 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Zero-Shot Learning for Point Cloud Segmentation with Evidence-Based Dynamic Calibration
Sep 10, 2025Generalized zero-shot semantic segmentation of 3D point clouds aims to classify each point into both seen and unseen classes. A significant challenge with these models is their tendency to make biased predictions, often favoring the classes encountered during training. This problem is more pronounced in 3D applications, where the scale of the training data is typically smaller than in image-based tasks. To address this problem, we propose a novel method called E3DPC-GZSL, which reduces overconfident predictions towards seen classes without relying on separate classifiers for seen and unseen data. E3DPC-GZSL tackles the overconfidence problem by integrating an evidence-based uncertainty estimator into a classifier. This estimator is then used to adjust prediction probabilities using a dynamic calibrated stacking factor that accounts for pointwise prediction uncertainty. In addition, E3DPC-GZSL introduces a novel training strategy that improves uncertainty estimation by refining the semantic space. This is achieved by merging learnable parameters with text-derived features, thereby improving model optimization for unseen data. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art performance on generalized zero-shot semantic segmentation datasets, including ScanNet v2 and S3DIS.
* 20 pages, 12 figures, AAAI 2025
Unsupervised Contrastive Learning Using Out-Of-Distribution Data for Long-Tailed Dataset
Jun 15, 2025This work addresses the task of self-supervised learning (SSL) on a long-tailed dataset that aims to learn balanced and well-separated representations for downstream tasks such as image classification. This task is crucial because the real world contains numerous object categories, and their distributions are inherently imbalanced. Towards robust SSL on a class-imbalanced dataset, we investigate leveraging a network trained using unlabeled out-of-distribution (OOD) data that are prevalently available online. We first train a network using both in-domain (ID) and sampled OOD data by back-propagating the proposed pseudo semantic discrimination loss alongside a domain discrimination loss. The OOD data sampling and loss functions are designed to learn a balanced and well-separated embedding space. Subsequently, we further optimize the network on ID data by unsupervised contrastive learning while using the previously trained network as a guiding network. The guiding network is utilized to select positive/negative samples and to control the strengths of attractive/repulsive forces in contrastive learning. We also distil and transfer its embedding space to the training network to maintain balancedness and separability. Through experiments on four publicly available long-tailed datasets, we demonstrate that the proposed method outperforms previous state-of-the-art methods.
* 13 pages
Generalized Class Discovery in Instance Segmentation
Feb 12, 2025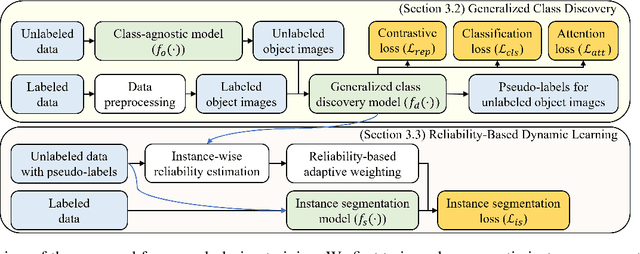
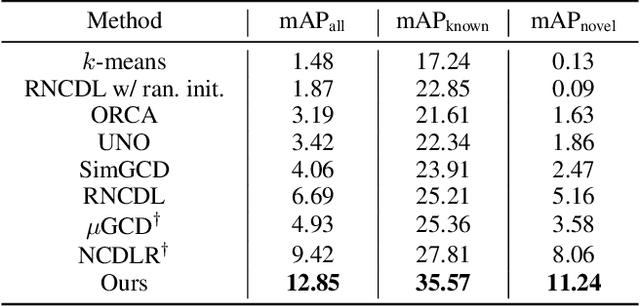
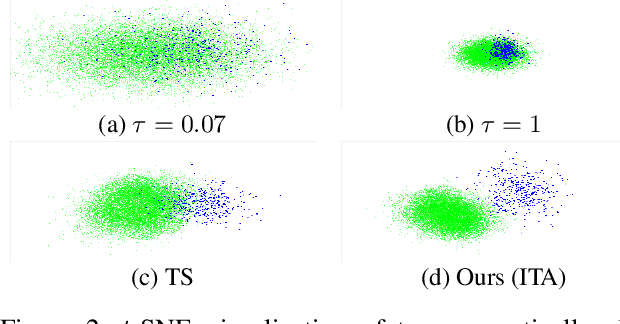
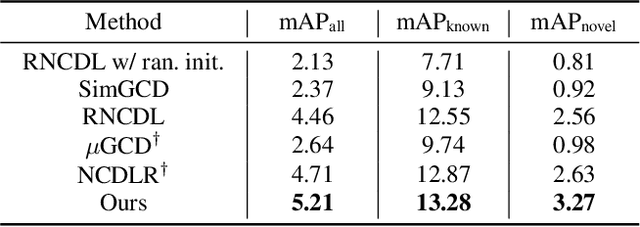
This work addresses the task of generalized class discovery (GCD) in instance segmentation. The goal is to discover novel classes and obtain a model capable of segmenting instances of both known and novel categories, given labeled and unlabeled data. Since the real world contains numerous objects with long-tailed distributions, the instance distribution for each class is inherently imbalanced. To address the imbalanced distributions, we propose an instance-wise temperature assignment (ITA) method for contrastive learning and class-wise reliability criteria for pseudo-labels. The ITA method relaxes instance discrimination for samples belonging to head classes to enhance GCD. The reliability criteria are to avoid excluding most pseudo-labels for tail classes when training an instance segmentation network using pseudo-labels from GCD. Additionally, we propose dynamically adjusting the criteria to leverage diverse samples in the early stages while relying only on reliable pseudo-labels in the later stages. We also introduce an efficient soft attention module to encode object-specific representations for GCD. Finally, we evaluate our proposed method by conducting experiments on two settings: COCO$_{half}$ + LVIS and LVIS + Visual Genome. The experimental results demonstrate that the proposed method outperforms previous state-of-the-art methods.
Content-Aware Preserving Image Generation
Nov 15, 2024



Remarkable progress has been achieved in image generation with the introduction of generative models. However, precisely controlling the content in generated images remains a challenging task due to their fundamental training objective. This paper addresses this challenge by proposing a novel image generation framework explicitly designed to incorporate desired content in output images. The framework utilizes advanced encoding techniques, integrating subnetworks called content fusion and frequency encoding modules. The frequency encoding module first captures features and structures of reference images by exclusively focusing on selected frequency components. Subsequently, the content fusion module generates a content-guiding vector that encapsulates desired content features. During the image generation process, content-guiding vectors from real images are fused with projected noise vectors. This ensures the production of generated images that not only maintain consistent content from guiding images but also exhibit diverse stylistic variations. To validate the effectiveness of the proposed framework in preserving content attributes, extensive experiments are conducted on widely used benchmark datasets, including Flickr-Faces-High Quality, Animal Faces High Quality, and Large-scale Scene Understanding datasets.
MSTA3D: Multi-scale Twin-attention for 3D Instance Segmentation
Nov 05, 2024Recently, transformer-based techniques incorporating superpoints have become prevalent in 3D instance segmentation. However, they often encounter an over-segmentation problem, especially noticeable with large objects. Additionally, unreliable mask predictions stemming from superpoint mask prediction further compound this issue. To address these challenges, we propose a novel framework called MSTA3D. It leverages multi-scale feature representation and introduces a twin-attention mechanism to effectively capture them. Furthermore, MSTA3D integrates a box query with a box regularizer, offering a complementary spatial constraint alongside semantic queries. Experimental evaluations on ScanNetV2, ScanNet200 and S3DIS datasets demonstrate that our approach surpasses state-of-the-art 3D instance segmentation methods.
* 14 pages, 9 figures, 7 tables, conference
Enhancing Long-Term Person Re-Identification Using Global, Local Body Part, and Head Streams
Mar 05, 2024



This work addresses the task of long-term person re-identification. Typically, person re-identification assumes that people do not change their clothes, which limits its applications to short-term scenarios. To overcome this limitation, we investigate long-term person re-identification, which considers both clothes-changing and clothes-consistent scenarios. In this paper, we propose a novel framework that effectively learns and utilizes both global and local information. The proposed framework consists of three streams: global, local body part, and head streams. The global and head streams encode identity-relevant information from an entire image and a cropped image of the head region, respectively. Both streams encode the most distinct, less distinct, and average features using the combinations of adversarial erasing, max pooling, and average pooling. The local body part stream extracts identity-related information for each body part, allowing it to be compared with the same body part from another image. Since body part annotations are not available in re-identification datasets, pseudo-labels are generated using clustering. These labels are then utilized to train a body part segmentation head in the local body part stream. The proposed framework is trained by backpropagating the weighted summation of the identity classification loss, the pair-based loss, and the pseudo body part segmentation loss. To demonstrate the effectiveness of the proposed method, we conducted experiments on three publicly available datasets (Celeb-reID, PRCC, and VC-Clothes). The experimental results demonstrate that the proposed method outperforms the previous state-of-the-art method.
* 16 pages
FDCNet: Feature Drift Compensation Network for Class-Incremental Weakly Supervised Object Localization
Sep 17, 2023



This work addresses the task of class-incremental weakly supervised object localization (CI-WSOL). The goal is to incrementally learn object localization for novel classes using only image-level annotations while retaining the ability to localize previously learned classes. This task is important because annotating bounding boxes for every new incoming data is expensive, although object localization is crucial in various applications. To the best of our knowledge, we are the first to address this task. Thus, we first present a strong baseline method for CI-WSOL by adapting the strategies of class-incremental classifiers to mitigate catastrophic forgetting. These strategies include applying knowledge distillation, maintaining a small data set from previous tasks, and using cosine normalization. We then propose the feature drift compensation network to compensate for the effects of feature drifts on class scores and localization maps. Since updating network parameters to learn new tasks causes feature drifts, compensating for the final outputs is necessary. Finally, we evaluate our proposed method by conducting experiments on two publicly available datasets (ImageNet-100 and CUB-200). The experimental results demonstrate that the proposed method outperforms other baseline methods.
Sampling Agnostic Feature Representation for Long-Term Person Re-identification
Sep 20, 2022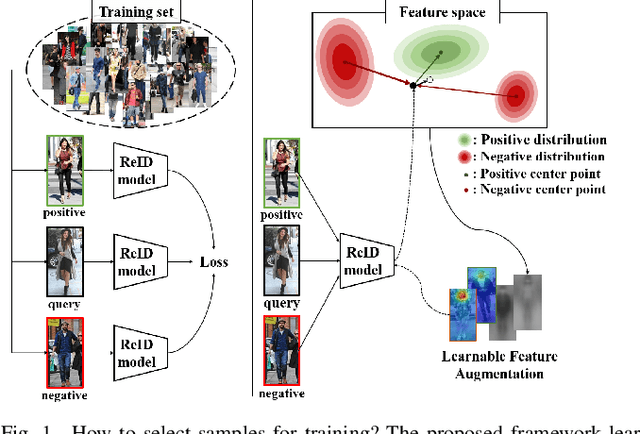
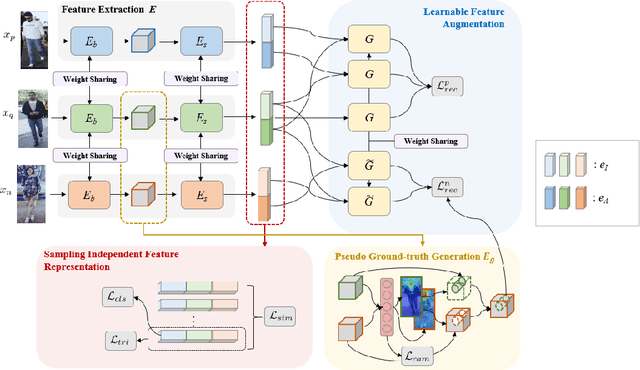
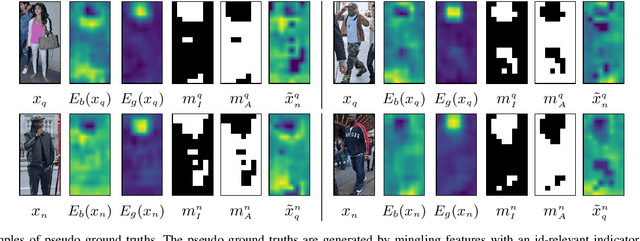

Person re-identification is a problem of identifying individuals across non-overlapping cameras. Although remarkable progress has been made in the re-identification problem, it is still a challenging problem due to appearance variations of the same person as well as other people of similar appearance. Some prior works solved the issues by separating features of positive samples from features of negative ones. However, the performances of existing models considerably depend on the characteristics and statistics of the samples used for training. Thus, we propose a novel framework named sampling independent robust feature representation network~(SirNet) that learns disentangled feature embedding from randomly chosen samples. A carefully designed sampling independent maximum discrepancy loss is introduced to model samples of the same person as a cluster. As a result, the proposed framework can generate additional hard negatives/positives using the learned features, which results in better discriminability from other identities. Extensive experimental results on large-scale benchmark datasets verify that the proposed model is more effective than prior state-of-the-art models.
Modeling, Quantifying, and Predicting Subjectivity of Image Aesthetics
Aug 20, 2022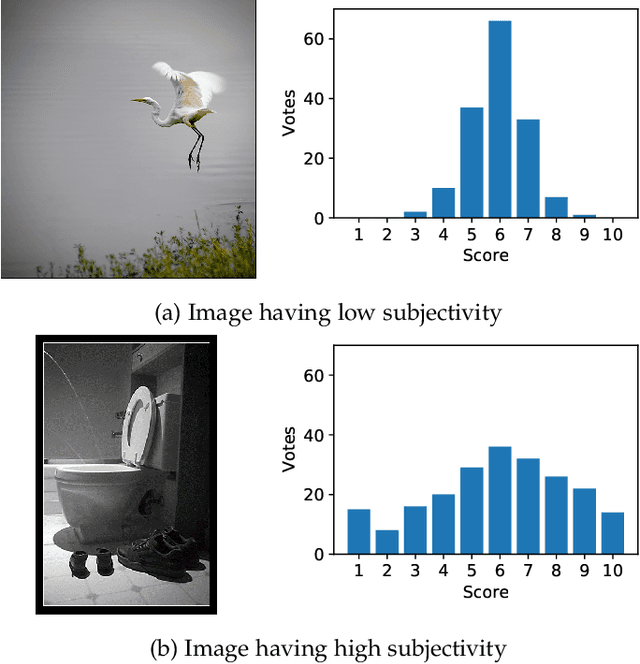
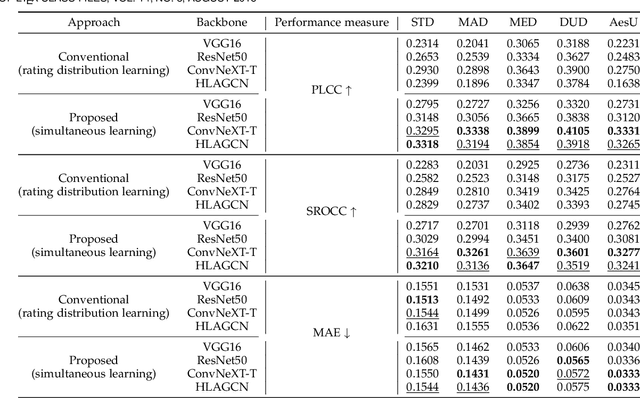
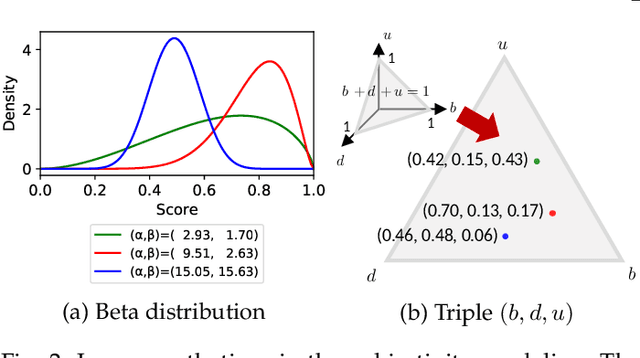

Assessing image aesthetics is a challenging computer vision task. One reason is that aesthetic preference is highly subjective and may vary significantly among people for certain images. Thus, it is important to properly model and quantify such \textit{subjectivity}, but there has not been much effort to resolve this issue. In this paper, we propose a novel unified probabilistic framework that can model and quantify subjective aesthetic preference based on the subjective logic. In this framework, the rating distribution is modeled as a beta distribution, from which the probabilities of being definitely pleasing, being definitely unpleasing, and being uncertain can be obtained. We use the probability of being uncertain to define an intuitive metric of subjectivity. Furthermore, we present a method to learn deep neural networks for prediction of image aesthetics, which is shown to be effective in improving the performance of subjectivity prediction via experiments. We also present an application scenario where the framework is beneficial for aesthetics-based image recommendation.
Dense Depth Estimation from Multiple 360-degree Images Using Virtual Depth
Dec 30, 2021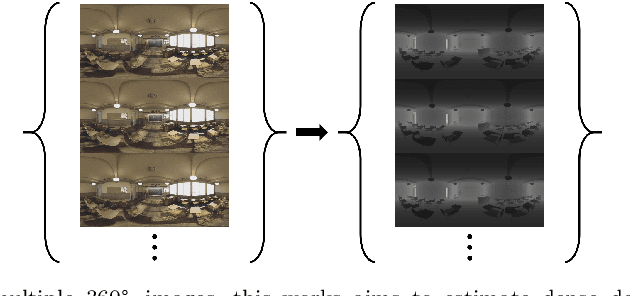
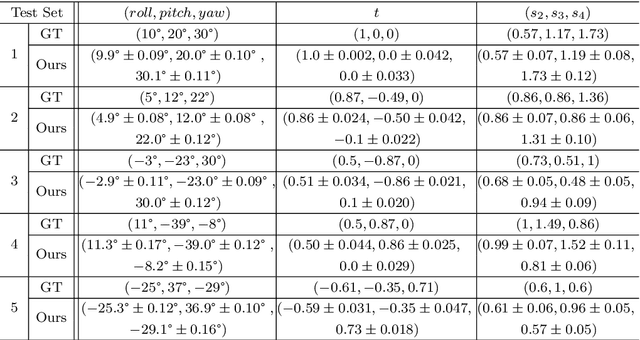
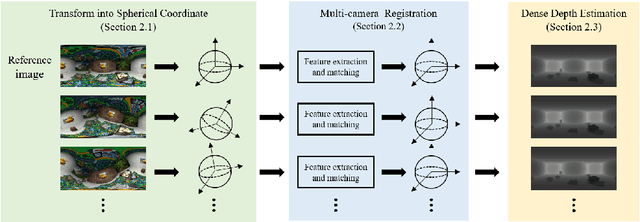
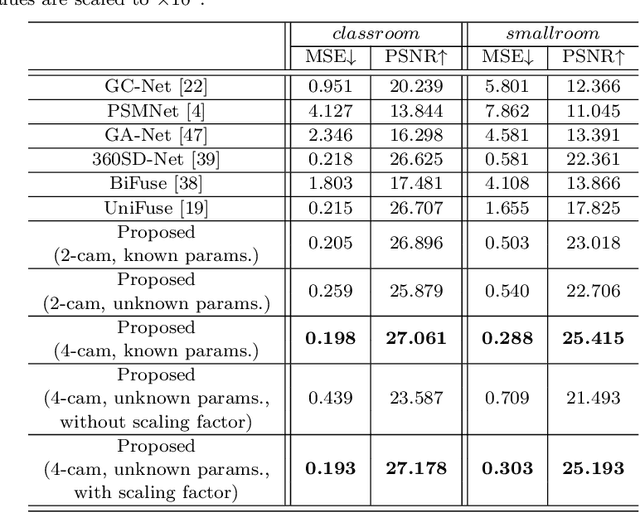
In this paper, we propose a dense depth estimation pipeline for multiview 360\degree\: images. The proposed pipeline leverages a spherical camera model that compensates for radial distortion in 360\degree\: images. The key contribution of this paper is the extension of a spherical camera model to multiview by introducing a translation scaling scheme. Moreover, we propose an effective dense depth estimation method by setting virtual depth and minimizing photonic reprojection error. We validate the performance of the proposed pipeline using the images of natural scenes as well as the synthesized dataset for quantitive evaluation. The experimental results verify that the proposed pipeline improves estimation accuracy compared to the current state-of-art dense depth estimation methods.