 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning bounds for doubly-robust covariate shift adaptation
Nov 14, 2025Distribution shift between the training domain and the test domain poses a key challenge for modern machine learning. An extensively studied instance is the \emph{covariate shift}, where the marginal distribution of covariates differs across domains, while the conditional distribution of outcome remains the same. The doubly-robust (DR) estimator, recently introduced by \cite{kato2023double}, combines the density ratio estimation with a pilot regression model and demonstrates asymptotic normality and $\sqrt{n}$-consistency, even when the pilot estimates converge slowly. However, the prior arts has focused exclusively on deriving asymptotic results and has left open the question of non-asymptotic guarantees for the DR estimator. This paper establishes the first non-asymptotic learning bounds for the DR covariate shift adaptation. Our main contributions are two-fold: (\romannumeral 1) We establish \emph{structure-agnostic} high-probability upper bounds on the excess target risk of the DR estimator that depend only on the $L^2$-errors of the pilot estimates and the Rademacher complexity of the model class, without assuming specific procedures to obtain the pilot estimate, and (\romannumeral 2) under \emph{well-specified parameterized models}, we analyze the DR covariate shift adaptation based on modern techniques for non-asymptotic analysis of MLE, whose key terms governed by the Fisher information mismatch term between the source and target distributions. Together, these findings bridge asymptotic efficiency properties and a finite-sample out-of-distribution generalization bounds, providing a comprehensive theoretical underpinnings for the DR covariate shift adaptation.
Progressive Weight Loading: Accelerating Initial Inference and Gradually Boosting Performance on Resource-Constrained Environments
Sep 26, 2025Deep learning models have become increasingly large and complex, resulting in higher memory consumption and computational demands. Consequently, model loading times and initial inference latency have increased, posing significant challenges in mobile and latency-sensitive environments where frequent model loading and unloading are required, which directly impacts user experience. While Knowledge Distillation (KD) offers a solution by compressing large teacher models into smaller student ones, it often comes at the cost of reduced performance. To address this trade-off, we propose Progressive Weight Loading (PWL), a novel technique that enables fast initial inference by first deploying a lightweight student model, then incrementally replacing its layers with those of a pre-trained teacher model. To support seamless layer substitution, we introduce a training method that not only aligns intermediate feature representations between student and teacher layers, but also improves the overall output performance of the student model. Our experiments on VGG, ResNet, and ViT architectures demonstrate that models trained with PWL maintain competitive distillation performance and gradually improve accuracy as teacher layers are loaded-matching the final accuracy of the full teacher model without compromising initial inference speed. This makes PWL particularly suited for dynamic, resource-constrained deployments where both responsiveness and performance are critical.
Off-policy estimation with adaptively collected data: the power of online learning
Nov 19, 2024We consider estimation of a linear functional of the treatment effect using adaptively collected data. This task finds a variety of applications including the off-policy evaluation (\textsf{OPE}) in contextual bandits, and estimation of the average treatment effect (\textsf{ATE}) in causal inference. While a certain class of augmented inverse propensity weighting (\textsf{AIPW}) estimators enjoys desirable asymptotic properties including the semi-parametric efficiency, much less is known about their non-asymptotic theory with adaptively collected data. To fill in the gap, we first establish generic upper bounds on the mean-squared error of the class of AIPW estimators that crucially depends on a sequentially weighted error between the treatment effect and its estimates. Motivated by this, we also propose a general reduction scheme that allows one to produce a sequence of estimates for the treatment effect via online learning to minimize the sequentially weighted estimation error. To illustrate this, we provide three concrete instantiations in (\romannumeral 1) the tabular case; (\romannumeral 2) the case of linear function approximation; and (\romannumeral 3) the case of general function approximation for the outcome model. We then provide a local minimax lower bound to show the instance-dependent optimality of the \textsf{AIPW} estimator using no-regret online learning algorithms.
Efficient Terminology Integration for LLM-based Translation in Specialized Domains
Oct 21, 2024Traditional machine translation methods typically involve training models directly on large parallel corpora, with limited emphasis on specialized terminology. However, In specialized fields such as patent, finance, or biomedical domains, terminology is crucial for translation, with many terms that needs to be translated following agreed-upon conventions. In this paper we introduce a methodology that efficiently trains models with a smaller amount of data while preserving the accuracy of terminology translation. We achieve this through a systematic process of term extraction and glossary creation using the Trie Tree algorithm, followed by data reconstruction to teach the LLM how to integrate these specialized terms. This methodology enhances the model's ability to handle specialized terminology and ensures high-quality translations, particularly in fields where term consistency is crucial. Our approach has demonstrated exceptional performance, achieving the highest translation score among participants in the WMT patent task to date, showcasing its effectiveness and broad applicability in specialized translation domains where general methods often fall short.
TelME: Teacher-leading Multimodal Fusion Network for Emotion Recognition in Conversation
Jan 16, 2024
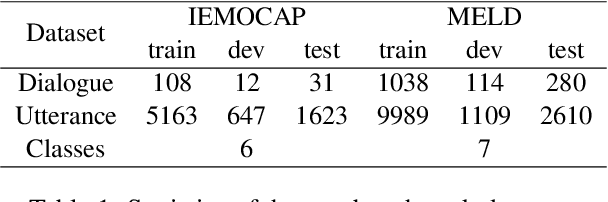
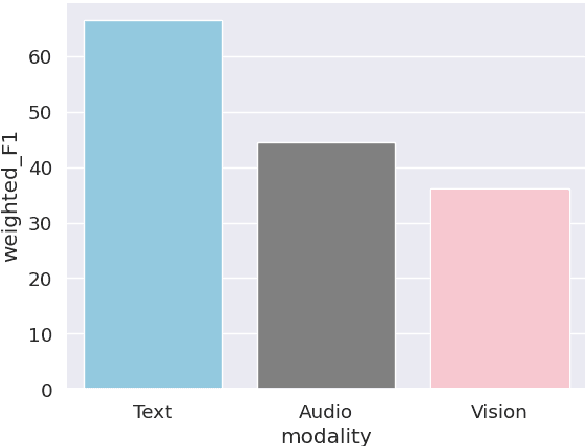
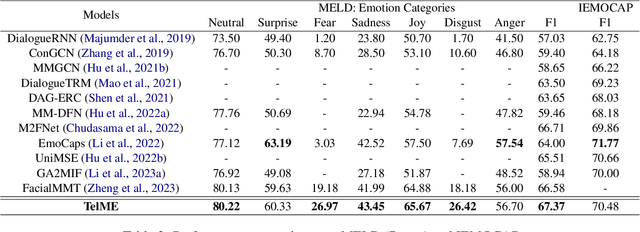
Emotion Recognition in Conversation (ERC) plays a crucial role in enabling dialogue systems to effectively respond to user requests. The emotions in a conversation can be identified by the representations from various modalities, such as audio, visual, and text. However, due to the weak contribution of non-verbal modalities to recognize emotions, multimodal ERC has always been considered a challenging task. In this paper, we propose Teacher-leading Multimodal fusion network for ERC (TelME). TelME incorporates cross-modal knowledge distillation to transfer information from a language model acting as the teacher to the non-verbal students, thereby optimizing the efficacy of the weak modalities. We then combine multimodal features using a shifting fusion approach in which student networks support the teacher. TelME achieves state-of-the-art performance in MELD, a multi-speaker conversation dataset for ERC. Finally, we demonstrate the effectiveness of our components through additional experiments.
Topic Segmentation Model Focusing on Local Context
Jan 05, 2023



Topic segmentation is important in understanding scientific documents since it can not only provide better readability but also facilitate downstream tasks such as information retrieval and question answering by creating appropriate sections or paragraphs. In the topic segmentation task, topic coherence is critical in predicting segmentation boundaries. Most of the existing models have tried to exploit as many contexts as possible to extract useful topic-related information. However, additional context does not always bring promising results, because the local context between sentences becomes incoherent despite more sentences being supplemented. To alleviate this issue, we propose siamese sentence embedding layers which process two input sentences independently to get appropriate amount of information without being hampered by excessive information. Also, we adopt multi-task learning techniques including Same Topic Prediction (STP), Topic Classification (TC) and Next Sentence Prediction (NSP). When these three classification layers are combined in a multi-task manner, they can make up for each other's limitations, improving performance in all three tasks. We experiment different combinations of the three layers and report how each layer affects other layers in the same combination as well as the overall segmentation performance. The model we proposed achieves the state-of-the-art result in the WikiSection dataset.
A Worker-Task Specialization Model for Crowdsourcing: Efficient Inference and Fundamental Limits
Nov 19, 2021

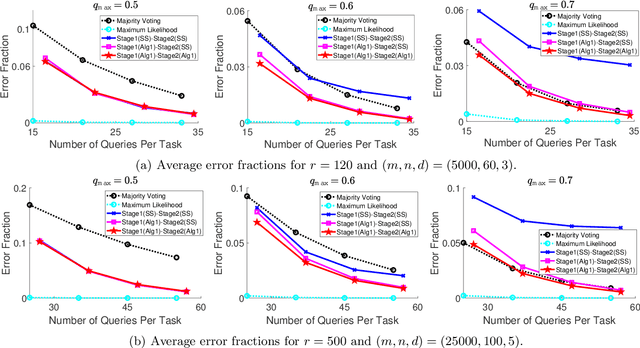

Crowdsourcing system has emerged as an effective platform to label data with relatively low cost by using non-expert workers. However, inferring correct labels from multiple noisy answers on data has been a challenging problem, since the quality of answers varies widely across tasks and workers. Many previous works have assumed a simple model where the order of workers in terms of their reliabilities is fixed across tasks, and focused on estimating the worker reliabilities to aggregate answers with different weights. We propose a highly general $d$-type worker-task specialization model in which the reliability of each worker can change depending on the type of a given task, where the number $d$ of types can scale in the number of tasks. In this model, we characterize the optimal sample complexity to correctly infer labels with any given recovery accuracy, and propose an inference algorithm achieving the order-wise optimal bound. We conduct experiments both on synthetic and real-world datasets, and show that our algorithm outperforms the existing algorithms developed based on strict model assumptions.
Hypergraph Clustering in the Weighted Stochastic Block Model via Convex Relaxation of Truncated MLE
Mar 23, 2020
We study hypergraph clustering under the weighted $d$-uniform hypergraph stochastic block model ($d$-WHSBM), where each edge consisting of $d$ nodes has higher expected weight if $d$ nodes are from the same community compared to edges consisting of nodes from different communities. We propose a new hypergraph clustering algorithm, which is a convex relaxation of truncated maximum likelihood estimator (CRTMLE), that can handle the relatively sparse, high-dimensional regime of the $d$-WHSBM with community sizes of different orders. We provide performance guarantees of this algorithm under a unified framework for different parameter regimes, and show that it achieves the order-wise optimal or the best existing results for approximately balanced community sizes. We also demonstrate the first recovery guarantees for the setting with growing number of communities of unbalanced sizes.