The spatial locality modeling module integrates 3D submanifold convolution to capture the dynamic spatial position embedding before serialization. Then the efficient Z-order curve is adopted for serialization both horizontally and vertically. Furthermore, the local-global sequential aggregator adopts the channel grouping strategy to efficiently encode both "local and global" spatial inter-dependencies using multi-head SSM. Additionally, an encoder-decoder architecture with stacked UniMamba blocks is formed to facilitate multi-scale spatial learning hierarchically. Extensive experiments are conducted on three popular datasets: nuScenes, Waymo and Argoverse 2. Particularly, our UniMamba achieves 70.2 mAP on the nuScenes dataset.
Estimating shared subspace with AJIVE: the power and limitation of multiple data matrices
Jan 16, 2025Integrative data analysis often requires disentangling joint and individual variations across multiple datasets, a challenge commonly addressed by the Joint and Individual Variation Explained (JIVE) model. While numerous methods have been developed to estimate the shared subspace under JIVE, the theoretical understanding of their performance remains limited, particularly in the context of multiple matrices and varying levels of subspace misalignment. This paper bridges this gap by providing a systematic analysis of shared subspace estimation in multi-matrix settings. We focus on the Angle-based Joint and Individual Variation Explained (AJIVE) method, a two-stage spectral approach, and establish new performance guarantees that uncover its strengths and limitations. Specifically, we show that in high signal-to-noise ratio (SNR) regimes, AJIVE's estimation error decreases with the number of matrices, demonstrating the power of multi-matrix integration. Conversely, in low-SNR settings, AJIVE exhibits a non-diminishing error, highlighting fundamental limitations. To complement these results, we derive minimax lower bounds, showing that AJIVE achieves optimal rates in high-SNR regimes. Furthermore, we analyze an oracle-aided spectral estimator to demonstrate that the non-diminishing error in low-SNR scenarios is a fundamental barrier. Extensive numerical experiments corroborate our theoretical findings, providing insights into the interplay between SNR, matrix count, and subspace misalignment.
Trans-Glasso: A Transfer Learning Approach to Precision Matrix Estimation
Nov 23, 2024Precision matrix estimation is essential in various fields, yet it is challenging when samples for the target study are limited. Transfer learning can enhance estimation accuracy by leveraging data from related source studies. We propose Trans-Glasso, a two-step transfer learning method for precision matrix estimation. First, we obtain initial estimators using a multi-task learning objective that captures shared and unique features across studies. Then, we refine these estimators through differential network estimation to adjust for structural differences between the target and source precision matrices. Under the assumption that most entries of the target precision matrix are shared with source matrices, we derive non-asymptotic error bounds and show that Trans-Glasso achieves minimax optimality under certain conditions. Extensive simulations demonstrate Trans Glasso's superior performance compared to baseline methods, particularly in small-sample settings. We further validate Trans-Glasso in applications to gene networks across brain tissues and protein networks for various cancer subtypes, showcasing its effectiveness in biological contexts. Additionally, we derive the minimax optimal rate for differential network estimation, representing the first such guarantee in this area.
Off-policy estimation with adaptively collected data: the power of online learning
Nov 19, 2024We consider estimation of a linear functional of the treatment effect using adaptively collected data. This task finds a variety of applications including the off-policy evaluation (\textsf{OPE}) in contextual bandits, and estimation of the average treatment effect (\textsf{ATE}) in causal inference. While a certain class of augmented inverse propensity weighting (\textsf{AIPW}) estimators enjoys desirable asymptotic properties including the semi-parametric efficiency, much less is known about their non-asymptotic theory with adaptively collected data. To fill in the gap, we first establish generic upper bounds on the mean-squared error of the class of AIPW estimators that crucially depends on a sequentially weighted error between the treatment effect and its estimates. Motivated by this, we also propose a general reduction scheme that allows one to produce a sequence of estimates for the treatment effect via online learning to minimize the sequentially weighted estimation error. To illustrate this, we provide three concrete instantiations in (\romannumeral 1) the tabular case; (\romannumeral 2) the case of linear function approximation; and (\romannumeral 3) the case of general function approximation for the outcome model. We then provide a local minimax lower bound to show the instance-dependent optimality of the \textsf{AIPW} estimator using no-regret online learning algorithms.
RoboSense: Large-scale Dataset and Benchmark for Multi-sensor Low-speed Autonomous Driving
Aug 28, 2024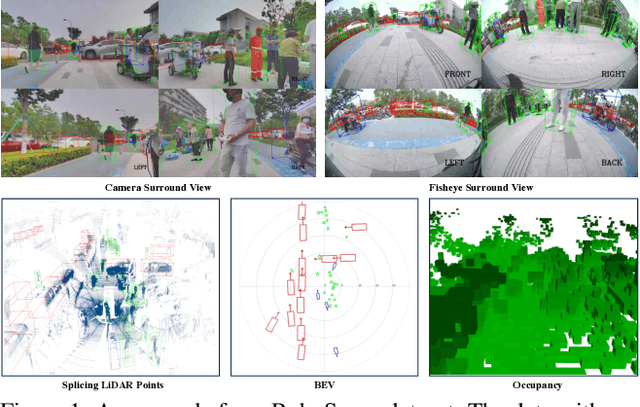
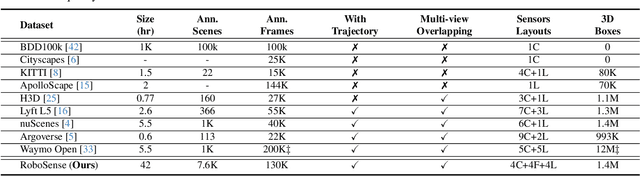
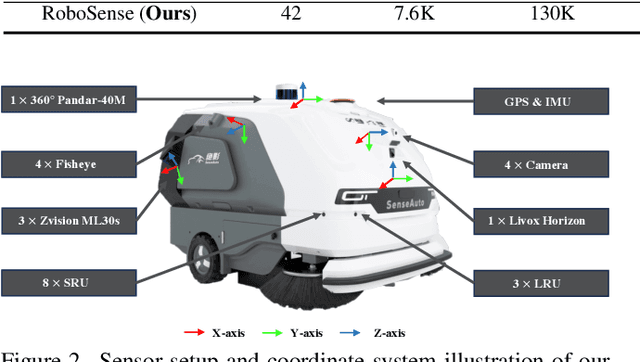
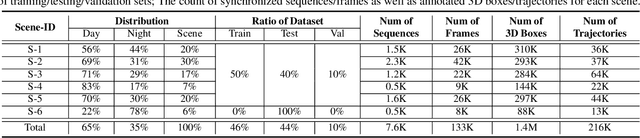
Robust object detection and tracking under arbitrary sight of view is challenging yet essential for the development of Autonomous Vehicle technology. With the growing demand of unmanned function vehicles, near-field scene understanding becomes an important research topic in the areas of low-speed autonomous driving. Due to the complexity of driving conditions and diversity of near obstacles such as blind spots and high occlusion, the perception capability of near-field environment is still inferior than its farther counterpart. To further enhance the intelligent ability of unmanned vehicles, in this paper, we construct a multimodal data collection platform based on 3 main types of sensors (Camera, LiDAR and Fisheye), which supports flexible sensor configurations to enable dynamic sight of view for ego vehicle, either global view or local view. Meanwhile, a large-scale multi-sensor dataset is built, named RoboSense, to facilitate near-field scene understanding. RoboSense contains more than 133K synchronized data with 1.4M 3D bounding box and IDs annotated in the full $360^{\circ}$ view, forming 216K trajectories across 7.6K temporal sequences. It has $270\times$ and $18\times$ as many annotations of near-field obstacles within 5$m$ as the previous single-vehicle datasets such as KITTI and nuScenes. Moreover, we define a novel matching criterion for near-field 3D perception and prediction metrics. Based on RoboSense, we formulate 6 popular tasks to facilitate the future development of related research, where the detailed data analysis as well as benchmarks are also provided accordingly.