 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Contrastive Learning Using Out-Of-Distribution Data for Long-Tailed Dataset
Jun 15, 2025This work addresses the task of self-supervised learning (SSL) on a long-tailed dataset that aims to learn balanced and well-separated representations for downstream tasks such as image classification. This task is crucial because the real world contains numerous object categories, and their distributions are inherently imbalanced. Towards robust SSL on a class-imbalanced dataset, we investigate leveraging a network trained using unlabeled out-of-distribution (OOD) data that are prevalently available online. We first train a network using both in-domain (ID) and sampled OOD data by back-propagating the proposed pseudo semantic discrimination loss alongside a domain discrimination loss. The OOD data sampling and loss functions are designed to learn a balanced and well-separated embedding space. Subsequently, we further optimize the network on ID data by unsupervised contrastive learning while using the previously trained network as a guiding network. The guiding network is utilized to select positive/negative samples and to control the strengths of attractive/repulsive forces in contrastive learning. We also distil and transfer its embedding space to the training network to maintain balancedness and separability. Through experiments on four publicly available long-tailed datasets, we demonstrate that the proposed method outperforms previous state-of-the-art methods.
* 13 pages
Long-Tailed Learning for Generalized Category Discovery
Jun 08, 2025



Generalized Category Discovery (GCD) utilizes labeled samples of known classes to discover novel classes in unlabeled samples. Existing methods show effective performance on artificial datasets with balanced distributions. However, real-world datasets are always imbalanced, significantly affecting the effectiveness of these methods. To solve this problem, we propose a novel framework that performs generalized category discovery in long-tailed distributions. We first present a self-guided labeling technique that uses a learnable distribution to generate pseudo-labels, resulting in less biased classifiers. We then introduce a representation balancing process to derive discriminative representations. By mining sample neighborhoods, this process encourages the model to focus more on tail classes. We conduct experiments on public datasets to demonstrate the effectiveness of the proposed framework. The results show that our model exceeds previous state-of-the-art methods.
Generalized Class Discovery in Instance Segmentation
Feb 12, 2025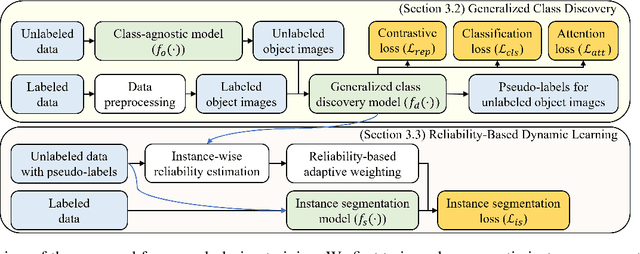
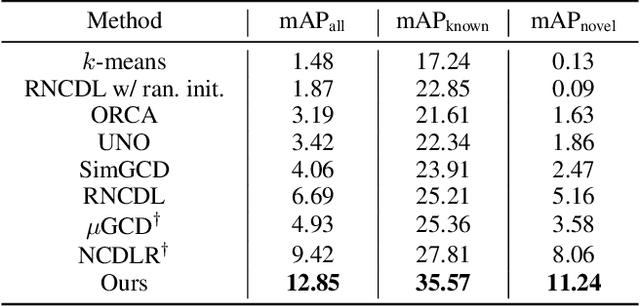
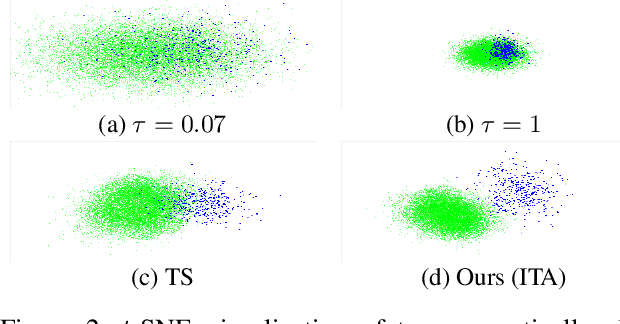
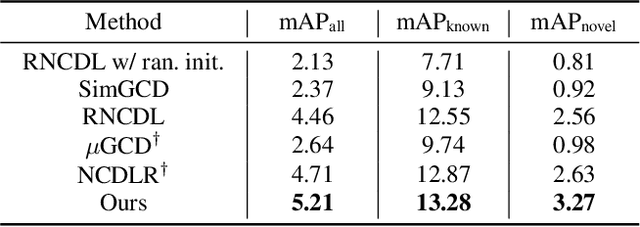
This work addresses the task of generalized class discovery (GCD) in instance segmentation. The goal is to discover novel classes and obtain a model capable of segmenting instances of both known and novel categories, given labeled and unlabeled data. Since the real world contains numerous objects with long-tailed distributions, the instance distribution for each class is inherently imbalanced. To address the imbalanced distributions, we propose an instance-wise temperature assignment (ITA) method for contrastive learning and class-wise reliability criteria for pseudo-labels. The ITA method relaxes instance discrimination for samples belonging to head classes to enhance GCD. The reliability criteria are to avoid excluding most pseudo-labels for tail classes when training an instance segmentation network using pseudo-labels from GCD. Additionally, we propose dynamically adjusting the criteria to leverage diverse samples in the early stages while relying only on reliable pseudo-labels in the later stages. We also introduce an efficient soft attention module to encode object-specific representations for GCD. Finally, we evaluate our proposed method by conducting experiments on two settings: COCO$_{half}$ + LVIS and LVIS + Visual Genome. The experimental results demonstrate that the proposed method outperforms previous state-of-the-art methods.
Pixel-Level Clustering Network for Unsupervised Image Segmentation
Oct 24, 2023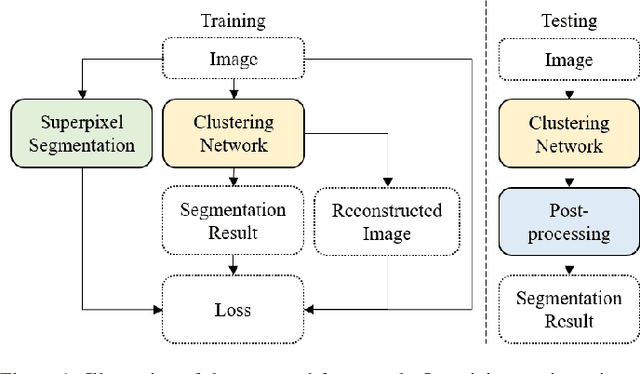



While image segmentation is crucial in various computer vision applications, such as autonomous driving, grasping, and robot navigation, annotating all objects at the pixel-level for training is nearly impossible. Therefore, the study of unsupervised image segmentation methods is essential. In this paper, we present a pixel-level clustering framework for segmenting images into regions without using ground truth annotations. The proposed framework includes feature embedding modules with an attention mechanism, a feature statistics computing module, image reconstruction, and superpixel segmentation to achieve accurate unsupervised segmentation. Additionally, we propose a training strategy that utilizes intra-consistency within each superpixel, inter-similarity/dissimilarity between neighboring superpixels, and structural similarity between images. To avoid potential over-segmentation caused by superpixel-based losses, we also propose a post-processing method. Furthermore, we present an extension of the proposed method for unsupervised semantic segmentation. We conducted experiments on three publicly available datasets (Berkeley segmentation dataset, PASCAL VOC 2012 dataset, and COCO-Stuff dataset) to demonstrate the effectiveness of the proposed framework. The experimental results show that the proposed framework outperforms previous state-of-the-art methods.
* 13 pages