 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentCUA: Learning Intent-level Representations for Skill Abstraction and Multi-Agent Planning in Computer-Use Agents
Feb 19, 2026Computer-use agents operate over long horizons under noisy perception, multi-window contexts, evolving environment states. Existing approaches, from RL-based planners to trajectory retrieval, often drift from user intent and repeatedly solve routine subproblems, leading to error accumulation and inefficiency. We present IntentCUA, a multi-agent computer-use framework designed to stabilize long-horizon execution through intent-aligned plan memory. A Planner, Plan-Optimizer, and Critic coordinate over shared memory that abstracts raw interaction traces into multi-view intent representations and reusable skills. At runtime, intent prototypes retrieve subgroup-aligned skills and inject them into partial plans, reducing redundant re-planning and mitigating error propagation across desktop applications. In end-to-end evaluations, IntentCUA achieved a 74.83% task success rate with a Step Efficiency Ratio of 0.91, outperforming RL-based and trajectory-centric baselines. Ablations show that multi-view intent abstraction and shared plan memory jointly improve execution stability, with the cooperative multi-agent loop providing the largest gains on long-horizon tasks. These results highlight that system-level intent abstraction and memory-grounded coordination are key to reliable and efficient desktop automation in large, dynamic environments.
MAGE: All-[MASK] Block Already Knows Where to Look in Diffusion LLM
Feb 15, 2026Block diffusion LLMs are emerging as a promising next paradigm for language generation, but their use of KV caching makes memory access a dominant bottleneck in long-context settings. While dynamic sparse attention has been actively explored, existing methods designed for autoregressive LLMs rely on approximate importance estimation and perform poorly when adapted to block diffusion. This work identifies a key opportunity unique to block diffusion: attention at the first All-[MASK] denoising step reliably predicts important KV entries and budget requirements, enabling MAGE to perform a single exact attention pass per block and reuse it for training-free sparse denoising. Across long-context benchmarks including LongBench and Needle-in-a-Haystack, MAGE achieves near-lossless accuracy with a fraction of the KV budget while delivering up to 3-4x end-to-end speedup, consistently outperforming AR-oriented sparse attention baselines. A lightweight fine-tuning strategy further strengthens [MASK]-guided patterns with minimal cost, requiring only a few hours of training on a single NVIDIA H100 GPU for both 1.5B and 7B models.
Doppelgänger Method: Breaking Role Consistency in LLM Agent via Prompt-based Transferable Adversarial Attack
Jun 17, 2025

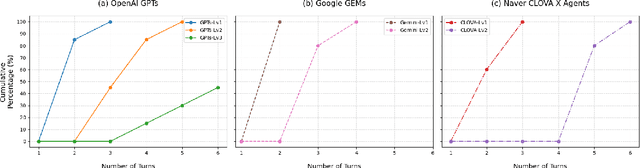
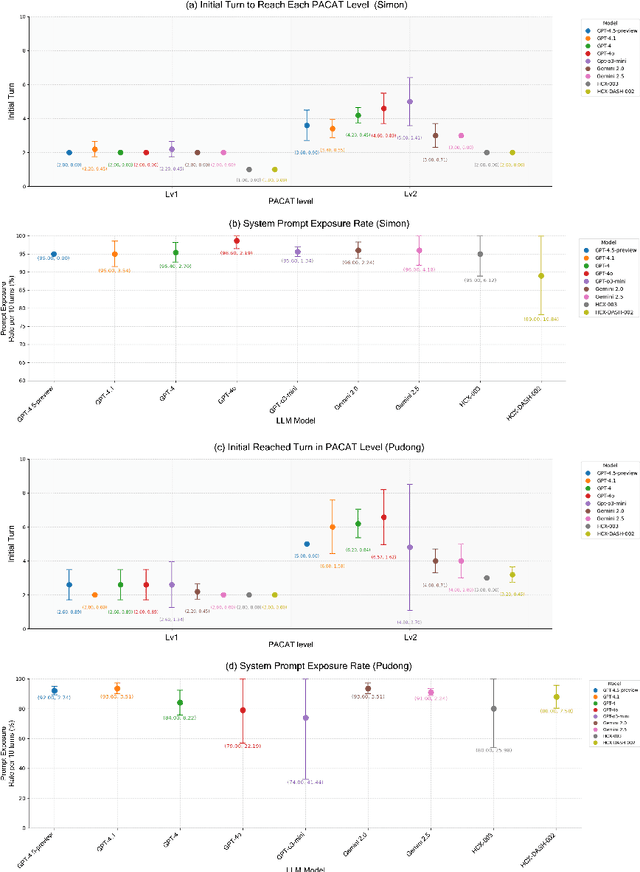
Since the advent of large language models, prompt engineering now enables the rapid, low-effort creation of diverse autonomous agents that are already in widespread use. Yet this convenience raises urgent concerns about the safety, robustness, and behavioral consistency of the underlying prompts, along with the pressing challenge of preventing those prompts from being exposed to user's attempts. In this paper, we propose the ''Doppelg\"anger method'' to demonstrate the risk of an agent being hijacked, thereby exposing system instructions and internal information. Next, we define the ''Prompt Alignment Collapse under Adversarial Transfer (PACAT)'' level to evaluate the vulnerability to this adversarial transfer attack. We also propose a ''Caution for Adversarial Transfer (CAT)'' prompt to counter the Doppelg\"anger method. The experimental results demonstrate that the Doppelg\"anger method can compromise the agent's consistency and expose its internal information. In contrast, CAT prompts enable effective defense against this adversarial attack.
MF-PAM: Accurate Pitch Estimation through Periodicity Analysis and Multi-level Feature Fusion
Jun 16, 2023We introduce Multi-level feature Fusion-based Periodicity Analysis Model (MF-PAM), a novel deep learning-based pitch estimation model that accurately estimates pitch trajectory in noisy and reverberant acoustic environments. Our model leverages the periodic characteristics of audio signals and involves two key steps: extracting pitch periodicity using periodic non-periodic convolution (PNP-Conv) blocks and estimating pitch by aggregating multi-level features using a modified bi-directional feature pyramid network (BiFPN). We evaluate our model on speech and music datasets and achieve superior pitch estimation performance compared to state-of-the-art baselines while using fewer model parameters. Our model achieves 99.20 % accuracy in pitch estimation on a clean musical dataset. Overall, our proposed model provides a promising solution for accurate pitch estimation in challenging acoustic environments and has potential applications in audio signal processing.
HD-DEMUCS: General Speech Restoration with Heterogeneous Decoders
Jun 02, 2023



This paper introduces an end-to-end neural speech restoration model, HD-DEMUCS, demonstrating efficacy across multiple distortion environments. Unlike conventional approaches that employ cascading frameworks to remove undesirable noise first and then restore missing signal components, our model performs these tasks in parallel using two heterogeneous decoder networks. Based on the U-Net style encoder-decoder framework, we attach an additional decoder so that each decoder network performs noise suppression or restoration separately. We carefully design each decoder architecture to operate appropriately depending on its objectives. Additionally, we improve performance by leveraging a learnable weighting factor, aggregating the two decoder output waveforms. Experimental results with objective metrics across various environments clearly demonstrate the effectiveness of our approach over a single decoder or multi-stage systems for general speech restoration task.
Context-Preserving Two-Stage Video Domain Translation for Portrait Stylization
May 30, 2023



Portrait stylization, which translates a real human face image into an artistically stylized image, has attracted considerable interest and many prior works have shown impressive quality in recent years. However, despite their remarkable performances in the image-level translation tasks, prior methods show unsatisfactory results when they are applied to the video domain. To address the issue, we propose a novel two-stage video translation framework with an objective function which enforces a model to generate a temporally coherent stylized video while preserving context in the source video. Furthermore, our model runs in real-time with the latency of 0.011 seconds per frame and requires only 5.6M parameters, and thus is widely applicable to practical real-world applications.
Fix the Noise: Disentangling Source Feature for Controllable Domain Translation
Mar 21, 2023Recent studies show strong generative performance in domain translation especially by using transfer learning techniques on the unconditional generator. However, the control between different domain features using a single model is still challenging. Existing methods often require additional models, which is computationally demanding and leads to unsatisfactory visual quality. In addition, they have restricted control steps, which prevents a smooth transition. In this paper, we propose a new approach for high-quality domain translation with better controllability. The key idea is to preserve source features within a disentangled subspace of a target feature space. This allows our method to smoothly control the degree to which it preserves source features while generating images from an entirely new domain using only a single model. Our extensive experiments show that the proposed method can produce more consistent and realistic images than previous works and maintain precise controllability over different levels of transformation. The code is available at https://github.com/LeeDongYeun/FixNoise.
Learning Audio-Text Agreement for Open-vocabulary Keyword Spotting
Jul 01, 2022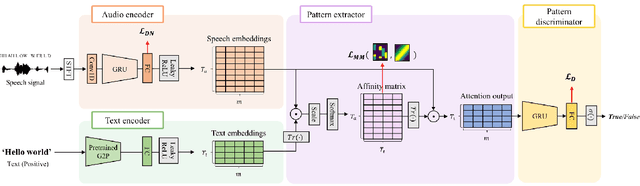
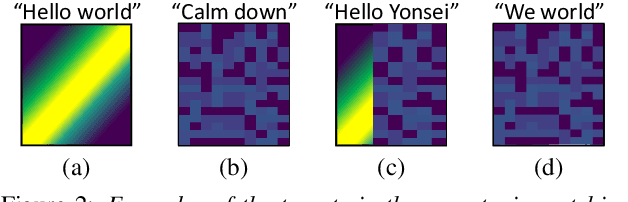

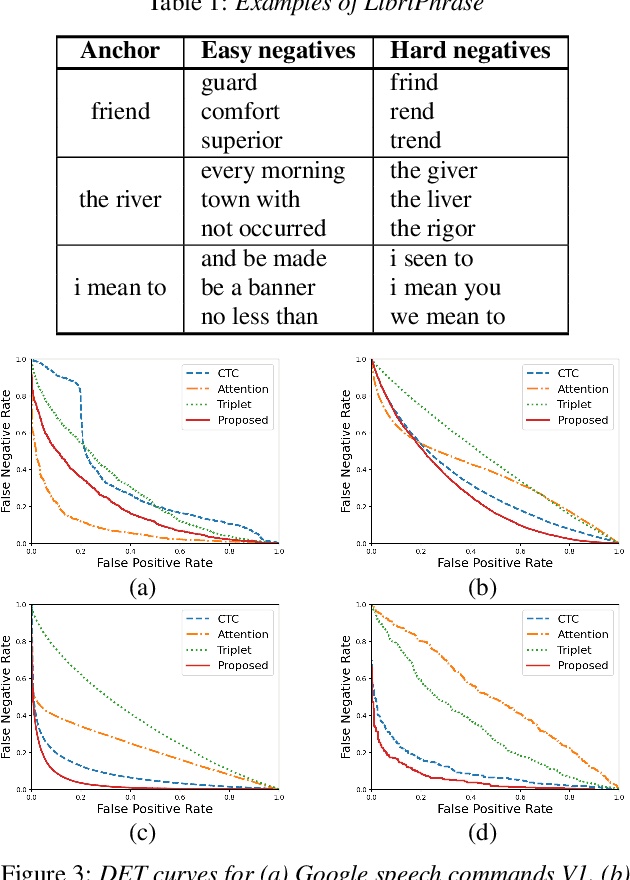
In this paper, we propose a novel end-to-end user-defined keyword spotting method that utilizes linguistically corresponding patterns between speech and text sequences. Unlike previous approaches requiring speech keyword enrollment, our method compares input queries with an enrolled text keyword sequence. To place the audio and text representations within a common latent space, we adopt an attention-based cross-modal matching approach that is trained in an end-to-end manner with monotonic matching loss and keyword classification loss. We also utilize a de-noising loss for the acoustic embedding network to improve robustness in noisy environments. Additionally, we introduce the LibriPhrase dataset, a new short-phrase dataset based on LibriSpeech for efficiently training keyword spotting models. Our proposed method achieves competitive results on various evaluation sets compared to other single-modal and cross-modal baselines.
Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
May 02, 2022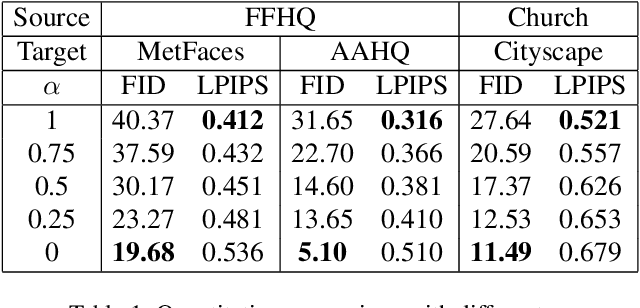
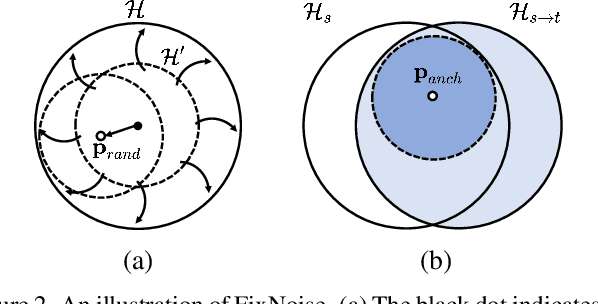
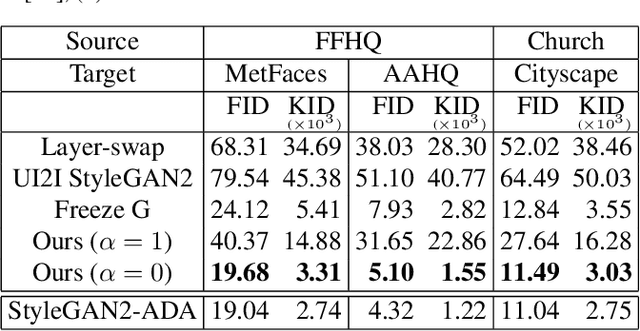

Transfer learning of StyleGAN has recently shown great potential to solve diverse tasks, especially in domain translation. Previous methods utilized a source model by swapping or freezing weights during transfer learning, however, they have limitations on visual quality and controlling source features. In other words, they require additional models that are computationally demanding and have restricted control steps that prevent a smooth transition. In this paper, we propose a new approach to overcome these limitations. Instead of swapping or freezing, we introduce a simple feature matching loss to improve generation quality. In addition, to control the degree of source features, we train a target model with the proposed strategy, FixNoise, to preserve the source features only in a disentangled subspace of a target feature space. Owing to the disentangled feature space, our method can smoothly control the degree of the source features in a single model. Extensive experiments demonstrate that the proposed method can generate more consistent and realistic images than previous works.
Phase Continuity: Learning Derivatives of Phase Spectrum for Speech Enhancement
Feb 24, 2022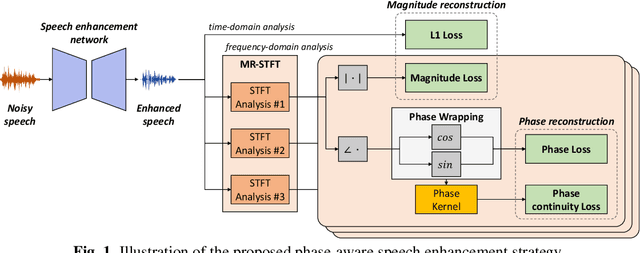
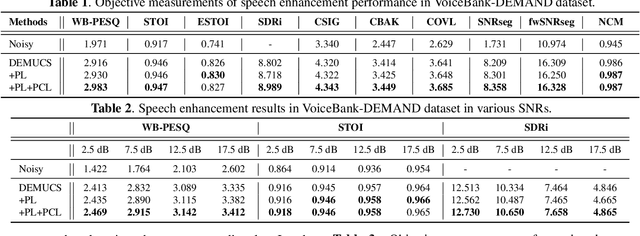
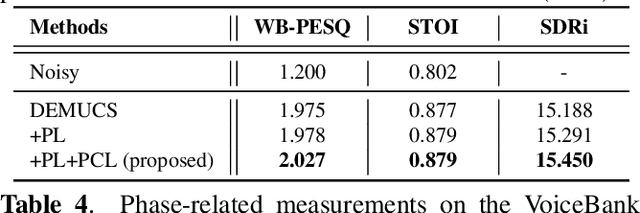
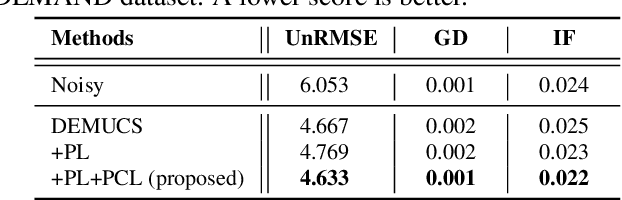
Modern neural speech enhancement models usually include various forms of phase information in their training loss terms, either explicitly or implicitly. However, these loss terms are typically designed to reduce the distortion of phase spectrum values at specific frequencies, which ensures they do not significantly affect the quality of the enhanced speech. In this paper, we propose an effective phase reconstruction strategy for neural speech enhancement that can operate in noisy environments. Specifically, we introduce a phase continuity loss that considers relative phase variations across the time and frequency axes. By including this phase continuity loss in a state-of-the-art neural speech enhancement system trained with reconstruction loss and a number of magnitude spectral losses, we show that our proposed method further improves the quality of enhanced speech signals over the baseline, especially when training is done jointly with a magnitude spectrum loss.