 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-free Subject Adaptation for EEG-based Visual Recognition
Jan 20, 2023



This paper focuses on subject adaptation for EEG-based visual recognition. It aims at building a visual stimuli recognition system customized for the target subject whose EEG samples are limited, by transferring knowledge from abundant data of source subjects. Existing approaches consider the scenario that samples of source subjects are accessible during training. However, it is often infeasible and problematic to access personal biological data like EEG signals due to privacy issues. In this paper, we introduce a novel and practical problem setup, namely source-free subject adaptation, where the source subject data are unavailable and only the pre-trained model parameters are provided for subject adaptation. To tackle this challenging problem, we propose classifier-based data generation to simulate EEG samples from source subjects using classifier responses. Using the generated samples and target subject data, we perform subject-independent feature learning to exploit the common knowledge shared across different subjects. Notably, our framework is generalizable and can adopt any subject-independent learning method. In the experiments on the EEG-ImageNet40 benchmark, our model brings consistent improvements regardless of the choice of subject-independent learning. Also, our method shows promising performance, recording top-1 test accuracy of 74.6% under the 5-shot setting even without relying on source data. Our code can be found at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Source_Free_Subject_Adaptation_for_EEG.
Fair Contrastive Learning for Facial Attribute Classification
Mar 30, 2022
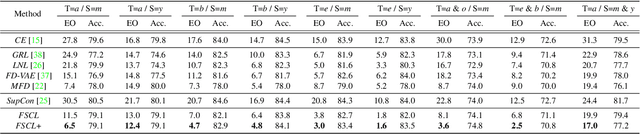
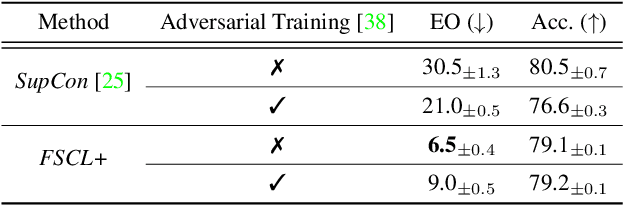
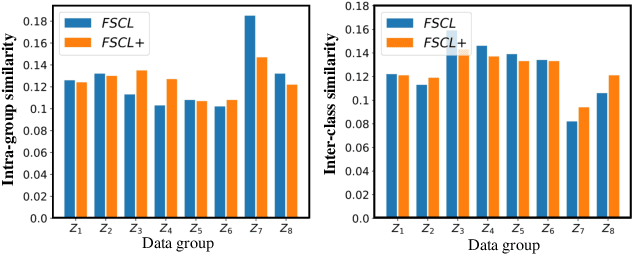
Learning visual representation of high quality is essential for image classification. Recently, a series of contrastive representation learning methods have achieved preeminent success. Particularly, SupCon outperformed the dominant methods based on cross-entropy loss in representation learning. However, we notice that there could be potential ethical risks in supervised contrastive learning. In this paper, we for the first time analyze unfairness caused by supervised contrastive learning and propose a new Fair Supervised Contrastive Loss (FSCL) for fair visual representation learning. Inheriting the philosophy of supervised contrastive learning, it encourages representation of the same class to be closer to each other than that of different classes, while ensuring fairness by penalizing the inclusion of sensitive attribute information in representation. In addition, we introduce a group-wise normalization to diminish the disparities of intra-group compactness and inter-class separability between demographic groups that arouse unfair classification. Through extensive experiments on CelebA and UTK Face, we validate that the proposed method significantly outperforms SupCon and existing state-of-the-art methods in terms of the trade-off between top-1 accuracy and fairness. Moreover, our method is robust to the intensity of data bias and effectively works in incomplete supervised settings. Our code is available at https://github.com/sungho-CoolG/FSCL.
Cut and Continuous Paste towards Real-time Deep Fall Detection
Feb 22, 2022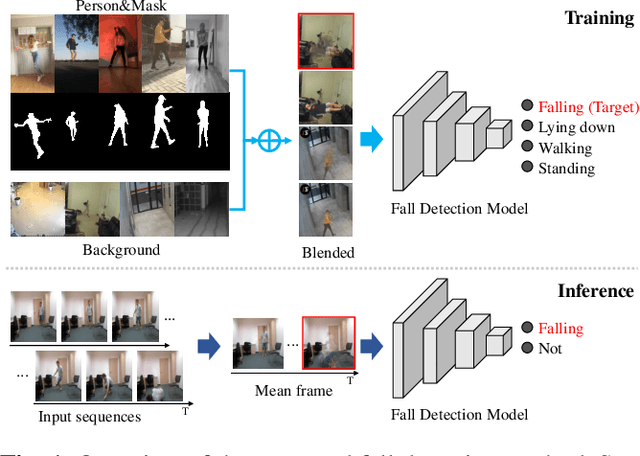
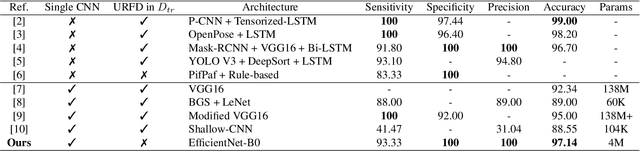

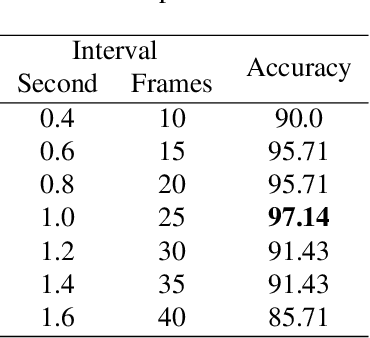
Deep learning based fall detection is one of the crucial tasks for intelligent video surveillance systems, which aims to detect unintentional falls of humans and alarm dangerous situations. In this work, we propose a simple and efficient framework to detect falls through a single and small-sized convolutional neural network. To this end, we first introduce a new image synthesis method that represents human motion in a single frame. This simplifies the fall detection task as an image classification task. Besides, the proposed synthetic data generation method enables to generate a sufficient amount of training dataset, resulting in satisfactory performance even with the small model. At the inference step, we also represent real human motion in a single image by estimating mean of input frames. In the experiment, we conduct both qualitative and quantitative evaluations on URFD and AIHub airport datasets to show the effectiveness of our method.
Inter-subject Contrastive Learning for Subject Adaptive EEG-based Visual Recognition
Feb 07, 2022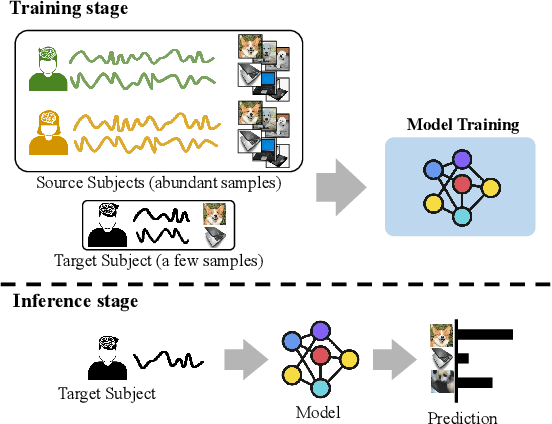
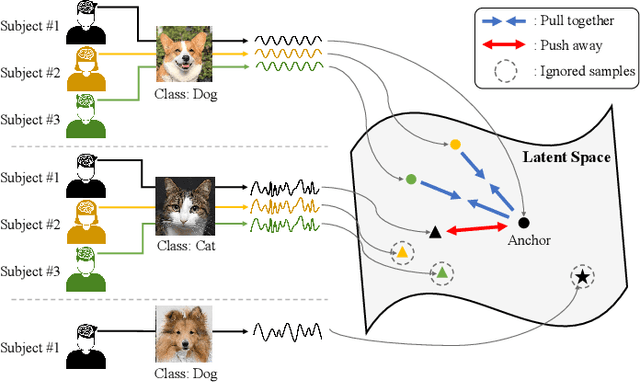
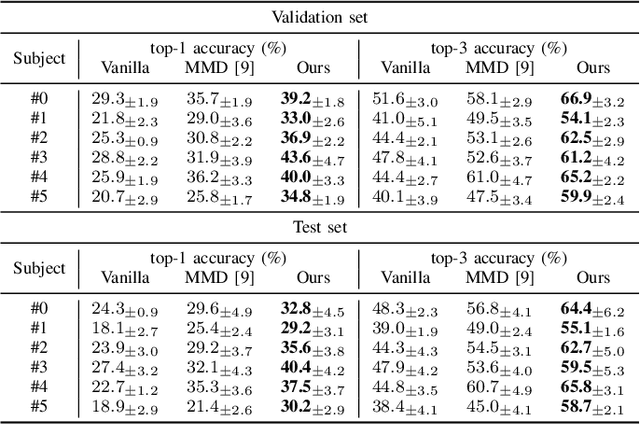
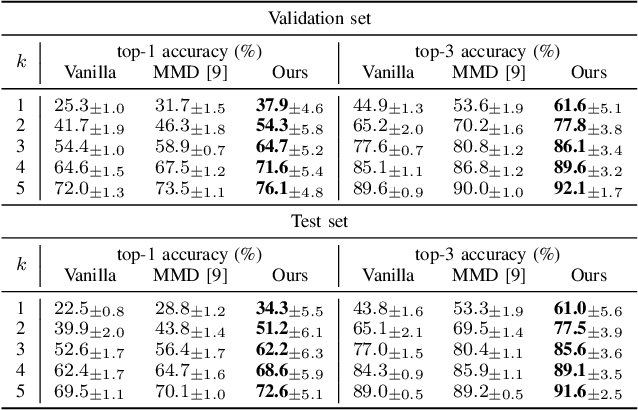
This paper tackles the problem of subject adaptive EEG-based visual recognition. Its goal is to accurately predict the categories of visual stimuli based on EEG signals with only a handful of samples for the target subject during training. The key challenge is how to appropriately transfer the knowledge obtained from abundant data of source subjects to the subject of interest. To this end, we introduce a novel method that allows for learning subject-independent representation by increasing the similarity of features sharing the same class but coming from different subjects. With the dedicated sampling principle, our model effectively captures the common knowledge shared across different subjects, thereby achieving promising performance for the target subject even under harsh problem settings with limited data. Specifically, on the EEG-ImageNet40 benchmark, our model records the top-1 / top-3 test accuracy of 72.6% / 91.6% when using only five EEG samples per class for the target subject. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Inter_Subject_Contrastive_Learning_for_EEG.
Subject Adaptive EEG-based Visual Recognition
Oct 26, 2021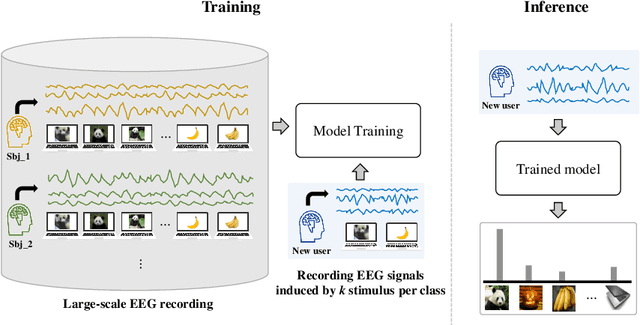
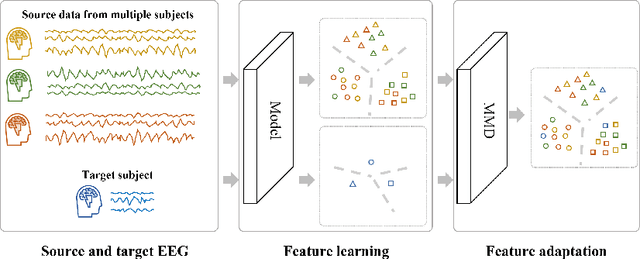
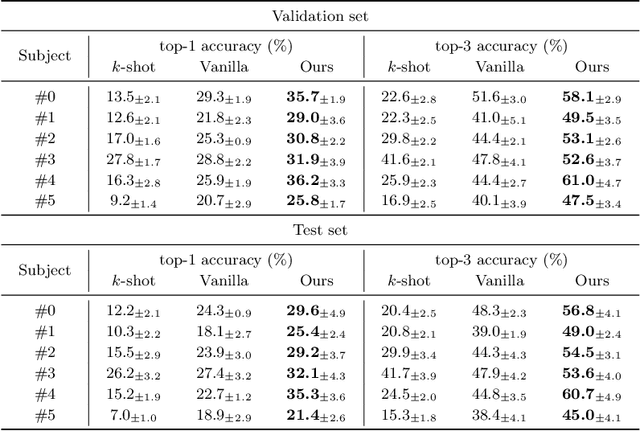
This paper focuses on EEG-based visual recognition, aiming to predict the visual object class observed by a subject based on his/her EEG signals. One of the main challenges is the large variation between signals from different subjects. It limits recognition systems to work only for the subjects involved in model training, which is undesirable for real-world scenarios where new subjects are frequently added. This limitation can be alleviated by collecting a large amount of data for each new user, yet it is costly and sometimes infeasible. To make the task more practical, we introduce a novel problem setting, namely subject adaptive EEG-based visual recognition. In this setting, a bunch of pre-recorded data of existing users (source) is available, while only a little training data from a new user (target) are provided. At inference time, the model is evaluated solely on the signals from the target user. This setting is challenging, especially because training samples from source subjects may not be helpful when evaluating the model on the data from the target subject. To tackle the new problem, we design a simple yet effective baseline that minimizes the discrepancy between feature distributions from different subjects, which allows the model to extract subject-independent features. Consequently, our model can learn the common knowledge shared among subjects, thereby significantly improving the recognition performance for the target subject. In the experiments, we demonstrate the effectiveness of our method under various settings. Our code is available at https://github.com/DeepBCI/Deep-BCI/tree/master/1_Intelligent_BCI/Subject_Adaptive_EEG_based_Visual_Recognition.
FairFaceGAN: Fairness-aware Facial Image-to-Image Translation
Dec 02, 2020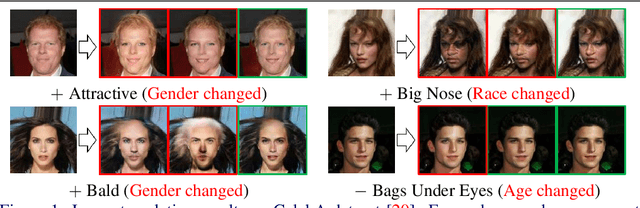

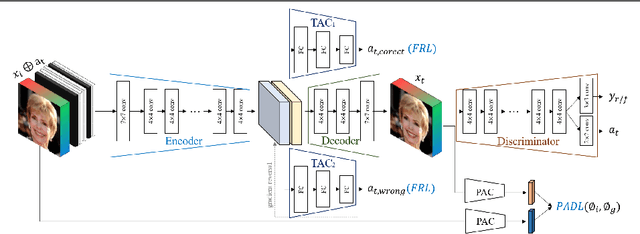
In this paper, we introduce FairFaceGAN, a fairness-aware facial Image-to-Image translation model, mitigating the problem of unwanted translation in protected attributes (e.g., gender, age, race) during facial attributes editing. Unlike existing models, FairFaceGAN learns fair representations with two separate latents - one related to the target attributes to translate, and the other unrelated to them. This strategy enables FairFaceGAN to separate the information about protected attributes and that of target attributes. It also prevents unwanted translation in protected attributes while target attributes editing. To evaluate the degree of fairness, we perform two types of experiments on CelebA dataset. First, we compare the fairness-aware classification performances when augmenting data by existing image translation methods and FairFaceGAN respectively. Moreover, we propose a new fairness metric, namely Frechet Protected Attribute Distance (FPAD), which measures how well protected attributes are preserved. Experimental results demonstrate that FairFaceGAN shows consistent improvements in terms of fairness over the existing image translation models. Further, we also evaluate image translation performances, where FairFaceGAN shows competitive results, compared to those of existing methods.
README: REpresentation learning by fairness-Aware Disentangling MEthod
Jul 07, 2020



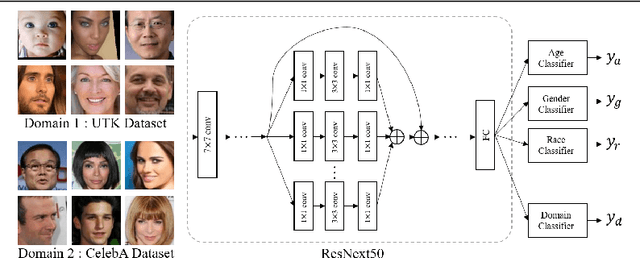
Fair representation learning aims to encode invariant representation with respect to the protected attribute, such as gender or age. In this paper, we design Fairness-aware Disentangling Variational AutoEncoder (FD-VAE) for fair representation learning. This network disentangles latent space into three subspaces with a decorrelation loss that encourages each subspace to contain independent information: 1) target attribute information, 2) protected attribute information, 3) mutual attribute information. After the representation learning, this disentangled representation is leveraged for fairer downstream classification by excluding the subspace with the protected attribute information. We demonstrate the effectiveness of our model through extensive experiments on CelebA and UTK Face datasets. Our method outperforms the previous state-of-the-art method by large margins in terms of equal opportunity and equalized odds.