 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA generalizable foundation model for intraoperative understanding across surgical procedures
Feb 14, 2026In minimally invasive surgery, clinical decisions depend on real-time visual interpretation, yet intraoperative perception varies substantially across surgeons and procedures. This variability limits consistent assessment, training, and the development of reliable artificial intelligence systems, as most surgical AI models are designed for narrowly defined tasks and do not generalize across procedures or institutions. Here we introduce ZEN, a generalizable foundation model for intraoperative surgical video understanding trained on more than 4 million frames from over 21 procedures using a self-supervised multi-teacher distillation framework. We curated a large and diverse dataset and systematically evaluated multiple representation learning strategies within a unified benchmark. Across 20 downstream tasks and full fine-tuning, frozen-backbone, few-shot and zero-shot settings, ZEN consistently outperforms existing surgical foundation models and demonstrates robust cross-procedure generalization. These results suggest a step toward unified representations for surgical scene understanding and support future applications in intraoperative assistance and surgical training assessment.
CurConMix+: A Unified Spatio-Temporal Framework for Hierarchical Surgical Workflow Understanding
Jan 18, 2026Surgical action triplet recognition aims to understand fine-grained surgical behaviors by modeling the interactions among instruments, actions, and anatomical targets. Despite its clinical importance for workflow analysis and skill assessment, progress has been hindered by severe class imbalance, subtle visual variations, and the semantic interdependence among triplet components. Existing approaches often address only a subset of these challenges rather than tackling them jointly, which limits their ability to form a holistic understanding. This study builds upon CurConMix, a spatial representation framework. At its core, a curriculum-guided contrastive learning strategy learns discriminative and progressively correlated features, further enhanced by structured hard-pair sampling and feature-level mixup. Its temporal extension, CurConMix+, integrates a Multi-Resolution Temporal Transformer (MRTT) that achieves robust, context-aware understanding by adaptively fusing multi-scale temporal features and dynamically balancing spatio-temporal cues. Furthermore, we introduce LLS48, a new, hierarchically annotated benchmark for complex laparoscopic left lateral sectionectomy, providing step-, task-, and action-level annotations. Extensive experiments on CholecT45 and LLS48 demonstrate that CurConMix+ not only outperforms state-of-the-art approaches in triplet recognition, but also exhibits strong cross-level generalization, as its fine-grained features effectively transfer to higher-level phase and step recognition tasks. Together, the framework and dataset provide a unified foundation for hierarchy-aware, reproducible, and interpretable surgical workflow understanding. The code and dataset will be publicly released on GitHub to facilitate reproducibility and further research.
AURA: Development and Validation of an Augmented Unplanned Removal Alert System using Synthetic ICU Videos
Nov 15, 2025Unplanned extubation (UE) remains a critical patient safety concern in intensive care units (ICUs), often leading to severe complications or death. Real-time UE detection has been limited, largely due to the ethical and privacy challenges of obtaining annotated ICU video data. We propose Augmented Unplanned Removal Alert (AURA), a vision-based risk detection system developed and validated entirely on a fully synthetic video dataset. By leveraging text-to-video diffusion, we generated diverse and clinically realistic ICU scenarios capturing a range of patient behaviors and care contexts. The system applies pose estimation to identify two high-risk movement patterns: collision, defined as hand entry into spatial zones near airway tubes, and agitation, quantified by the velocity of tracked anatomical keypoints. Expert assessments confirmed the realism of the synthetic data, and performance evaluations showed high accuracy for collision detection and moderate performance for agitation recognition. This work demonstrates a novel pathway for developing privacy-preserving, reproducible patient safety monitoring systems with potential for deployment in intensive care settings.
Doppelgänger Method: Breaking Role Consistency in LLM Agent via Prompt-based Transferable Adversarial Attack
Jun 17, 2025

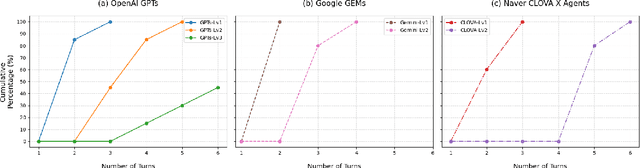
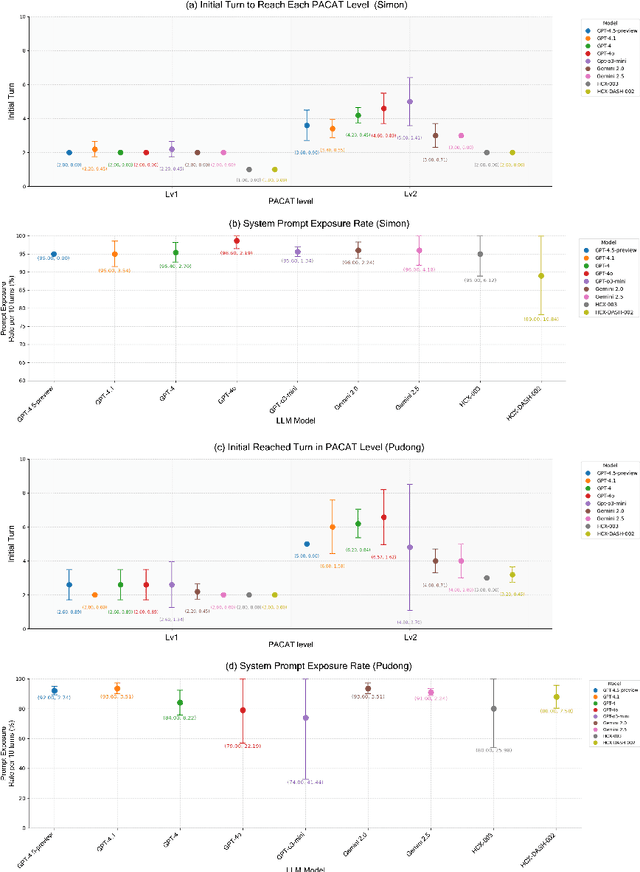
Since the advent of large language models, prompt engineering now enables the rapid, low-effort creation of diverse autonomous agents that are already in widespread use. Yet this convenience raises urgent concerns about the safety, robustness, and behavioral consistency of the underlying prompts, along with the pressing challenge of preventing those prompts from being exposed to user's attempts. In this paper, we propose the ''Doppelg\"anger method'' to demonstrate the risk of an agent being hijacked, thereby exposing system instructions and internal information. Next, we define the ''Prompt Alignment Collapse under Adversarial Transfer (PACAT)'' level to evaluate the vulnerability to this adversarial transfer attack. We also propose a ''Caution for Adversarial Transfer (CAT)'' prompt to counter the Doppelg\"anger method. The experimental results demonstrate that the Doppelg\"anger method can compromise the agent's consistency and expose its internal information. In contrast, CAT prompts enable effective defense against this adversarial attack.
Relieving the Plateau: Active Semi-Supervised Learning for a Better Landscape
Apr 08, 2021


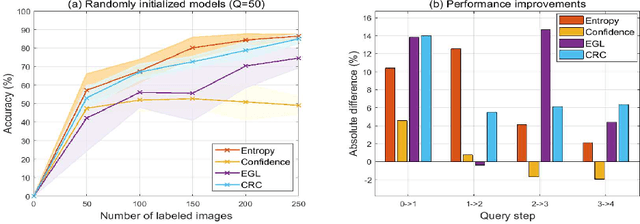
Deep learning (DL) relies on massive amounts of labeled data, and improving its labeled sample-efficiency remains one of the most important problems since its advent. Semi-supervised learning (SSL) leverages unlabeled data that are more accessible than their labeled counterparts. Active learning (AL) selects unlabeled instances to be annotated by a human-in-the-loop in hopes of better performance with less labeled data. Given the accessible pool of unlabeled data in pool-based AL, it seems natural to use SSL when training and AL to update the labeled set; however, algorithms designed for their combination remain limited. In this work, we first prove that convergence of gradient descent on sufficiently wide ReLU networks can be expressed in terms of their Gram matrix' eigen-spectrum. Equipped with a few theoretical insights, we propose convergence rate control (CRC), an AL algorithm that selects unlabeled data to improve the problem conditioning upon inclusion to the labeled set, by formulating an acquisition step in terms of improving training dynamics. Extensive experiments show that SSL algorithms coupled with CRC can achieve high performance using very few labeled data.
Resource Optimized Neural Architecture Search for 3D Medical Image Segmentation
Sep 02, 2019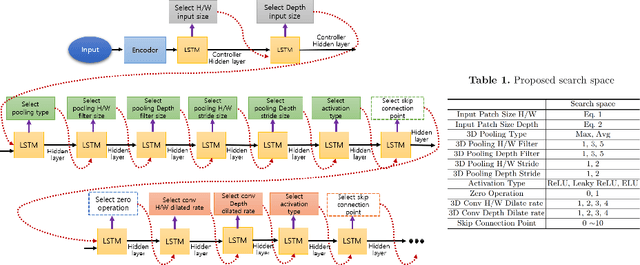
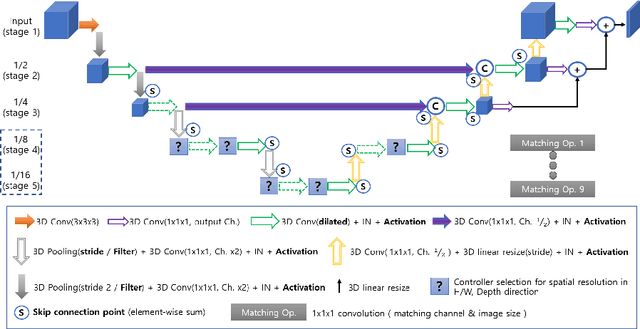
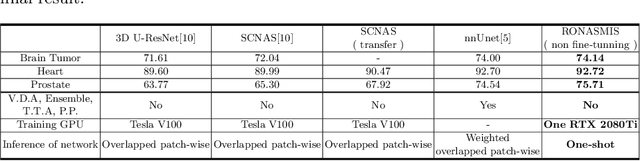
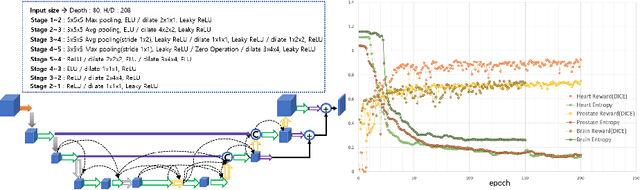
Neural Architecture Search (NAS), a framework which automates the task of designing neural networks, has recently been actively studied in the field of deep learning. However, there are only a few NAS methods suitable for 3D medical image segmentation. Medical 3D images are generally very large; thus it is difficult to apply previous NAS methods due to their GPU computational burden and long training time. We propose the resource-optimized neural architecture search method which can be applied to 3D medical segmentation tasks in a short training time (1.39 days for 1GB dataset) using a small amount of computation power (one RTX 2080Ti, 10.8GB GPU memory). Excellent performance can also be achieved without retraining(fine-tuning) which is essential in most NAS methods. These advantages can be achieved by using a reinforcement learning-based controller with parameter sharing and focusing on the optimal search space configuration of macro search rather than micro search. Our experiments demonstrate that the proposed NAS method outperforms manually designed networks with state-of-the-art performance in 3D medical image segmentation.
Integrating Reinforcement Learning to Self Training for Pulmonary Nodule Segmentation in Chest X-rays
Nov 21, 2018
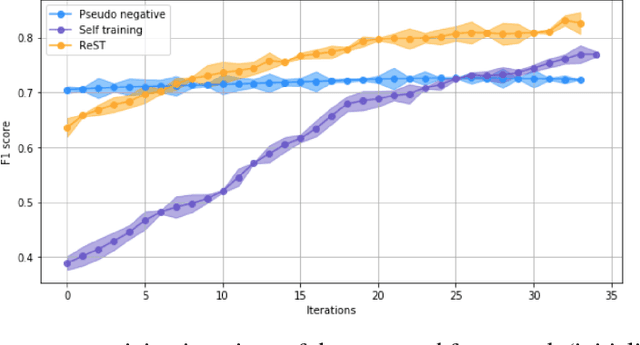
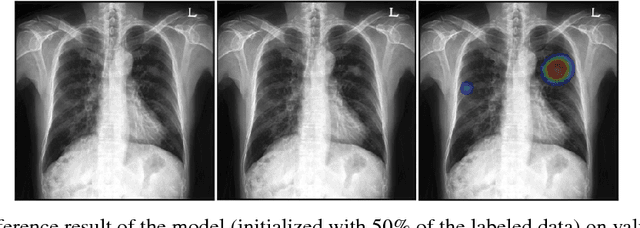
Machine learning applications in medical imaging are frequently limited by the lack of quality labeled data. In this paper, we explore the self training method, a form of semi-supervised learning, to address the labeling burden. By integrating reinforcement learning, we were able to expand the application of self training to complex segmentation networks without any further human annotation. The proposed approach, reinforced self training (ReST), fine tunes a semantic segmentation networks by introducing a policy network that learns to generate pseudolabels. We incorporate an expert demonstration network, based on inverse reinforcement learning, to enhance clinical validity and convergence of the policy network. The model was tested on a pulmonary nodule segmentation task in chest X-rays and achieved the performance of a standard U-Net while using only 50% of the labeled data, by exploiting unlabeled data. When the same number of labeled data was used, a moderate to significant cross validation accuracy improvement was achieved depending on the absolute number of labels used.
Classification of Findings with Localized Lesions in Fundoscopic Images using a Regionally Guided CNN
Nov 02, 2018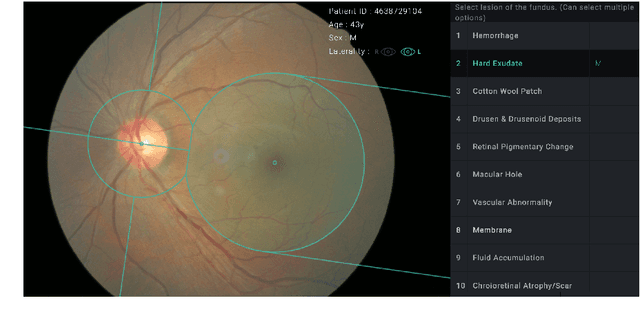
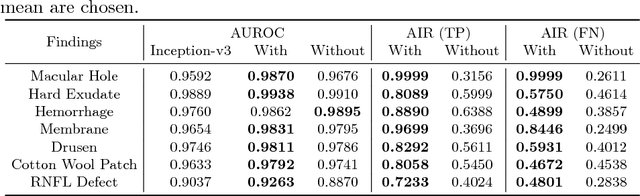
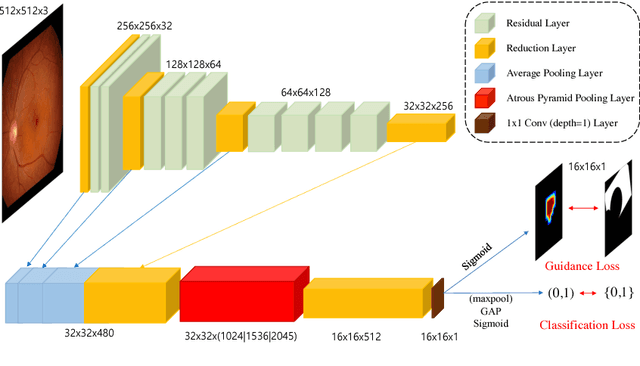
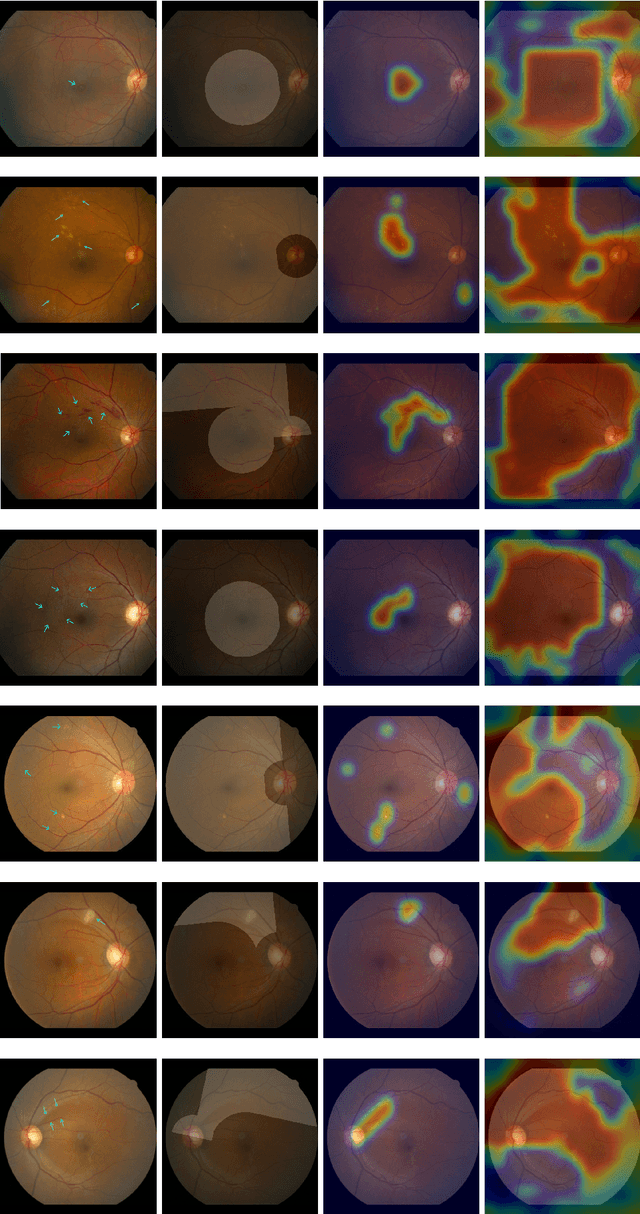
Fundoscopic images are often investigated by ophthalmologists to spot abnormal lesions to make diagnoses. Recent successes of convolutional neural networks are confined to diagnoses of few diseases without proper localization of lesion. In this paper, we propose an efficient annotation method for localizing lesions and a CNN architecture that can classify an individual finding and localize the lesions at the same time. Also, we introduce a new loss function to guide the network to learn meaningful patterns with the guidance of the regional annotations. In experiments, we demonstrate that our network performed better than the widely used network and the guidance loss helps achieve higher AUROC up to 4.1% and superior localization capability.
Retinal Vessel Segmentation in Fundoscopic Images with Generative Adversarial Networks
Jun 28, 2017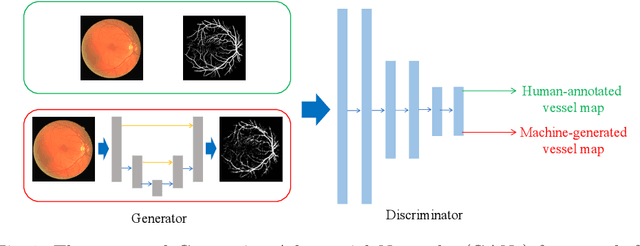
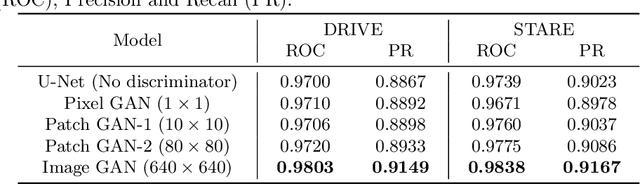
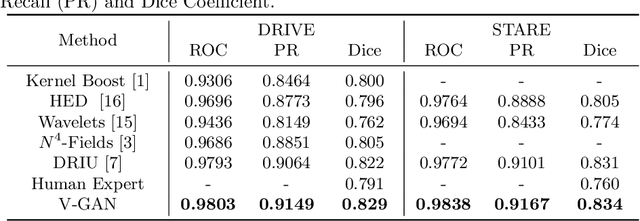
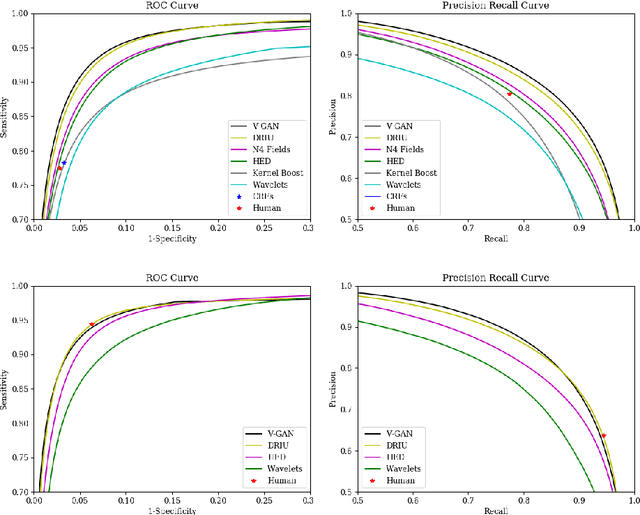
Retinal vessel segmentation is an indispensable step for automatic detection of retinal diseases with fundoscopic images. Though many approaches have been proposed, existing methods tend to miss fine vessels or allow false positives at terminal branches. Let alone under-segmentation, over-segmentation is also problematic when quantitative studies need to measure the precise width of vessels. In this paper, we present a method that generates the precise map of retinal vessels using generative adversarial training. Our methods achieve dice coefficient of 0.829 on DRIVE dataset and 0.834 on STARE dataset which is the state-of-the-art performance on both datasets.