 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeven Security Challenges That Must be Solved in Cross-domain Multi-agent LLM Systems
May 28, 2025

Large language models (LLMs) are rapidly evolving into autonomous agents that cooperate across organizational boundaries, enabling joint disaster response, supply-chain optimization, and other tasks that demand decentralized expertise without surrendering data ownership. Yet, cross-domain collaboration shatters the unified trust assumptions behind current alignment and containment techniques. An agent benign in isolation may, when receiving messages from an untrusted peer, leak secrets or violate policy, producing risks driven by emergent multi-agent dynamics rather than classical software bugs. This position paper maps the security agenda for cross-domain multi-agent LLM systems. We introduce seven categories of novel security challenges, for each of which we also present plausible attacks, security evaluation metrics, and future research guidelines.
Predicting Chemical Reaction Outcomes Based on Electron Movements Using Machine Learning
Mar 13, 2025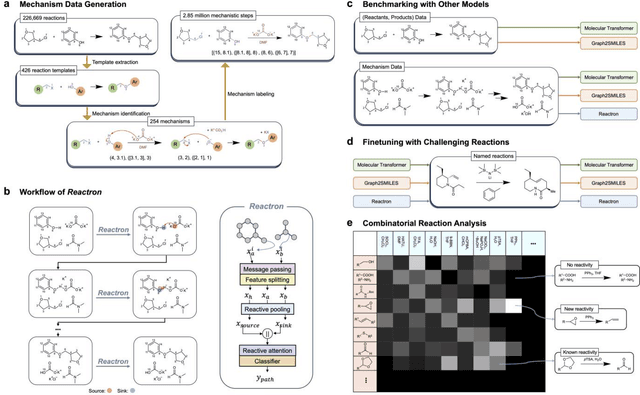
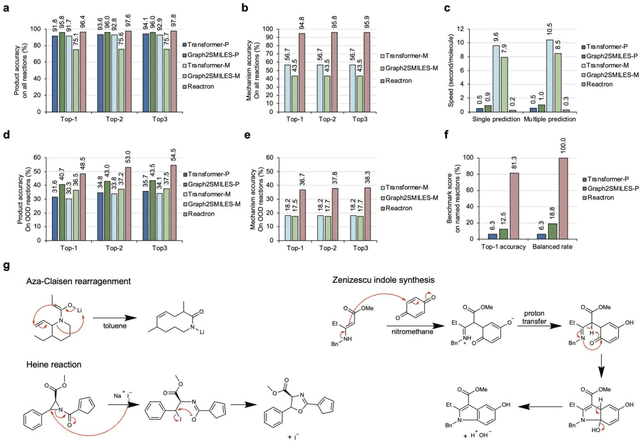
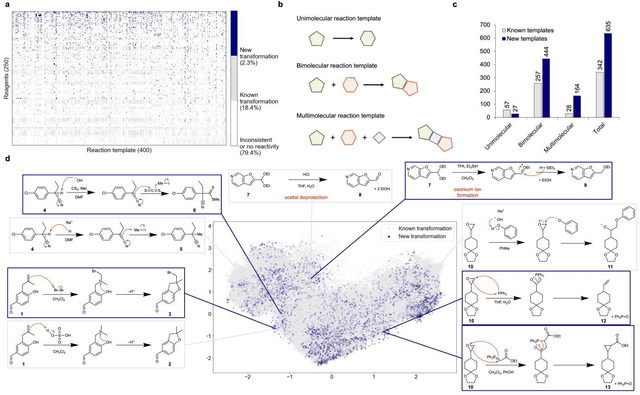
Accurately predicting chemical reaction outcomes and potential byproducts is a fundamental task of modern chemistry, enabling the efficient design of synthetic pathways and driving progress in chemical science. Reaction mechanism, which tracks electron movements during chemical reactions, is critical for understanding reaction kinetics and identifying unexpected products. Here, we present Reactron, the first electron-based machine learning model for general reaction prediction. Reactron integrates electron movement into its predictions, generating detailed arrow-pushing diagrams that elucidate each mechanistic step leading to product formation. We demonstrate the high predictive performance of Reactron over existing product-only models by a large-scale reaction outcome prediction benchmark, and the adaptability of the model to learn new reactivity upon providing a few examples. Furthermore, it explores combinatorial reaction spaces, uncovering novel reactivities beyond its training data. With robust performance in both in- and out-of-distribution predictions, Reactron embodies human-like reasoning in chemistry and opens new frontiers in reaction discovery and synthesis design.
MindfulDiary: Harnessing Large Language Model to Support Psychiatric Patients' Journaling
Oct 08, 2023In the mental health domain, Large Language Models (LLMs) offer promising new opportunities, though their inherent complexity and low controllability have raised questions about their suitability in clinical settings. We present MindfulDiary, a mobile journaling app incorporating an LLM to help psychiatric patients document daily experiences through conversation. Designed in collaboration with mental health professionals (MHPs), MindfulDiary takes a state-based approach to safely comply with the experts' guidelines while carrying on free-form conversations. Through a four-week field study involving 28 patients with major depressive disorder and five psychiatrists, we found that MindfulDiary supported patients in consistently enriching their daily records and helped psychiatrists better empathize with their patients through an understanding of their thoughts and daily contexts. Drawing on these findings, we discuss the implications of leveraging LLMs in the mental health domain, bridging the technical feasibility and their integration into clinical settings.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
Guided Policy Search using Sequential Convex Programming for Initialization of Trajectory Optimization Algorithms
Oct 13, 2021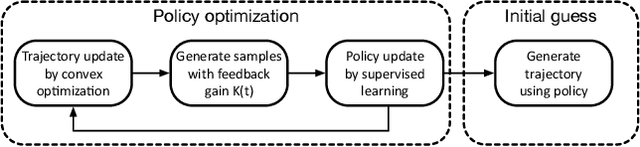

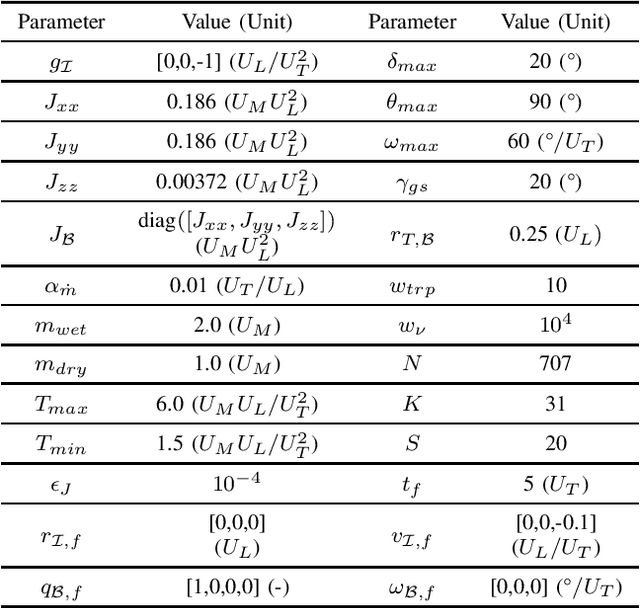
Nonlinear trajectory optimization algorithms have been developed to handle optimal control problems with nonlinear dynamics and nonconvex constraints in trajectory planning. The performance and computational efficiency of many trajectory optimization methods are sensitive to the initial guess, i.e., the trajectory guess needed by the recursive trajectory optimization algorithm. Motivated by this observation, we tackle the initialization problem for trajectory optimization via policy optimization. To optimize a policy, we propose a guided policy search method that has two key components: i) Trajectory update; ii) Policy update. The trajectory update involves offline solutions of a large number of trajectory optimization problems from different initial states via Sequential Convex Programming (SCP). Here we take a single SCP step to generate the trajectory iterate for each problem. In conjunction with these iterates, we also generate additional trajectories around each iterate via a feedback control law. Then all these trajectories are used by a stochastic gradient descent algorithm to update the neural network policy, i.e., the policy update step. As a result, the trained policy makes it possible to generate trajectory candidates that are close to the optimality and feasibility and that provide excellent initial guesses for the trajectory optimization methods. We validate the proposed method via a real-world 6-degree-of-freedom powered descent guidance problem for a reusable rocket.
On Single Source Robustness in Deep Fusion Models
Jun 11, 2019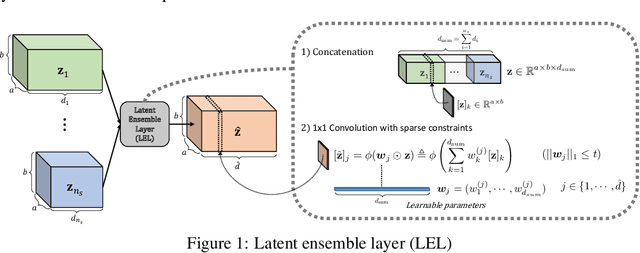
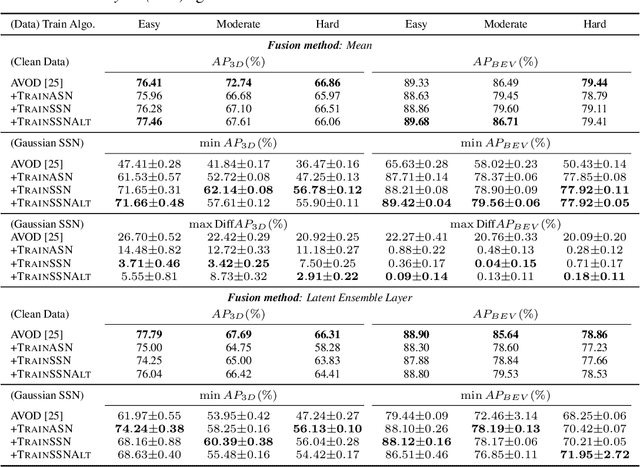


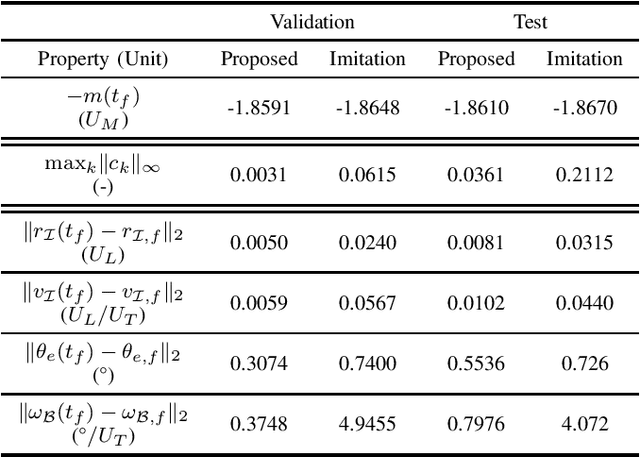
Algorithms that fuse multiple input sources benefit from both complementary and shared information. Shared information may provide robustness to faulty or noisy inputs, which is indispensable for safety-critical applications like self-driving cars. We investigate learning fusion algorithms that are robust against noise added to a single source. We first demonstrate that robustness against single source noise is not guaranteed in a linear fusion model. Motivated by this discovery, two possible approaches are proposed to increase robustness: a carefully designed loss with corresponding training algorithms for deep fusion models, and a simple convolutional fusion layer that has a structural advantage in dealing with noise. Experimental results show that both training algorithms and our fusion layer make a deep fusion-based 3D object detector robust against noise applied to a single source, while preserving the original performance on clean data.
Relaxed Oracles for Semi-Supervised Clustering
Nov 20, 2017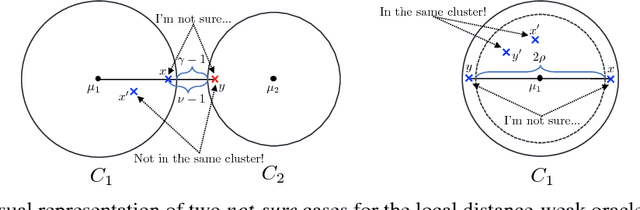
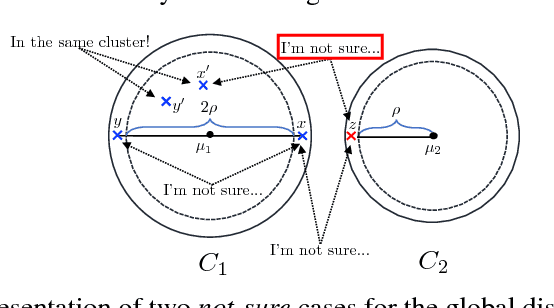
Pairwise "same-cluster" queries are one of the most widely used forms of supervision in semi-supervised clustering. However, it is impractical to ask human oracles to answer every query correctly. In this paper, we study the influence of allowing "not-sure" answers from a weak oracle and propose an effective algorithm to handle such uncertainties in query responses. Two realistic weak oracle models are considered where ambiguity in answering depends on the distance between two points. We show that a small query complexity is adequate for effective clustering with high probability by providing better pairs to the weak oracle. Experimental results on synthetic and real data show the effectiveness of our approach in overcoming supervision uncertainties and yielding high quality clusters.
Semi-Supervised Active Clustering with Weak Oracles
Sep 11, 2017



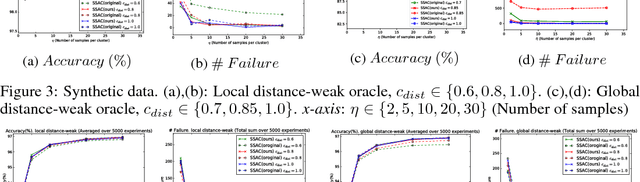
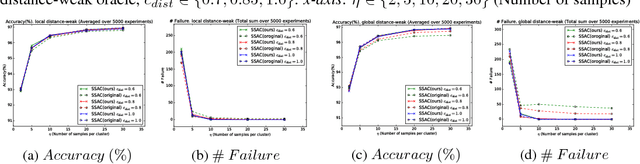
Semi-supervised active clustering (SSAC) utilizes the knowledge of a domain expert to cluster data points by interactively making pairwise "same-cluster" queries. However, it is impractical to ask human oracles to answer every pairwise query. In this paper, we study the influence of allowing "not-sure" answers from a weak oracle and propose algorithms to efficiently handle uncertainties. Different types of model assumptions are analyzed to cover realistic scenarios of oracle abstraction. In the first model, random-weak oracle, an oracle randomly abstains with a certain probability. We also proposed two distance-weak oracle models which simulate the case of getting confused based on the distance between two points in a pairwise query. For each weak oracle model, we show that a small query complexity is adequate for the effective $k$ means clustering with high probability. Sufficient conditions for the guarantee include a $\gamma$-margin property of the data, and an existence of a point close to each cluster center. Furthermore, we provide a sample complexity with a reduced effect of the cluster's margin and only a logarithmic dependency on the data dimension. Our results allow significantly less number of same-cluster queries if the margin of the clusters is tight, i.e. $\gamma \approx 1$. Experimental results on synthetic data show the effective performance of our approach in overcoming uncertainties.
Visual Fashion-Product Search at SK Planet
Apr 12, 2017


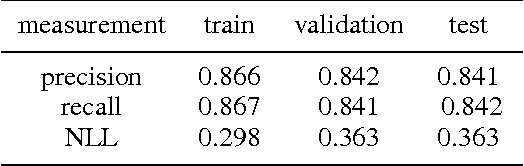
We build a large-scale visual search system which finds similar product images given a fashion item. Defining similarity among arbitrary fashion-products is still remains a challenging problem, even there is no exact ground-truth. To resolve this problem, we define more than 90 fashion-related attributes, and combination of these attributes can represent thousands of unique fashion-styles. The fashion-attributes are one of the ingredients to define semantic similarity among fashion-product images. To build our system at scale, these fashion-attributes are again used to build an inverted indexing scheme. In addition to these fashion-attributes for semantic similarity, we extract colour and appearance features in a region-of-interest (ROI) of a fashion item for visual similarity. By sharing our approach, we expect active discussion on that how to apply current computer vision research into the e-commerce industry.