 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Gradient Masking as a Defensive Measure to Deep Leakage in Federated Learning
Aug 15, 2024Federated Learning(FL), in theory, preserves privacy of individual clients' data while producing quality machine learning models. However, attacks such as Deep Leakage from Gradients(DLG) severely question the practicality of FL. In this paper, we empirically evaluate the efficacy of four defensive methods against DLG: Masking, Clipping, Pruning, and Noising. Masking, while only previously studied as a way to compress information during parameter transfer, shows surprisingly robust defensive utility when compared to the other three established methods. Our experimentation is two-fold. We first evaluate the minimum hyperparameter threshold for each method across MNIST, CIFAR-10, and lfw datasets. Then, we train FL clients with each method and their minimum threshold values to investigate the trade-off between DLG defense and training performance. Results reveal that Masking and Clipping show near to none degradation in performance while obfuscating enough information to effectively defend against DLG.
FDCNet: Feature Drift Compensation Network for Class-Incremental Weakly Supervised Object Localization
Sep 17, 2023



This work addresses the task of class-incremental weakly supervised object localization (CI-WSOL). The goal is to incrementally learn object localization for novel classes using only image-level annotations while retaining the ability to localize previously learned classes. This task is important because annotating bounding boxes for every new incoming data is expensive, although object localization is crucial in various applications. To the best of our knowledge, we are the first to address this task. Thus, we first present a strong baseline method for CI-WSOL by adapting the strategies of class-incremental classifiers to mitigate catastrophic forgetting. These strategies include applying knowledge distillation, maintaining a small data set from previous tasks, and using cosine normalization. We then propose the feature drift compensation network to compensate for the effects of feature drifts on class scores and localization maps. Since updating network parameters to learn new tasks causes feature drifts, compensating for the final outputs is necessary. Finally, we evaluate our proposed method by conducting experiments on two publicly available datasets (ImageNet-100 and CUB-200). The experimental results demonstrate that the proposed method outperforms other baseline methods.
A molecular generative model with genetic algorithm and tree search for cancer samples
Dec 16, 2021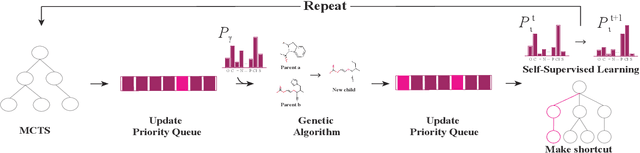
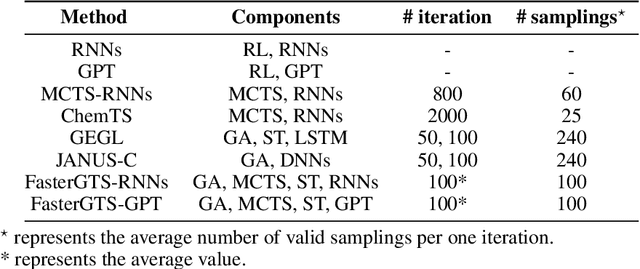
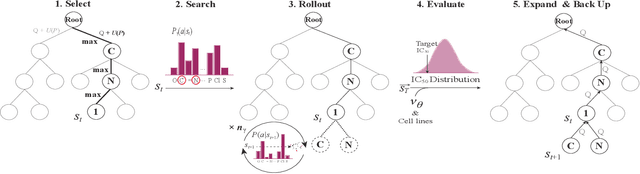
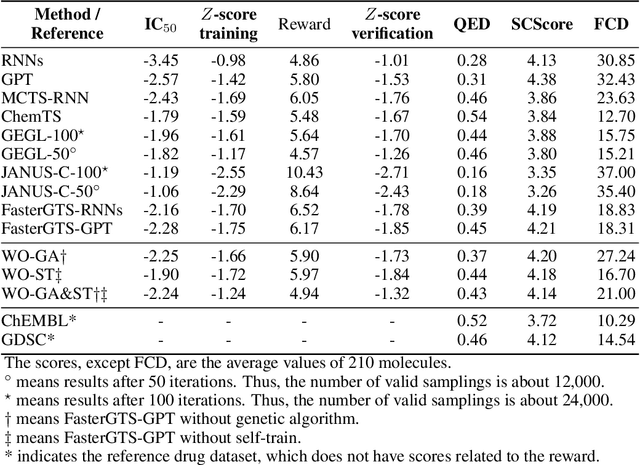
Personalized medicine is expected to maximize the intended drug effects and minimize side effects by treating patients based on their genetic profiles. Thus, it is important to generate drugs based on the genetic profiles of diseases, especially in anticancer drug discovery. However, this is challenging because the vast chemical space and variations in cancer properties require a huge time resource to search for proper molecules. Therefore, an efficient and fast search method considering genetic profiles is required for de novo molecular design of anticancer drugs. Here, we propose a faster molecular generative model with genetic algorithm and tree search for cancer samples (FasterGTS). FasterGTS is constructed with a genetic algorithm and a Monte Carlo tree search with three deep neural networks: supervised learning, self-trained, and value networks, and it generates anticancer molecules based on the genetic profiles of a cancer sample. When compared to other methods, FasterGTS generated cancer sample-specific molecules with general chemical properties required for cancer drugs within the limited numbers of samplings. We expect that FasterGTS contributes to the anticancer drug generation.
Integrating Reinforcement Learning to Self Training for Pulmonary Nodule Segmentation in Chest X-rays
Nov 21, 2018
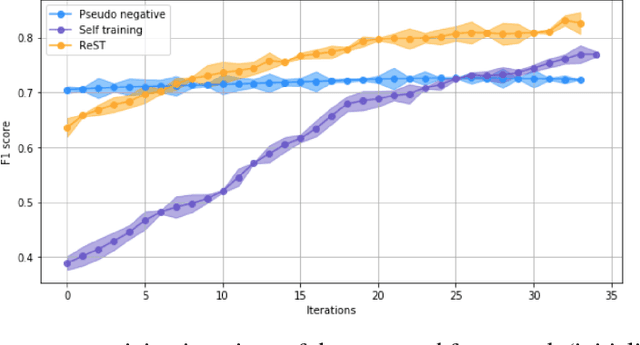
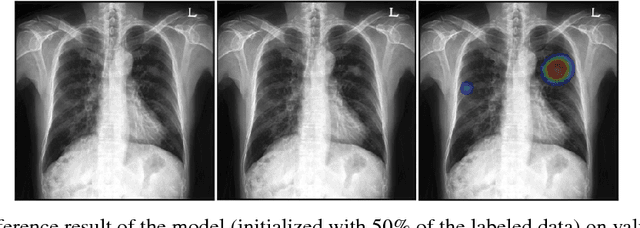
Machine learning applications in medical imaging are frequently limited by the lack of quality labeled data. In this paper, we explore the self training method, a form of semi-supervised learning, to address the labeling burden. By integrating reinforcement learning, we were able to expand the application of self training to complex segmentation networks without any further human annotation. The proposed approach, reinforced self training (ReST), fine tunes a semantic segmentation networks by introducing a policy network that learns to generate pseudolabels. We incorporate an expert demonstration network, based on inverse reinforcement learning, to enhance clinical validity and convergence of the policy network. The model was tested on a pulmonary nodule segmentation task in chest X-rays and achieved the performance of a standard U-Net while using only 50% of the labeled data, by exploiting unlabeled data. When the same number of labeled data was used, a moderate to significant cross validation accuracy improvement was achieved depending on the absolute number of labels used.
False Positive Reduction by Actively Mining Negative Samples for Pulmonary Nodule Detection in Chest Radiographs
Jul 26, 2018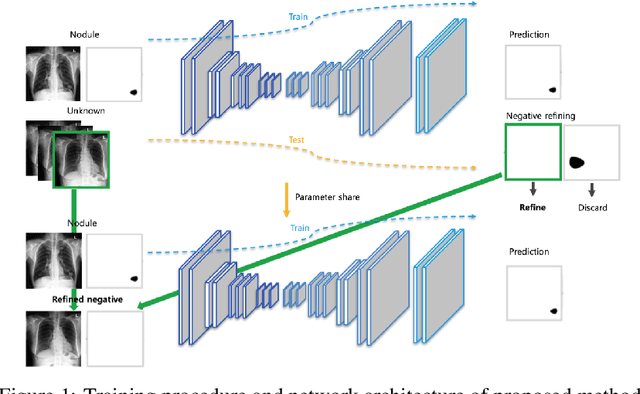

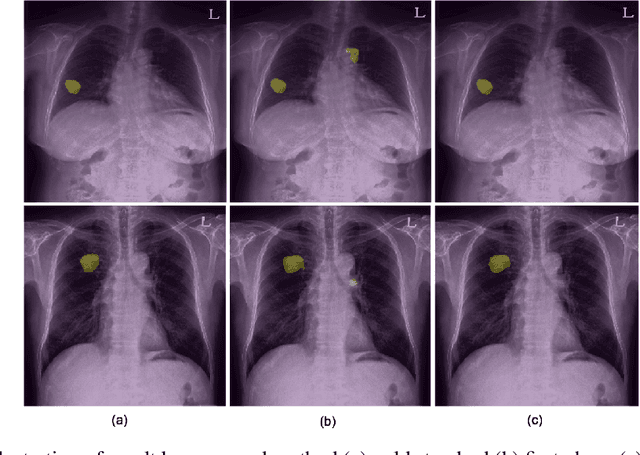
Generating large quantities of quality labeled data in medical imaging is very time consuming and expensive. The performance of supervised algorithms for various tasks on imaging has improved drastically over the years, however the availability of data to train these algorithms have become one of the main bottlenecks for implementation. To address this, we propose a semi-supervised learning method where pseudo-negative labels from unlabeled data are used to further refine the performance of a pulmonary nodule detection network in chest radiographs. After training with the proposed network, the false positive rate was reduced to 0.1266 from 0.4864 while maintaining sensitivity at 0.89.