 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Worker-Task Specialization Model for Crowdsourcing: Efficient Inference and Fundamental Limits
Paper and Code
Nov 19, 2021

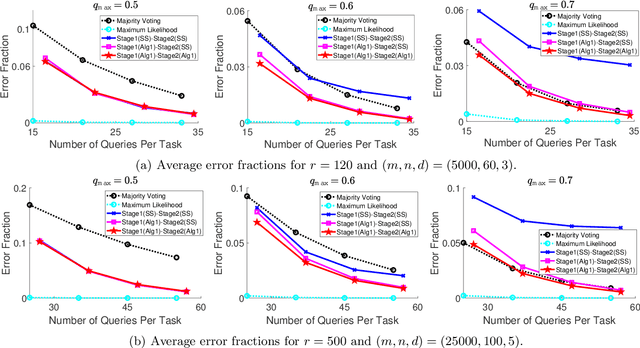

Crowdsourcing system has emerged as an effective platform to label data with relatively low cost by using non-expert workers. However, inferring correct labels from multiple noisy answers on data has been a challenging problem, since the quality of answers varies widely across tasks and workers. Many previous works have assumed a simple model where the order of workers in terms of their reliabilities is fixed across tasks, and focused on estimating the worker reliabilities to aggregate answers with different weights. We propose a highly general $d$-type worker-task specialization model in which the reliability of each worker can change depending on the type of a given task, where the number $d$ of types can scale in the number of tasks. In this model, we characterize the optimal sample complexity to correctly infer labels with any given recovery accuracy, and propose an inference algorithm achieving the order-wise optimal bound. We conduct experiments both on synthetic and real-world datasets, and show that our algorithm outperforms the existing algorithms developed based on strict model assumptions.