 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinPool: Reinforcement Learning Pooling Multi-Vector Embeddings for Retrieval System
Jan 12, 2026Multi-vector embedding models have emerged as a powerful paradigm for document retrieval, preserving fine-grained visual and textual details through token-level representations. However, this expressiveness comes at a staggering cost: storing embeddings for every token inflates index sizes by over $1000\times$ compared to single-vector approaches, severely limiting scalability. We introduce \textbf{ReinPool}, a reinforcement learning framework that learns to dynamically filter and pool multi-vector embeddings into compact, retrieval-optimized representations. By training with an inverse retrieval objective and NDCG-based rewards, ReinPool identifies and retains only the most discriminative vectors without requiring manual importance annotations. On the Vidore V2 benchmark across three vision-language embedding models, ReinPool compresses multi-vector representations by $746$--$1249\times$ into single vectors while recovering 76--81\% of full multi-vector retrieval performance. Compared to static mean pooling baselines, ReinPool achieves 22--33\% absolute NDCG@3 improvement, demonstrating that learned selection significantly outperforms heuristic aggregation.
Efficient Industrial sLLMs through Domain Adaptive Continual Pretraining: Method, Evaluation and Applications
Jul 09, 2025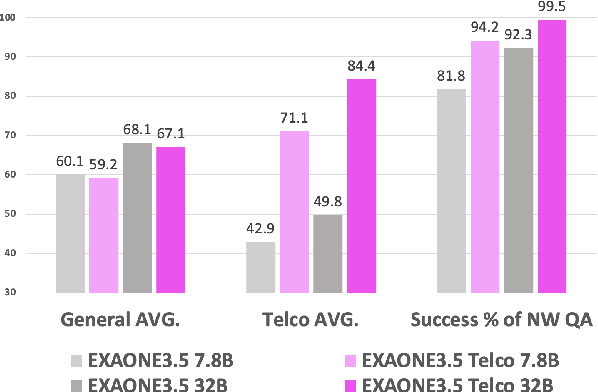
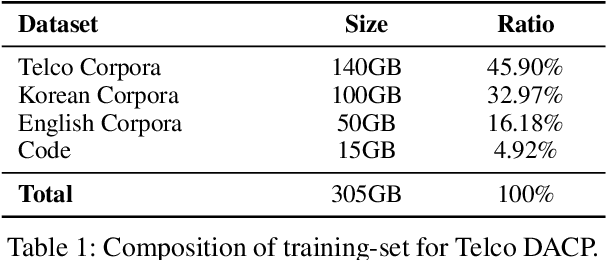
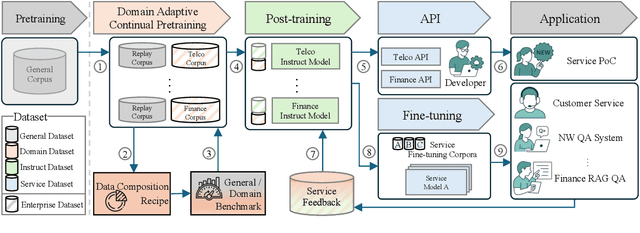
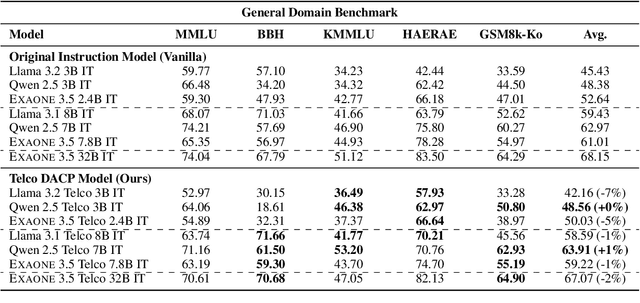
The emergence of open-source large language models (LLMs) has expanded opportunities for enterprise applications; however, many organizations still lack the infrastructure to deploy and maintain large-scale models. As a result, small LLMs (sLLMs) have become a practical alternative, despite their inherent performance limitations. While Domain Adaptive Continual Pretraining (DACP) has been previously explored as a method for domain adaptation, its utility in commercial applications remains under-examined. In this study, we validate the effectiveness of applying a DACP-based recipe across diverse foundation models and service domains. Through extensive experiments and real-world evaluations, we demonstrate that DACP-applied sLLMs achieve substantial gains in target domain performance while preserving general capabilities, offering a cost-efficient and scalable solution for enterprise-level deployment.
Leveraging Speaker Embeddings with Adversarial Multi-task Learning for Age Group Classification
Jan 22, 2023



Recently, researchers have utilized neural network-based speaker embedding techniques in speaker-recognition tasks to identify speakers accurately. However, speaker-discriminative embeddings do not always represent speech features such as age group well. In an embedding model that has been highly trained to capture speaker traits, the task of age group classification is closer to speech information leakage. Hence, to improve age group classification performance, we consider the use of speaker-discriminative embeddings derived from adversarial multi-task learning to align features and reduce the domain discrepancy in age subgroups. In addition, we investigated different types of speaker embeddings to learn and generalize the domain-invariant representations for age groups. Experimental results on the VoxCeleb Enrichment dataset verify the effectiveness of our proposed adaptive adversarial network in multi-objective scenarios and leveraging speaker embeddings for the domain adaptation task.
Cut and Continuous Paste towards Real-time Deep Fall Detection
Feb 22, 2022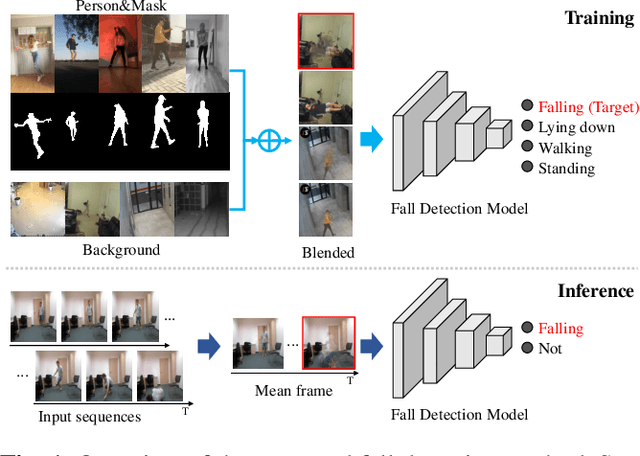
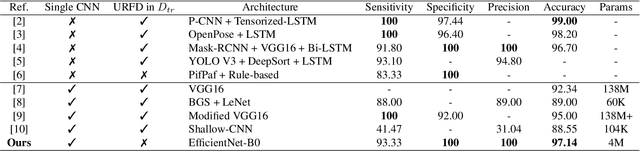

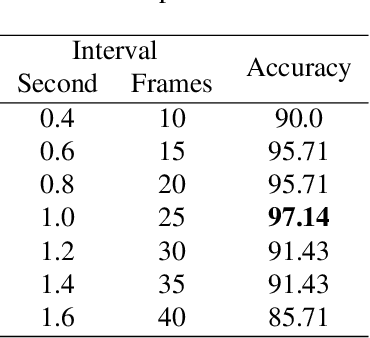
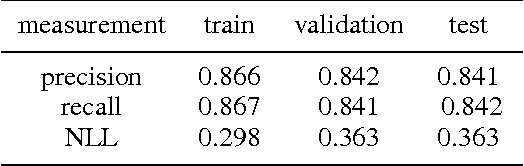
Deep learning based fall detection is one of the crucial tasks for intelligent video surveillance systems, which aims to detect unintentional falls of humans and alarm dangerous situations. In this work, we propose a simple and efficient framework to detect falls through a single and small-sized convolutional neural network. To this end, we first introduce a new image synthesis method that represents human motion in a single frame. This simplifies the fall detection task as an image classification task. Besides, the proposed synthetic data generation method enables to generate a sufficient amount of training dataset, resulting in satisfactory performance even with the small model. At the inference step, we also represent real human motion in a single image by estimating mean of input frames. In the experiment, we conduct both qualitative and quantitative evaluations on URFD and AIHub airport datasets to show the effectiveness of our method.
Visual Fashion-Product Search at SK Planet
Apr 12, 2017


We build a large-scale visual search system which finds similar product images given a fashion item. Defining similarity among arbitrary fashion-products is still remains a challenging problem, even there is no exact ground-truth. To resolve this problem, we define more than 90 fashion-related attributes, and combination of these attributes can represent thousands of unique fashion-styles. The fashion-attributes are one of the ingredients to define semantic similarity among fashion-product images. To build our system at scale, these fashion-attributes are again used to build an inverted indexing scheme. In addition to these fashion-attributes for semantic similarity, we extract colour and appearance features in a region-of-interest (ROI) of a fashion item for visual similarity. By sharing our approach, we expect active discussion on that how to apply current computer vision research into the e-commerce industry.