 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirectional Textual Inversion for Personalized Text-to-Image Generation
Dec 15, 2025Textual Inversion (TI) is an efficient approach to text-to-image personalization but often fails on complex prompts. We trace these failures to embedding norm inflation: learned tokens drift to out-of-distribution magnitudes, degrading prompt conditioning in pre-norm Transformers. Empirically, we show semantics are primarily encoded by direction in CLIP token space, while inflated norms harm contextualization; theoretically, we analyze how large magnitudes attenuate positional information and hinder residual updates in pre-norm blocks. We propose Directional Textual Inversion (DTI), which fixes the embedding magnitude to an in-distribution scale and optimizes only direction on the unit hypersphere via Riemannian SGD. We cast direction learning as MAP with a von Mises-Fisher prior, yielding a constant-direction prior gradient that is simple and efficient to incorporate. Across personalization tasks, DTI improves text fidelity over TI and TI-variants while maintaining subject similarity. Crucially, DTI's hyperspherical parameterization enables smooth, semantically coherent interpolation between learned concepts (slerp), a capability that is absent in standard TI. Our findings suggest that direction-only optimization is a robust and scalable path for prompt-faithful personalization.
TextBoost: Towards One-Shot Personalization of Text-to-Image Models via Fine-tuning Text Encoder
Sep 12, 2024



Recent breakthroughs in text-to-image models have opened up promising research avenues in personalized image generation, enabling users to create diverse images of a specific subject using natural language prompts. However, existing methods often suffer from performance degradation when given only a single reference image. They tend to overfit the input, producing highly similar outputs regardless of the text prompt. This paper addresses the challenge of one-shot personalization by mitigating overfitting, enabling the creation of controllable images through text prompts. Specifically, we propose a selective fine-tuning strategy that focuses on the text encoder. Furthermore, we introduce three key techniques to enhance personalization performance: (1) augmentation tokens to encourage feature disentanglement and alleviate overfitting, (2) a knowledge-preservation loss to reduce language drift and promote generalizability across diverse prompts, and (3) SNR-weighted sampling for efficient training. Extensive experiments demonstrate that our approach efficiently generates high-quality, diverse images using only a single reference image while significantly reducing memory and storage requirements.
DreamStyler: Paint by Style Inversion with Text-to-Image Diffusion Models
Sep 13, 2023Recent progresses in large-scale text-to-image models have yielded remarkable accomplishments, finding various applications in art domain. However, expressing unique characteristics of an artwork (e.g. brushwork, colortone, or composition) with text prompts alone may encounter limitations due to the inherent constraints of verbal description. To this end, we introduce DreamStyler, a novel framework designed for artistic image synthesis, proficient in both text-to-image synthesis and style transfer. DreamStyler optimizes a multi-stage textual embedding with a context-aware text prompt, resulting in prominent image quality. In addition, with content and style guidance, DreamStyler exhibits flexibility to accommodate a range of style references. Experimental results demonstrate its superior performance across multiple scenarios, suggesting its promising potential in artistic product creation.
AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks
Aug 08, 2023


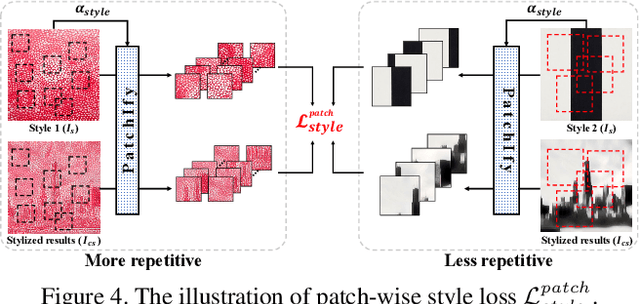
To deliver the artistic expression of the target style, recent studies exploit the attention mechanism owing to its ability to map the local patches of the style image to the corresponding patches of the content image. However, because of the low semantic correspondence between arbitrary content and artworks, the attention module repeatedly abuses specific local patches from the style image, resulting in disharmonious and evident repetitive artifacts. To overcome this limitation and accomplish impeccable artistic style transfer, we focus on enhancing the attention mechanism and capturing the rhythm of patterns that organize the style. In this paper, we introduce a novel metric, namely pattern repeatability, that quantifies the repetition of patterns in the style image. Based on the pattern repeatability, we propose Aesthetic Pattern-Aware style transfer Networks (AesPA-Net) that discover the sweet spot of local and global style expressions. In addition, we propose a novel self-supervisory task to encourage the attention mechanism to learn precise and meaningful semantic correspondence. Lastly, we introduce the patch-wise style loss to transfer the elaborate rhythm of local patterns. Through qualitative and quantitative evaluations, we verify the reliability of the proposed pattern repeatability that aligns with human perception, and demonstrate the superiority of the proposed framework.
Revisiting Image Pyramid Structure for High Resolution Salient Object Detection
Sep 26, 2022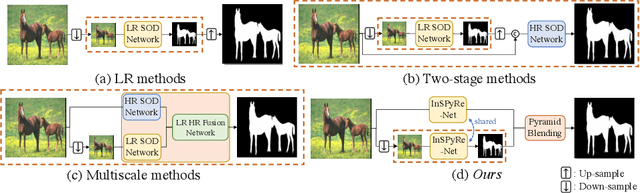
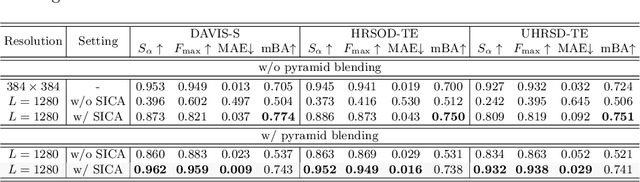

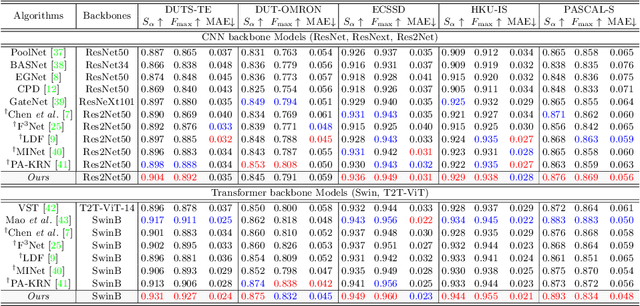
Salient object detection (SOD) has been in the spotlight recently, yet has been studied less for high-resolution (HR) images. Unfortunately, HR images and their pixel-level annotations are certainly more labor-intensive and time-consuming compared to low-resolution (LR) images and annotations. Therefore, we propose an image pyramid-based SOD framework, Inverse Saliency Pyramid Reconstruction Network (InSPyReNet), for HR prediction without any of HR datasets. We design InSPyReNet to produce a strict image pyramid structure of saliency map, which enables to ensemble multiple results with pyramid-based image blending. For HR prediction, we design a pyramid blending method which synthesizes two different image pyramids from a pair of LR and HR scale from the same image to overcome effective receptive field (ERF) discrepancy. Our extensive evaluations on public LR and HR SOD benchmarks demonstrate that InSPyReNet surpasses the State-of-the-Art (SotA) methods on various SOD metrics and boundary accuracy.
A Style-aware Discriminator for Controllable Image Translation
Mar 29, 2022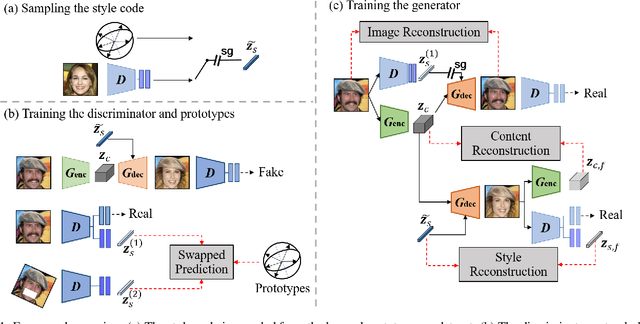
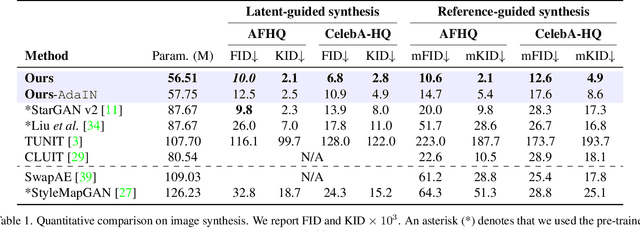

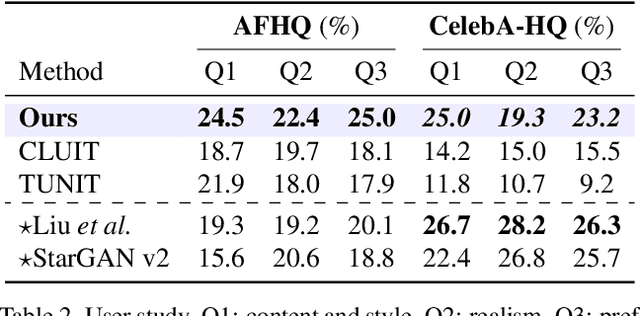
Current image-to-image translations do not control the output domain beyond the classes used during training, nor do they interpolate between different domains well, leading to implausible results. This limitation largely arises because labels do not consider the semantic distance. To mitigate such problems, we propose a style-aware discriminator that acts as a critic as well as a style encoder to provide conditions. The style-aware discriminator learns a controllable style space using prototype-based self-supervised learning and simultaneously guides the generator. Experiments on multiple datasets verify that the proposed model outperforms current state-of-the-art image-to-image translation methods. In contrast with current methods, the proposed approach supports various applications, including style interpolation, content transplantation, and local image translation.
Dense Depth Estimation from Multiple 360-degree Images Using Virtual Depth
Dec 30, 2021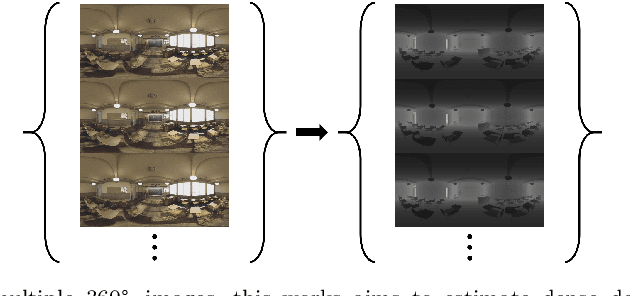
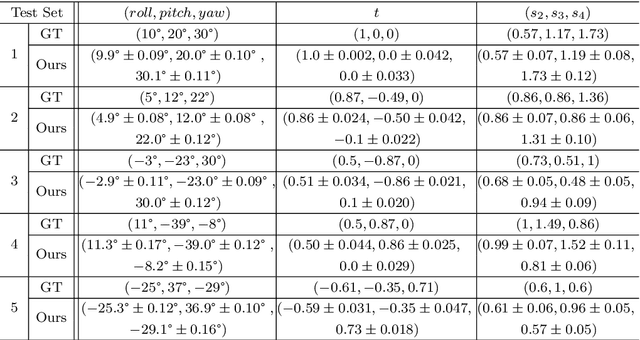
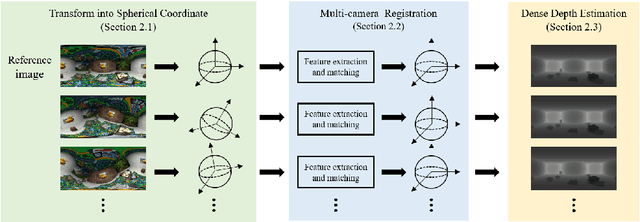
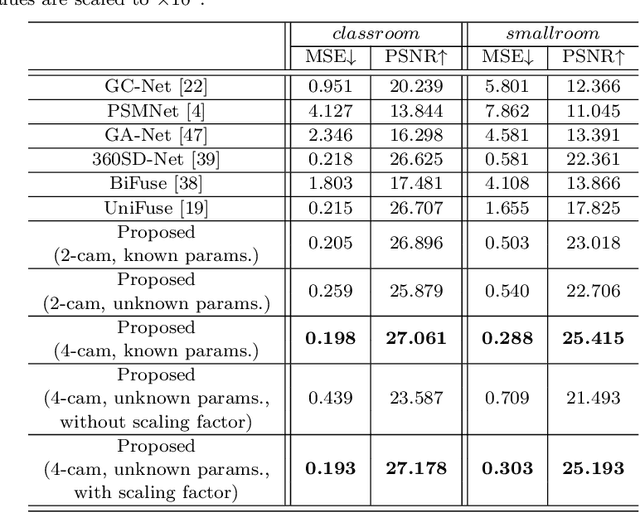
In this paper, we propose a dense depth estimation pipeline for multiview 360\degree\: images. The proposed pipeline leverages a spherical camera model that compensates for radial distortion in 360\degree\: images. The key contribution of this paper is the extension of a spherical camera model to multiview by introducing a translation scaling scheme. Moreover, we propose an effective dense depth estimation method by setting virtual depth and minimizing photonic reprojection error. We validate the performance of the proposed pipeline using the images of natural scenes as well as the synthesized dataset for quantitive evaluation. The experimental results verify that the proposed pipeline improves estimation accuracy compared to the current state-of-art dense depth estimation methods.
FA-GAN: Feature-Aware GAN for Text to Image Synthesis
Sep 02, 2021

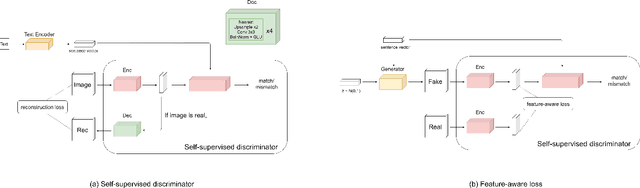

Text-to-image synthesis aims to generate a photo-realistic image from a given natural language description. Previous works have made significant progress with Generative Adversarial Networks (GANs). Nonetheless, it is still hard to generate intact objects or clear textures (Fig 1). To address this issue, we propose Feature-Aware Generative Adversarial Network (FA-GAN) to synthesize a high-quality image by integrating two techniques: a self-supervised discriminator and a feature-aware loss. First, we design a self-supervised discriminator with an auxiliary decoder so that the discriminator can extract better representation. Secondly, we introduce a feature-aware loss to provide the generator more direct supervision by employing the feature representation from the self-supervised discriminator. Experiments on the MS-COCO dataset show that our proposed method significantly advances the state-of-the-art FID score from 28.92 to 24.58.
Localization Uncertainty-Based Attention for Object Detection
Aug 25, 2021
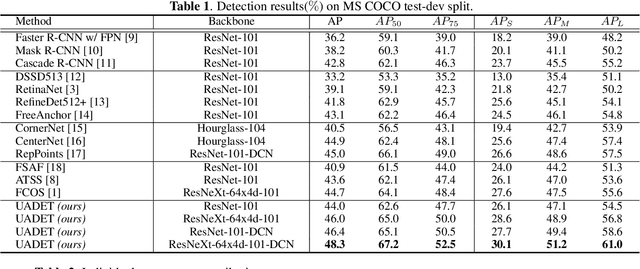
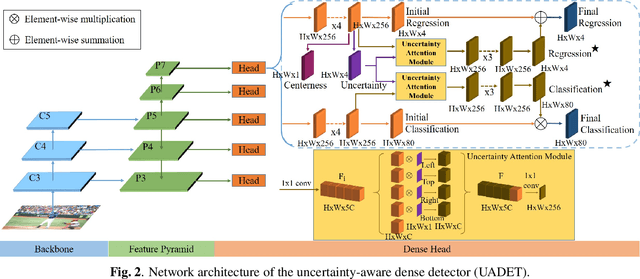
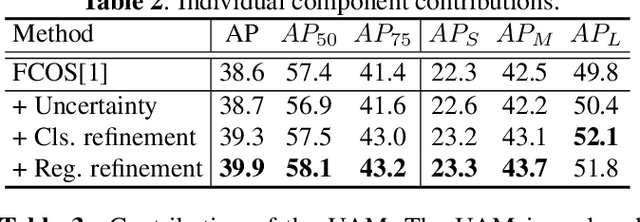
Object detection has been applied in a wide variety of real world scenarios, so detection algorithms must provide confidence in the results to ensure that appropriate decisions can be made based on their results. Accordingly, several studies have investigated the probabilistic confidence of bounding box regression. However, such approaches have been restricted to anchor-based detectors, which use box confidence values as additional screening scores during non-maximum suppression (NMS) procedures. In this paper, we propose a more efficient uncertainty-aware dense detector (UADET) that predicts four-directional localization uncertainties via Gaussian modeling. Furthermore, a simple uncertainty attention module (UAM) that exploits box confidence maps is proposed to improve performance through feature refinement. Experiments using the MS COCO benchmark show that our UADET consistently surpasses baseline FCOS, and that our best model, ResNext-64x4d-101-DCN, obtains a single model, single-scale AP of 48.3% on COCO test-dev, thus achieving the state-of-the-art among various object detectors.