 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWaTeRFlow: Watermark Temporal Robustness via Flow Consistency
Dec 22, 2025Image watermarking supports authenticity and provenance, yet many schemes are still easy to bypass with various distortions and powerful generative edits. Deep learning-based watermarking has improved robustness to diffusion-based image editing, but a gap remains when a watermarked image is converted to video by image-to-video (I2V), in which per-frame watermark detection weakens. I2V has quickly advanced from short, jittery clips to multi-second, temporally coherent scenes, and it now serves not only content creation but also world-modeling and simulation workflows, making cross-modal watermark recovery crucial. We present WaTeRFlow, a framework tailored for robustness under I2V. It consists of (i) FUSE (Flow-guided Unified Synthesis Engine), which exposes the encoder-decoder to realistic distortions via instruction-driven edits and a fast video diffusion proxy during training, (ii) optical-flow warping with a Temporal Consistency Loss (TCL) that stabilizes per-frame predictions, and (iii) a semantic preservation loss that maintains the conditioning signal. Experiments across representative I2V models show accurate watermark recovery from frames, with higher first-frame and per-frame bit accuracy and resilience when various distortions are applied before or after video generation.
Learning from the Undesirable: Robust Adaptation of Language Models without Forgetting
Nov 17, 2025
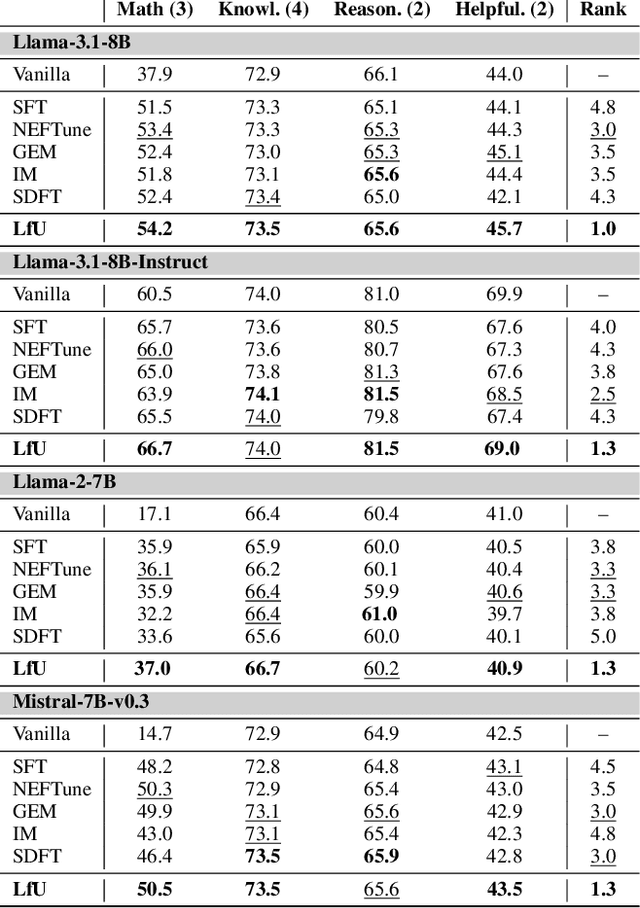

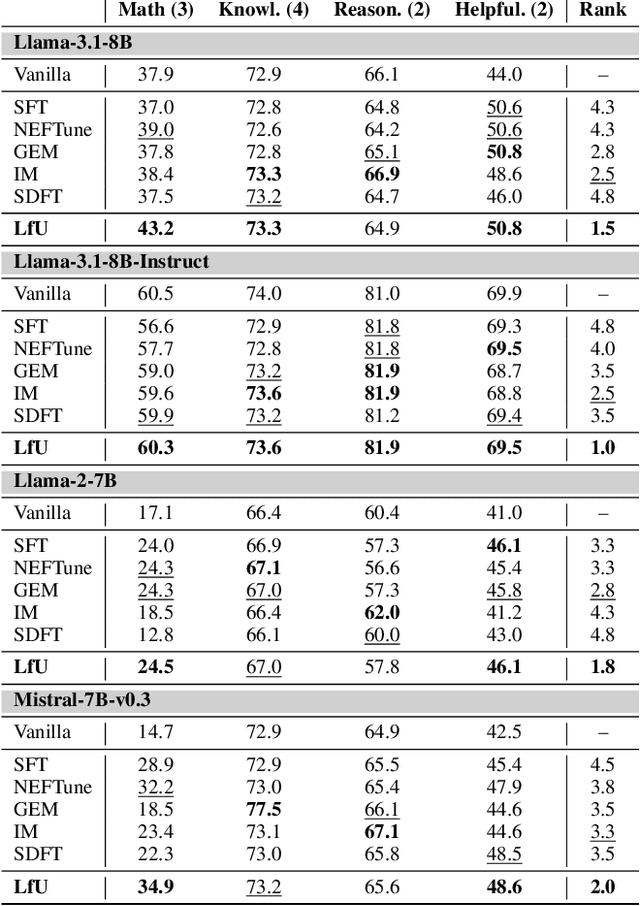
Language models (LMs) are often adapted through supervised fine-tuning (SFT) to specialize their capabilities for downstream tasks. However, in typical scenarios where the fine-tuning data is limited, e.g., compared to pre-training, SFT can lead LMs to overfit, causing them to rely on spurious patterns within the target task or to compromise other broadly useful capabilities as a side effect of narrow specialization. In this paper, we propose Learning-from-the-Undesirable (LfU), a simple yet effective regularization scheme for SFT to mitigate overfitting issues when fine-tuning LMs with limited data. Specifically, we aim to regularize the fine-tuning process to favor solutions that are resilient to "undesirable" model updates, e.g., gradient ascent steps that steer the model toward undesirable behaviors. To this end, we propose a novel form of consistency regularization that directly aligns internal representations of the model with those after an undesirable update. By leveraging representation-level data augmentation through undesirable updates, LfU effectively promotes generalization under limited data. Our experiments on diverse LM downstream tasks show that LfU serves as an effective prior that enhances adaptability while preserving pretrained knowledge. For example, our LM from LfU achieves a 16.8% average improvement on math tasks compared to vanilla SFT on the same dataset, where the latter even leads to degraded performance on those tasks. Furthermore, LfU exhibits improved robustness to prompt variations, e.g., yielding a 92.1% lower standard deviation in output performances compared to SFT, highlighting its versatile effects.
StarFT: Robust Fine-tuning of Zero-shot Models via Spuriosity Alignment
May 19, 2025Learning robust representations from data often requires scale, which has led to the success of recent zero-shot models such as CLIP. However, the obtained robustness can easily be deteriorated when these models are fine-tuned on other downstream tasks (e.g., of smaller scales). Previous works often interpret this phenomenon in the context of domain shift, developing fine-tuning methods that aim to preserve the original domain as much as possible. However, in a different context, fine-tuned models with limited data are also prone to learning features that are spurious to humans, such as background or texture. In this paper, we propose StarFT (Spurious Textual Alignment Regularization), a novel framework for fine-tuning zero-shot models to enhance robustness by preventing them from learning spuriosity. We introduce a regularization that aligns the output distribution for spuriosity-injected labels with the original zero-shot model, ensuring that the model is not induced to extract irrelevant features further from these descriptions.We leverage recent language models to get such spuriosity-injected labels by generating alternative textual descriptions that highlight potentially confounding features.Extensive experiments validate the robust generalization of StarFT and its emerging properties: zero-shot group robustness and improved zero-shot classification. Notably, StarFT boosts both worst-group and average accuracy by 14.30% and 3.02%, respectively, in the Waterbirds group shift scenario, where other robust fine-tuning baselines show even degraded performance.
Enhancing Variational Autoencoders with Smooth Robust Latent Encoding
Apr 24, 2025
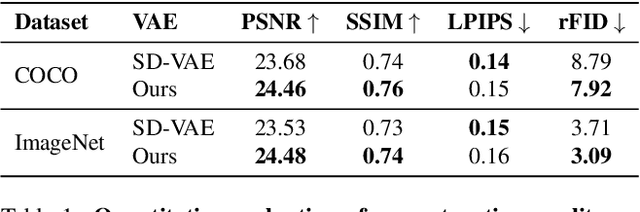
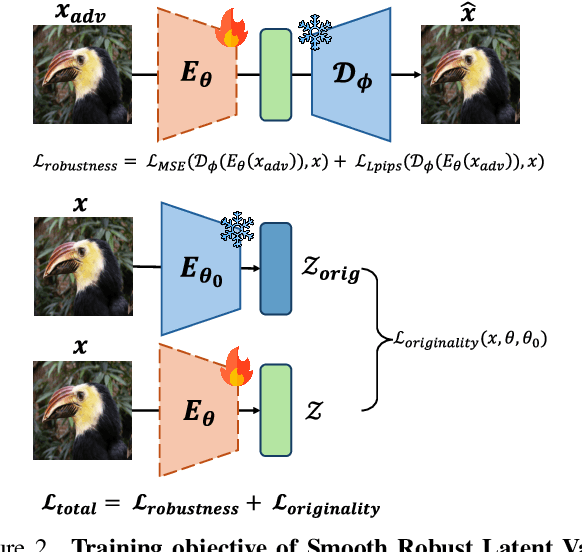
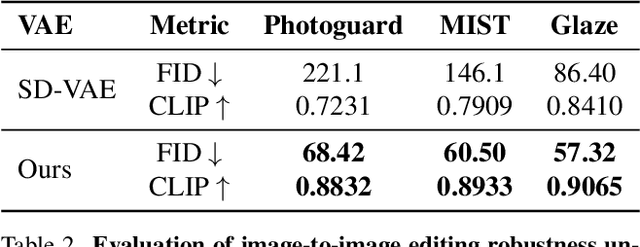
Variational Autoencoders (VAEs) have played a key role in scaling up diffusion-based generative models, as in Stable Diffusion, yet questions regarding their robustness remain largely underexplored. Although adversarial training has been an established technique for enhancing robustness in predictive models, it has been overlooked for generative models due to concerns about potential fidelity degradation by the nature of trade-offs between performance and robustness. In this work, we challenge this presumption, introducing Smooth Robust Latent VAE (SRL-VAE), a novel adversarial training framework that boosts both generation quality and robustness. In contrast to conventional adversarial training, which focuses on robustness only, our approach smooths the latent space via adversarial perturbations, promoting more generalizable representations while regularizing with originality representation to sustain original fidelity. Applied as a post-training step on pre-trained VAEs, SRL-VAE improves image robustness and fidelity with minimal computational overhead. Experiments show that SRL-VAE improves both generation quality, in image reconstruction and text-guided image editing, and robustness, against Nightshade attacks and image editing attacks. These results establish a new paradigm, showing that adversarial training, once thought to be detrimental to generative models, can instead enhance both fidelity and robustness.
FaceShield: Defending Facial Image against Deepfake Threats
Dec 13, 2024The rising use of deepfakes in criminal activities presents a significant issue, inciting widespread controversy. While numerous studies have tackled this problem, most primarily focus on deepfake detection. These reactive solutions are insufficient as a fundamental approach for crimes where authenticity verification is not critical. Existing proactive defenses also have limitations, as they are effective only for deepfake models based on specific Generative Adversarial Networks (GANs), making them less applicable in light of recent advancements in diffusion-based models. In this paper, we propose a proactive defense method named FaceShield, which introduces novel attack strategies targeting deepfakes generated by Diffusion Models (DMs) and facilitates attacks on various existing GAN-based deepfake models through facial feature extractor manipulations. Our approach consists of three main components: (i) manipulating the attention mechanism of DMs to exclude protected facial features during the denoising process, (ii) targeting prominent facial feature extraction models to enhance the robustness of our adversarial perturbation, and (iii) employing Gaussian blur and low-pass filtering techniques to improve imperceptibility while enhancing robustness against JPEG distortion. Experimental results on the CelebA-HQ and VGGFace2-HQ datasets demonstrate that our method achieves state-of-the-art performance against the latest deepfake models based on DMs, while also exhibiting applicability to GANs and showcasing greater imperceptibility of noise along with enhanced robustness.
Confidence-aware Denoised Fine-tuning of Off-the-shelf Models for Certified Robustness
Nov 13, 2024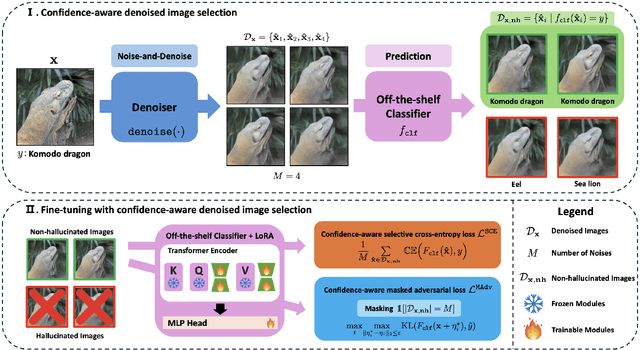
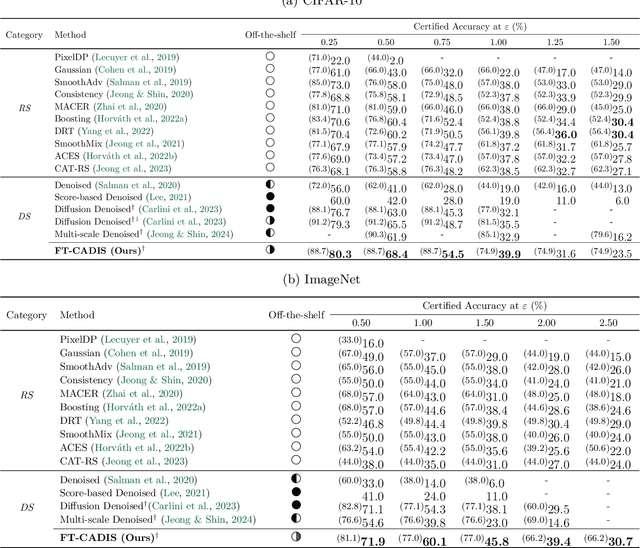
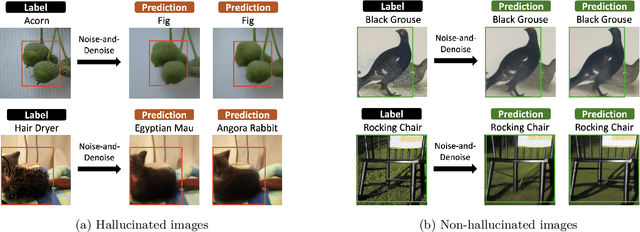

The remarkable advances in deep learning have led to the emergence of many off-the-shelf classifiers, e.g., large pre-trained models. However, since they are typically trained on clean data, they remain vulnerable to adversarial attacks. Despite this vulnerability, their superior performance and transferability make off-the-shelf classifiers still valuable in practice, demanding further work to provide adversarial robustness for them in a post-hoc manner. A recently proposed method, denoised smoothing, leverages a denoiser model in front of the classifier to obtain provable robustness without additional training. However, the denoiser often creates hallucination, i.e., images that have lost the semantics of their originally assigned class, leading to a drop in robustness. Furthermore, its noise-and-denoise procedure introduces a significant distribution shift from the original distribution, causing the denoised smoothing framework to achieve sub-optimal robustness. In this paper, we introduce Fine-Tuning with Confidence-Aware Denoised Image Selection (FT-CADIS), a novel fine-tuning scheme to enhance the certified robustness of off-the-shelf classifiers. FT-CADIS is inspired by the observation that the confidence of off-the-shelf classifiers can effectively identify hallucinated images during denoised smoothing. Based on this, we develop a confidence-aware training objective to handle such hallucinated images and improve the stability of fine-tuning from denoised images. In this way, the classifier can be fine-tuned using only images that are beneficial for adversarial robustness. We also find that such a fine-tuning can be done by updating a small fraction of parameters of the classifier. Extensive experiments demonstrate that FT-CADIS has established the state-of-the-art certified robustness among denoised smoothing methods across all $\ell_2$-adversary radius in various benchmarks.
Representation Alignment for Generation: Training Diffusion Transformers Is Easier Than You Think
Oct 09, 2024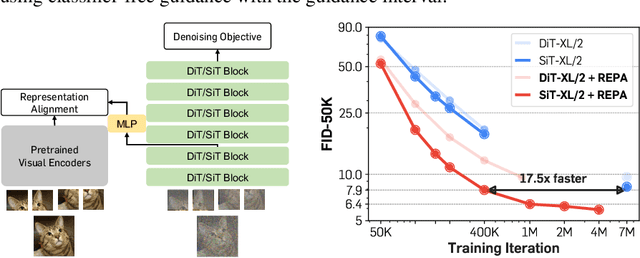

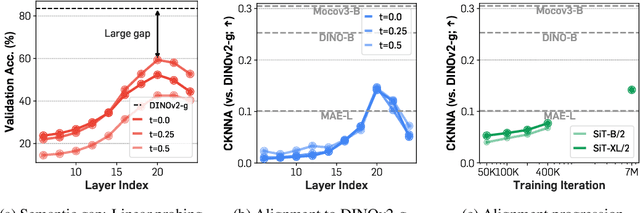
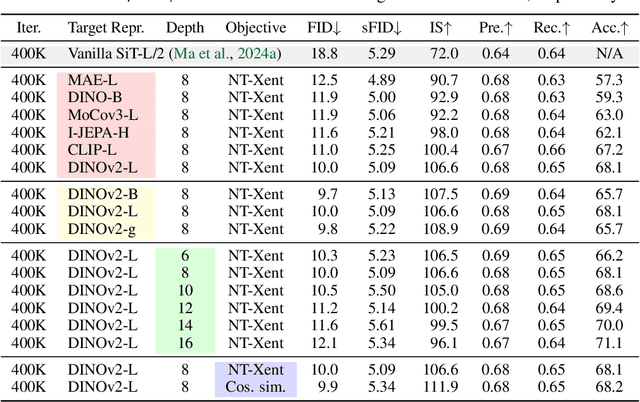
Recent studies have shown that the denoising process in (generative) diffusion models can induce meaningful (discriminative) representations inside the model, though the quality of these representations still lags behind those learned through recent self-supervised learning methods. We argue that one main bottleneck in training large-scale diffusion models for generation lies in effectively learning these representations. Moreover, training can be made easier by incorporating high-quality external visual representations, rather than relying solely on the diffusion models to learn them independently. We study this by introducing a straightforward regularization called REPresentation Alignment (REPA), which aligns the projections of noisy input hidden states in denoising networks with clean image representations obtained from external, pretrained visual encoders. The results are striking: our simple strategy yields significant improvements in both training efficiency and generation quality when applied to popular diffusion and flow-based transformers, such as DiTs and SiTs. For instance, our method can speed up SiT training by over 17.5$\times$, matching the performance (without classifier-free guidance) of a SiT-XL model trained for 7M steps in less than 400K steps. In terms of final generation quality, our approach achieves state-of-the-art results of FID=1.42 using classifier-free guidance with the guidance interval.
DiffusionGuard: A Robust Defense Against Malicious Diffusion-based Image Editing
Oct 08, 2024Recent advances in diffusion models have introduced a new era of text-guided image manipulation, enabling users to create realistic edited images with simple textual prompts. However, there is significant concern about the potential misuse of these methods, especially in creating misleading or harmful content. Although recent defense strategies, which introduce imperceptible adversarial noise to induce model failure, have shown promise, they remain ineffective against more sophisticated manipulations, such as editing with a mask. In this work, we propose DiffusionGuard, a robust and effective defense method against unauthorized edits by diffusion-based image editing models, even in challenging setups. Through a detailed analysis of these models, we introduce a novel objective that generates adversarial noise targeting the early stage of the diffusion process. This approach significantly improves the efficiency and effectiveness of adversarial noises. We also introduce a mask-augmentation technique to enhance robustness against various masks during test time. Finally, we introduce a comprehensive benchmark designed to evaluate the effectiveness and robustness of methods in protecting against privacy threats in realistic scenarios. Through extensive experiments, we show that our method achieves stronger protection and improved mask robustness with lower computational costs compared to the strongest baseline. Additionally, our method exhibits superior transferability and better resilience to noise removal techniques compared to all baseline methods. Our source code is publicly available at https://github.com/choi403/DiffusionGuard.
Adversarial Robustification via Text-to-Image Diffusion Models
Jul 26, 2024



Adversarial robustness has been conventionally believed as a challenging property to encode for neural networks, requiring plenty of training data. In the recent paradigm of adopting off-the-shelf models, however, access to their training data is often infeasible or not practical, while most of such models are not originally trained concerning adversarial robustness. In this paper, we develop a scalable and model-agnostic solution to achieve adversarial robustness without using any data. Our intuition is to view recent text-to-image diffusion models as "adaptable" denoisers that can be optimized to specify target tasks. Based on this, we propose: (a) to initiate a denoise-and-classify pipeline that offers provable guarantees against adversarial attacks, and (b) to leverage a few synthetic reference images generated from the text-to-image model that enables novel adaptation schemes. Our experiments show that our data-free scheme applied to the pre-trained CLIP could improve the (provable) adversarial robustness of its diverse zero-shot classification derivatives (while maintaining their accuracy), significantly surpassing prior approaches that utilize the full training data. Not only for CLIP, we also demonstrate that our framework is easily applicable for robustifying other visual classifiers efficiently.
Margin-aware Preference Optimization for Aligning Diffusion Models without Reference
Jun 10, 2024Modern alignment techniques based on human preferences, such as RLHF and DPO, typically employ divergence regularization relative to the reference model to ensure training stability. However, this often limits the flexibility of models during alignment, especially when there is a clear distributional discrepancy between the preference data and the reference model. In this paper, we focus on the alignment of recent text-to-image diffusion models, such as Stable Diffusion XL (SDXL), and find that this "reference mismatch" is indeed a significant problem in aligning these models due to the unstructured nature of visual modalities: e.g., a preference for a particular stylistic aspect can easily induce such a discrepancy. Motivated by this observation, we propose a novel and memory-friendly preference alignment method for diffusion models that does not depend on any reference model, coined margin-aware preference optimization (MaPO). MaPO jointly maximizes the likelihood margin between the preferred and dispreferred image sets and the likelihood of the preferred sets, simultaneously learning general stylistic features and preferences. For evaluation, we introduce two new pairwise preference datasets, which comprise self-generated image pairs from SDXL, Pick-Style and Pick-Safety, simulating diverse scenarios of reference mismatch. Our experiments validate that MaPO can significantly improve alignment on Pick-Style and Pick-Safety and general preference alignment when used with Pick-a-Pic v2, surpassing the base SDXL and other existing methods. Our code, models, and datasets are publicly available via https://mapo-t2i.github.io