 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Diversity in Zero-Shot GAN Adaptation with Semantic Variations
Aug 21, 2023Training deep generative models usually requires a large amount of data. To alleviate the data collection cost, the task of zero-shot GAN adaptation aims to reuse well-trained generators to synthesize images of an unseen target domain without any further training samples. Due to the data absence, the textual description of the target domain and the vision-language models, e.g., CLIP, are utilized to effectively guide the generator. However, with only a single representative text feature instead of real images, the synthesized images gradually lose diversity as the model is optimized, which is also known as mode collapse. To tackle the problem, we propose a novel method to find semantic variations of the target text in the CLIP space. Specifically, we explore diverse semantic variations based on the informative text feature of the target domain while regularizing the uncontrolled deviation of the semantic information. With the obtained variations, we design a novel directional moment loss that matches the first and second moments of image and text direction distributions. Moreover, we introduce elastic weight consolidation and a relation consistency loss to effectively preserve valuable content information from the source domain, e.g., appearances. Through extensive experiments, we demonstrate the efficacy of the proposed methods in ensuring sample diversity in various scenarios of zero-shot GAN adaptation. We also conduct ablation studies to validate the effect of each proposed component. Notably, our model achieves a new state-of-the-art on zero-shot GAN adaptation in terms of both diversity and quality.
AesPA-Net: Aesthetic Pattern-Aware Style Transfer Networks
Aug 08, 2023


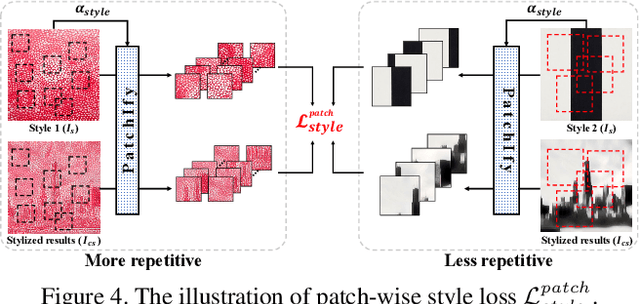
To deliver the artistic expression of the target style, recent studies exploit the attention mechanism owing to its ability to map the local patches of the style image to the corresponding patches of the content image. However, because of the low semantic correspondence between arbitrary content and artworks, the attention module repeatedly abuses specific local patches from the style image, resulting in disharmonious and evident repetitive artifacts. To overcome this limitation and accomplish impeccable artistic style transfer, we focus on enhancing the attention mechanism and capturing the rhythm of patterns that organize the style. In this paper, we introduce a novel metric, namely pattern repeatability, that quantifies the repetition of patterns in the style image. Based on the pattern repeatability, we propose Aesthetic Pattern-Aware style transfer Networks (AesPA-Net) that discover the sweet spot of local and global style expressions. In addition, we propose a novel self-supervisory task to encourage the attention mechanism to learn precise and meaningful semantic correspondence. Lastly, we introduce the patch-wise style loss to transfer the elaborate rhythm of local patterns. Through qualitative and quantitative evaluations, we verify the reliability of the proposed pattern repeatability that aligns with human perception, and demonstrate the superiority of the proposed framework.
Source-free Subject Adaptation for EEG-based Visual Recognition
Jan 20, 2023



This paper focuses on subject adaptation for EEG-based visual recognition. It aims at building a visual stimuli recognition system customized for the target subject whose EEG samples are limited, by transferring knowledge from abundant data of source subjects. Existing approaches consider the scenario that samples of source subjects are accessible during training. However, it is often infeasible and problematic to access personal biological data like EEG signals due to privacy issues. In this paper, we introduce a novel and practical problem setup, namely source-free subject adaptation, where the source subject data are unavailable and only the pre-trained model parameters are provided for subject adaptation. To tackle this challenging problem, we propose classifier-based data generation to simulate EEG samples from source subjects using classifier responses. Using the generated samples and target subject data, we perform subject-independent feature learning to exploit the common knowledge shared across different subjects. Notably, our framework is generalizable and can adopt any subject-independent learning method. In the experiments on the EEG-ImageNet40 benchmark, our model brings consistent improvements regardless of the choice of subject-independent learning. Also, our method shows promising performance, recording top-1 test accuracy of 74.6% under the 5-shot setting even without relying on source data. Our code can be found at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Source_Free_Subject_Adaptation_for_EEG.
Exploiting Domain Transferability for Collaborative Inter-level Domain Adaptive Object Detection
Jul 20, 2022
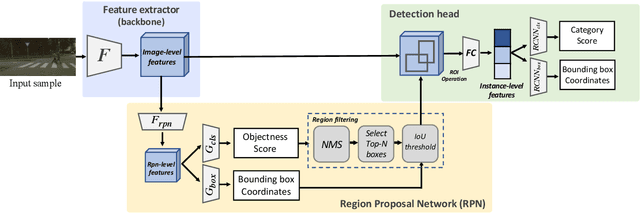
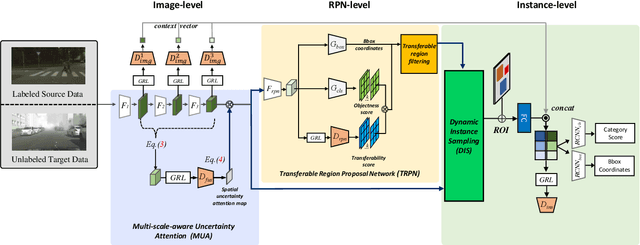
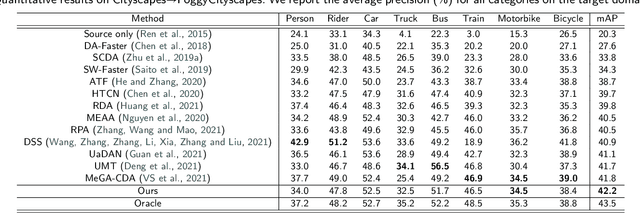
Domain adaptation for object detection (DAOD) has recently drawn much attention owing to its capability of detecting target objects without any annotations. To tackle the problem, previous works focus on aligning features extracted from partial levels (e.g., image-level, instance-level, RPN-level) in a two-stage detector via adversarial training. However, individual levels in the object detection pipeline are closely related to each other and this inter-level relation is unconsidered yet. To this end, we introduce a novel framework for DAOD with three proposed components: Multi-scale-aware Uncertainty Attention (MUA), Transferable Region Proposal Network (TRPN), and Dynamic Instance Sampling (DIS). With these modules, we seek to reduce the negative transfer effect during training while maximizing transferability as well as discriminability in both domains. Finally, our framework implicitly learns domain invariant regions for object detection via exploiting the transferable information and enhances the complementarity between different detection levels by collaboratively utilizing their domain information. Through ablation studies and experiments, we show that the proposed modules contribute to the performance improvement in a synergic way, demonstrating the effectiveness of our method. Moreover, our model achieves a new state-of-the-art performance on various benchmarks.
* Accepted to Expert Systems with Applications. The first three authors contributed equally
Inter-subject Contrastive Learning for Subject Adaptive EEG-based Visual Recognition
Feb 07, 2022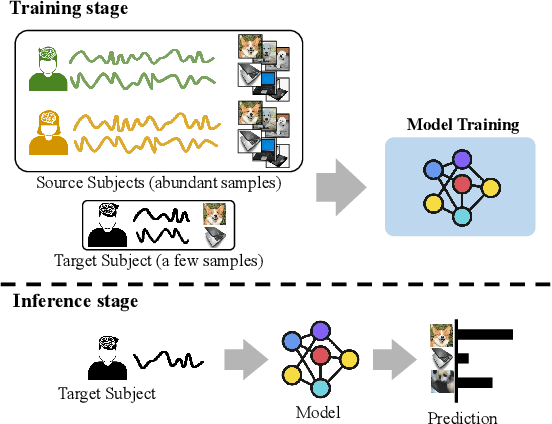
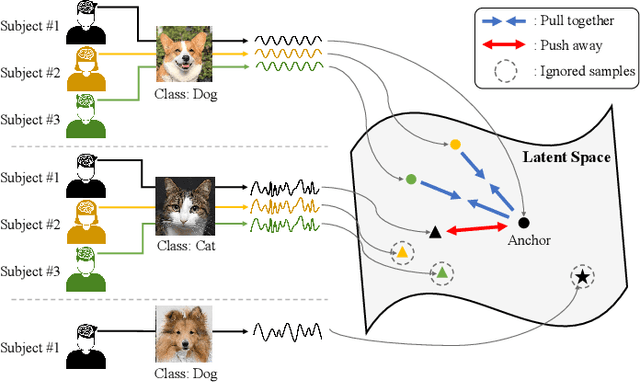
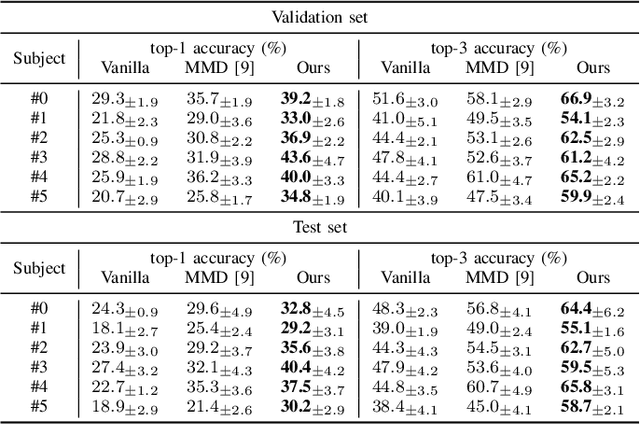
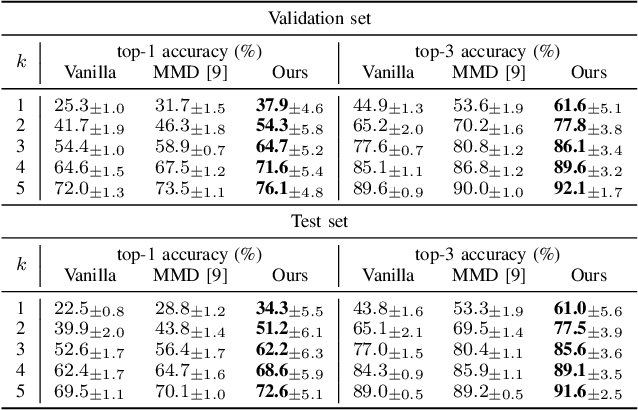
This paper tackles the problem of subject adaptive EEG-based visual recognition. Its goal is to accurately predict the categories of visual stimuli based on EEG signals with only a handful of samples for the target subject during training. The key challenge is how to appropriately transfer the knowledge obtained from abundant data of source subjects to the subject of interest. To this end, we introduce a novel method that allows for learning subject-independent representation by increasing the similarity of features sharing the same class but coming from different subjects. With the dedicated sampling principle, our model effectively captures the common knowledge shared across different subjects, thereby achieving promising performance for the target subject even under harsh problem settings with limited data. Specifically, on the EEG-ImageNet40 benchmark, our model records the top-1 / top-3 test accuracy of 72.6% / 91.6% when using only five EEG samples per class for the target subject. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Inter_Subject_Contrastive_Learning_for_EEG.
Subject Adaptive EEG-based Visual Recognition
Oct 26, 2021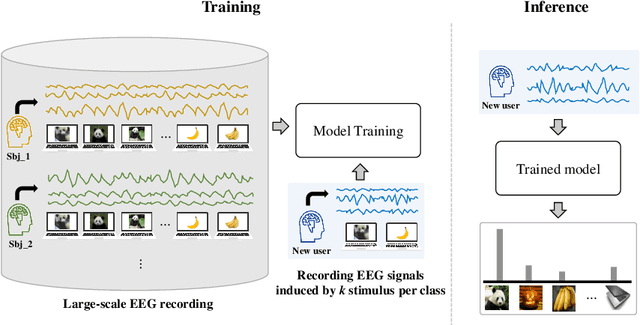
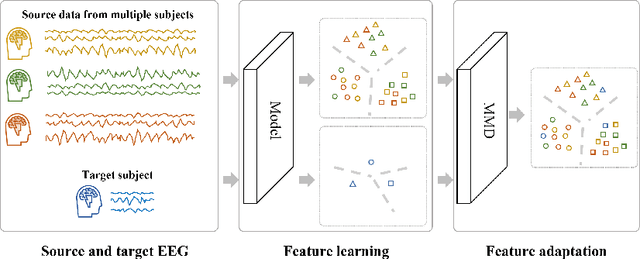
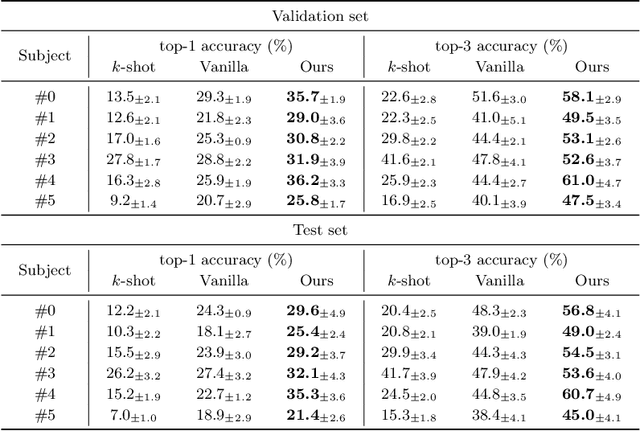
This paper focuses on EEG-based visual recognition, aiming to predict the visual object class observed by a subject based on his/her EEG signals. One of the main challenges is the large variation between signals from different subjects. It limits recognition systems to work only for the subjects involved in model training, which is undesirable for real-world scenarios where new subjects are frequently added. This limitation can be alleviated by collecting a large amount of data for each new user, yet it is costly and sometimes infeasible. To make the task more practical, we introduce a novel problem setting, namely subject adaptive EEG-based visual recognition. In this setting, a bunch of pre-recorded data of existing users (source) is available, while only a little training data from a new user (target) are provided. At inference time, the model is evaluated solely on the signals from the target user. This setting is challenging, especially because training samples from source subjects may not be helpful when evaluating the model on the data from the target subject. To tackle the new problem, we design a simple yet effective baseline that minimizes the discrepancy between feature distributions from different subjects, which allows the model to extract subject-independent features. Consequently, our model can learn the common knowledge shared among subjects, thereby significantly improving the recognition performance for the target subject. In the experiments, we demonstrate the effectiveness of our method under various settings. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Subject_Adaptive_EEG_based_Visual_Recognition.
Feature Stylization and Domain-aware Contrastive Learning for Domain Generalization
Aug 19, 2021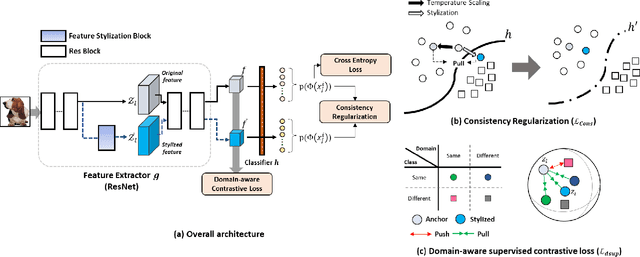
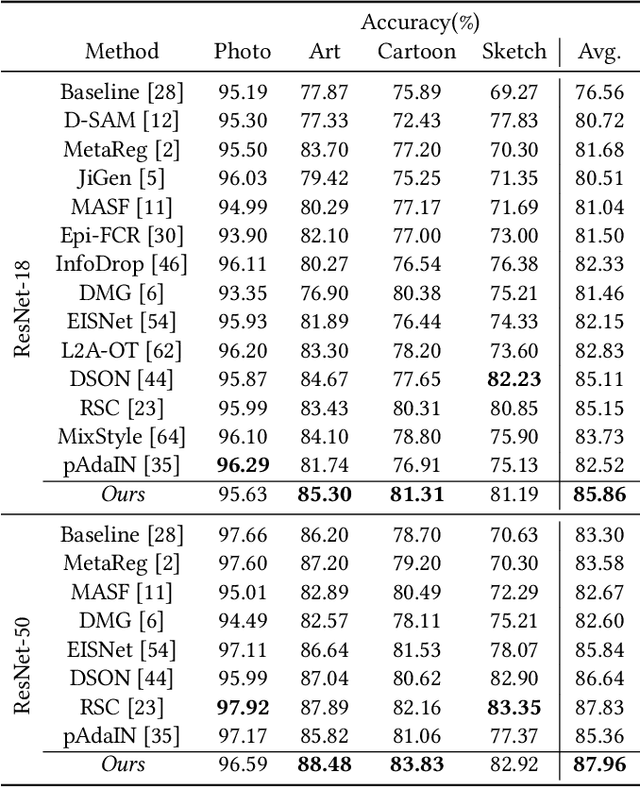
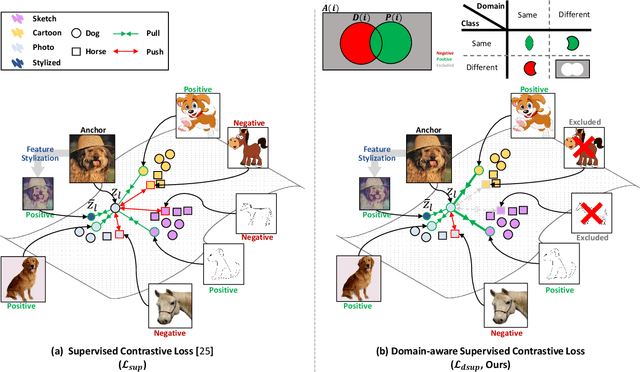
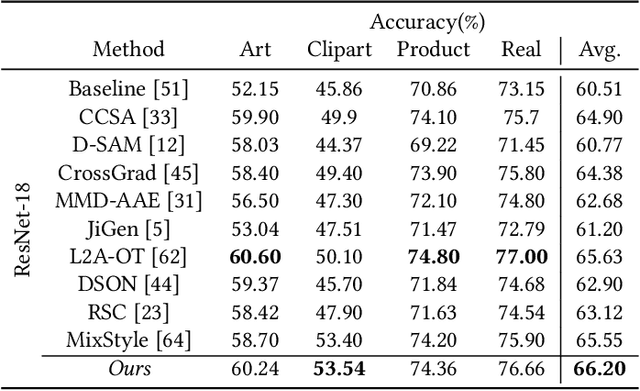
Domain generalization aims to enhance the model robustness against domain shift without accessing the target domain. Since the available source domains for training are limited, recent approaches focus on generating samples of novel domains. Nevertheless, they either struggle with the optimization problem when synthesizing abundant domains or cause the distortion of class semantics. To these ends, we propose a novel domain generalization framework where feature statistics are utilized for stylizing original features to ones with novel domain properties. To preserve class information during stylization, we first decompose features into high and low frequency components. Afterward, we stylize the low frequency components with the novel domain styles sampled from the manipulated statistics, while preserving the shape cues in high frequency ones. As the final step, we re-merge both components to synthesize novel domain features. To enhance domain robustness, we utilize the stylized features to maintain the model consistency in terms of features as well as outputs. We achieve the feature consistency with the proposed domain-aware supervised contrastive loss, which ensures domain invariance while increasing class discriminability. Experimental results demonstrate the effectiveness of the proposed feature stylization and the domain-aware contrastive loss. Through quantitative comparisons, we verify the lead of our method upon existing state-of-the-art methods on two benchmarks, PACS and Office-Home.
Domain-Aware Universal Style Transfer
Aug 17, 2021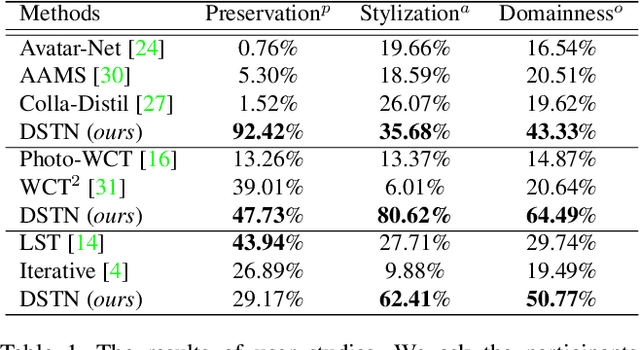
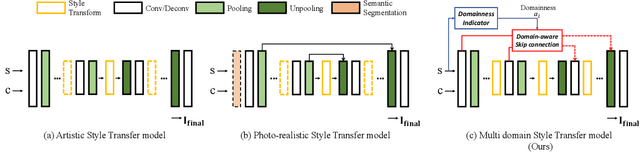
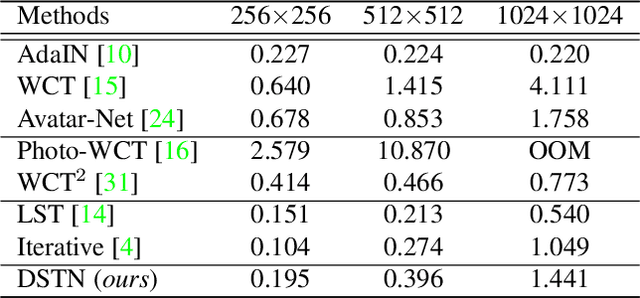
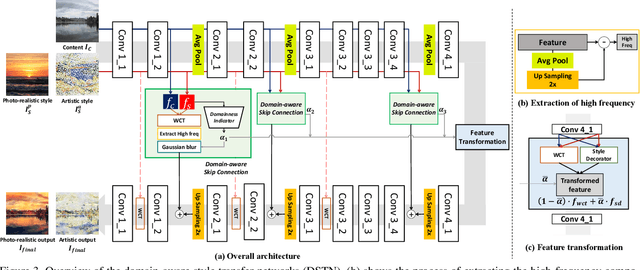
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Continuous Face Aging Generative Adversarial Networks
Feb 26, 2021
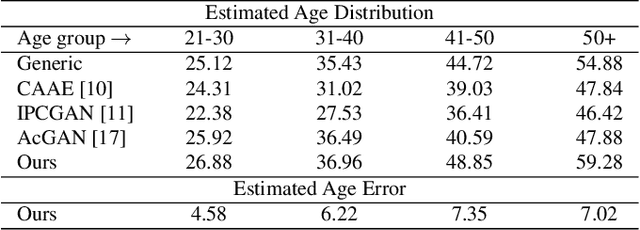
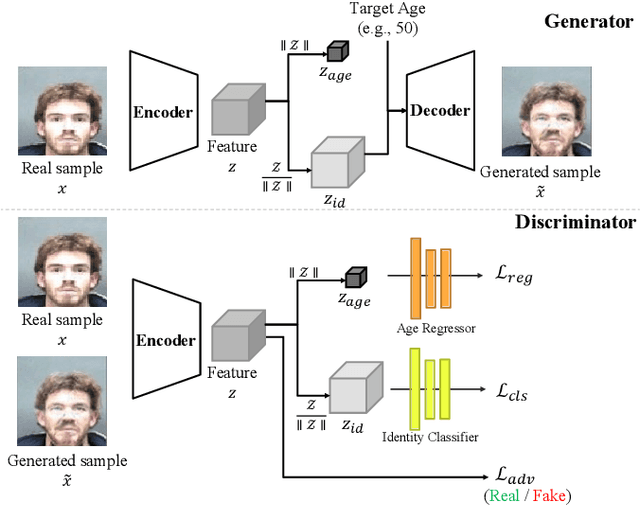
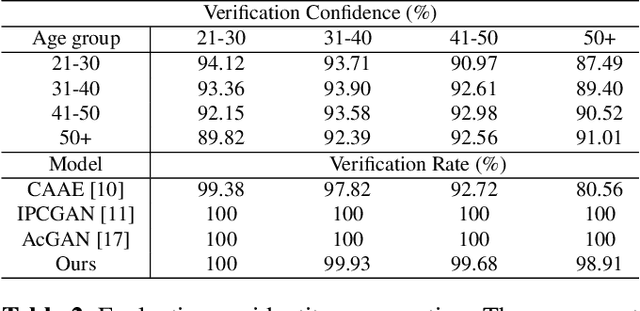
Face aging is the task aiming to translate the faces in input images to designated ages. To simplify the problem, previous methods have limited themselves only able to produce discrete age groups, each of which consists of ten years. Consequently, the exact ages of the translated results are unknown and it is unable to obtain the faces of different ages within groups. To this end, we propose the continuous face aging generative adversarial networks (CFA-GAN). Specifically, to make the continuous aging feasible, we propose to decompose image features into two orthogonal features: the identity and the age basis features. Moreover, we introduce the novel loss function for identity preservation which maximizes the cosine similarity between the original and the generated identity basis features. With the qualitative and quantitative evaluations on MORPH, we demonstrate the realistic and continuous aging ability of our model, validating its superiority against existing models. To the best of our knowledge, this work is the first attempt to handle continuous target ages.