 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRBench: Large-Scale Expert Rubrics for Evaluating High-Stakes Professional Reasoning
Nov 14, 2025Frontier model progress is often measured by academic benchmarks, which offer a limited view of performance in real-world professional contexts. Existing evaluations often fail to assess open-ended, economically consequential tasks in high-stakes domains like Legal and Finance, where practical returns are paramount. To address this, we introduce Professional Reasoning Bench (PRBench), a realistic, open-ended, and difficult benchmark of real-world problems in Finance and Law. We open-source its 1,100 expert-authored tasks and 19,356 expert-curated criteria, making it, to our knowledge, the largest public, rubric-based benchmark for both legal and finance domains. We recruit 182 qualified professionals, holding JDs, CFAs, or 6+ years of experience, who contributed tasks inspired by their actual workflows. This process yields significant diversity, with tasks spanning 114 countries and 47 US jurisdictions. Our expert-curated rubrics are validated through a rigorous quality pipeline, including independent expert validation. Subsequent evaluation of 20 leading models reveals substantial room for improvement, with top scores of only 0.39 (Finance) and 0.37 (Legal) on our Hard subsets. We further catalog associated economic impacts of the prompts and analyze performance using human-annotated rubric categories. Our analysis shows that models with similar overall scores can diverge significantly on specific capabilities. Common failure modes include inaccurate judgments, a lack of process transparency and incomplete reasoning, highlighting critical gaps in their reliability for professional adoption.
AgriChrono: A Multi-modal Dataset Capturing Crop Growth and Lighting Variability with a Field Robot
Aug 26, 2025Existing datasets for precision agriculture have primarily been collected in static or controlled environments such as indoor labs or greenhouses, often with limited sensor diversity and restricted temporal span. These conditions fail to reflect the dynamic nature of real farmland, including illumination changes, crop growth variation, and natural disturbances. As a result, models trained on such data often lack robustness and generalization when applied to real-world field scenarios. In this paper, we present AgriChrono, a novel robotic data collection platform and multi-modal dataset designed to capture the dynamic conditions of real-world agricultural environments. Our platform integrates multiple sensors and enables remote, time-synchronized acquisition of RGB, Depth, LiDAR, and IMU data, supporting efficient and repeatable long-term data collection across varying illumination and crop growth stages. We benchmark a range of state-of-the-art 3D reconstruction models on the AgriChrono dataset, highlighting the difficulty of reconstruction in real-world field environments and demonstrating its value as a research asset for advancing model generalization under dynamic conditions. The code and dataset are publicly available at: https://github.com/StructuresComp/agri-chrono
a2z-1 for Multi-Disease Detection in Abdomen-Pelvis CT: External Validation and Performance Analysis Across 21 Conditions
Dec 17, 2024We present a comprehensive evaluation of a2z-1, an artificial intelligence (AI) model designed to analyze abdomen-pelvis CT scans for 21 time-sensitive and actionable findings. Our study focuses on rigorous assessment of the model's performance and generalizability. Large-scale retrospective analysis demonstrates an average AUC of 0.931 across 21 conditions. External validation across two distinct health systems confirms consistent performance (AUC 0.923), establishing generalizability to different evaluation scenarios, with notable performance in critical findings such as small bowel obstruction (AUC 0.958) and acute pancreatitis (AUC 0.961). Subgroup analysis shows consistent accuracy across patient sex, age groups, and varied imaging protocols, including different slice thicknesses and contrast administration types. Comparison of high-confidence model outputs to radiologist reports reveals instances where a2z-1 identified overlooked findings, suggesting potential for quality assurance applications.
FaceShield: Defending Facial Image against Deepfake Threats
Dec 13, 2024The rising use of deepfakes in criminal activities presents a significant issue, inciting widespread controversy. While numerous studies have tackled this problem, most primarily focus on deepfake detection. These reactive solutions are insufficient as a fundamental approach for crimes where authenticity verification is not critical. Existing proactive defenses also have limitations, as they are effective only for deepfake models based on specific Generative Adversarial Networks (GANs), making them less applicable in light of recent advancements in diffusion-based models. In this paper, we propose a proactive defense method named FaceShield, which introduces novel attack strategies targeting deepfakes generated by Diffusion Models (DMs) and facilitates attacks on various existing GAN-based deepfake models through facial feature extractor manipulations. Our approach consists of three main components: (i) manipulating the attention mechanism of DMs to exclude protected facial features during the denoising process, (ii) targeting prominent facial feature extraction models to enhance the robustness of our adversarial perturbation, and (iii) employing Gaussian blur and low-pass filtering techniques to improve imperceptibility while enhancing robustness against JPEG distortion. Experimental results on the CelebA-HQ and VGGFace2-HQ datasets demonstrate that our method achieves state-of-the-art performance against the latest deepfake models based on DMs, while also exhibiting applicability to GANs and showcasing greater imperceptibility of noise along with enhanced robustness.
Real-Time Human Action Recognition on Embedded Platforms
Sep 11, 2024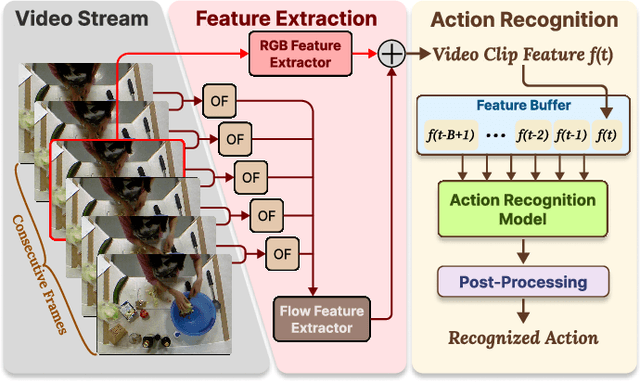
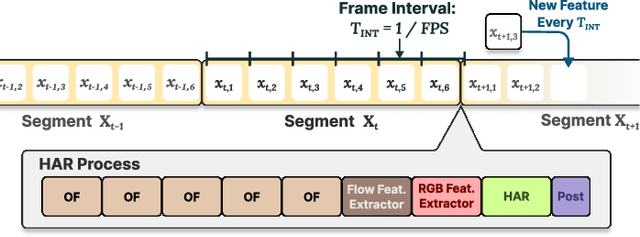
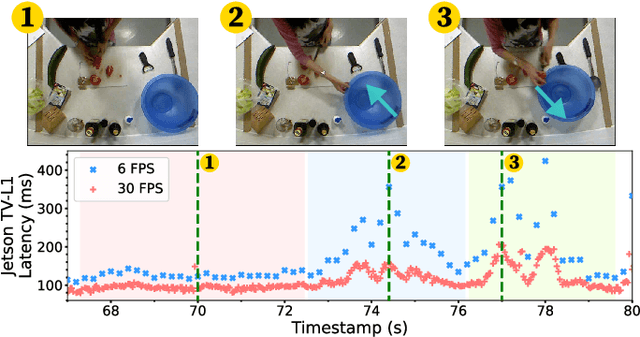
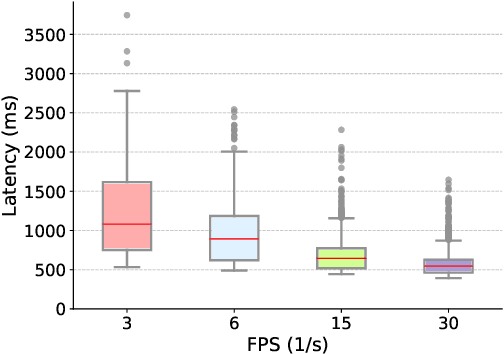
With advancements in computer vision and deep learning, video-based human action recognition (HAR) has become practical. However, due to the complexity of the computation pipeline, running HAR on live video streams incurs excessive delays on embedded platforms. This work tackles the real-time performance challenges of HAR with four contributions: 1) an experimental study identifying a standard Optical Flow (OF) extraction technique as the latency bottleneck in a state-of-the-art HAR pipeline, 2) an exploration of the latency-accuracy tradeoff between the standard and deep learning approaches to OF extraction, which highlights the need for a novel, efficient motion feature extractor, 3) the design of Integrated Motion Feature Extractor (IMFE), a novel single-shot neural network architecture for motion feature extraction with drastic improvement in latency, 4) the development of RT-HARE, a real-time HAR system tailored for embedded platforms. Experimental results on an Nvidia Jetson Xavier NX platform demonstrated that RT-HARE realizes real-time HAR at a video frame rate of 30 frames per second while delivering high levels of recognition accuracy.
MTVG : Multi-text Video Generation with Text-to-Video Models
Dec 07, 2023Recently, video generation has attracted massive attention and yielded noticeable outcomes. Concerning the characteristics of video, multi-text conditioning incorporating sequential events is necessary for next-step video generation. In this work, we propose a novel multi-text video generation~(MTVG) by directly utilizing a pre-trained diffusion-based text-to-video~(T2V) generation model without additional fine-tuning. To generate consecutive video segments, visual consistency generated by distinct prompts is necessary with diverse variations, such as motion and content-related transitions. Our proposed MTVG includes Dynamic Noise and Last Frame Aware Inversion which reinitialize the noise latent to preserve visual coherence between videos of different prompts and prevent repetitive motion or contents. Furthermore, we present Structure Guiding Sampling to maintain the global appearance across the frames in a single video clip, where we leverage iterative latent updates across the preceding frame. Additionally, our Prompt Generator allows for arbitrary format of text conditions consisting of diverse events. As a result, our extensive experiments, including diverse transitions of descriptions, demonstrate that our proposed methods show superior generated outputs in terms of semantically coherent and temporally seamless video.Video examples are available in our project page: https://kuai-lab.github.io/mtvg-page.
Multimodal Image-Text Matching Improves Retrieval-based Chest X-Ray Report Generation
Mar 29, 2023
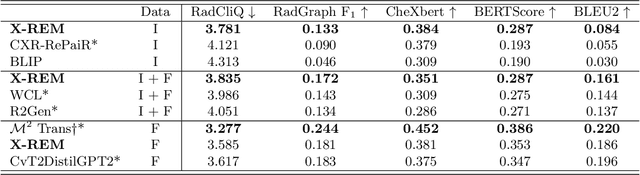
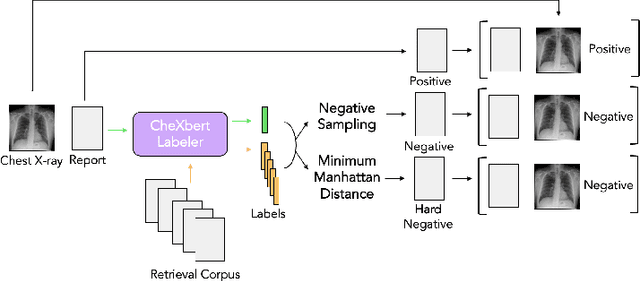

Automated generation of clinically accurate radiology reports can improve patient care. Previous report generation methods that rely on image captioning models often generate incoherent and incorrect text due to their lack of relevant domain knowledge, while retrieval-based attempts frequently retrieve reports that are irrelevant to the input image. In this work, we propose Contrastive X-Ray REport Match (X-REM), a novel retrieval-based radiology report generation module that uses an image-text matching score to measure the similarity of a chest X-ray image and radiology report for report retrieval. We observe that computing the image-text matching score with a language-image model can effectively capture the fine-grained interaction between image and text that is often lost when using cosine similarity. X-REM outperforms multiple prior radiology report generation modules in terms of both natural language and clinical metrics. Human evaluation of the generated reports suggests that X-REM increased the number of zero-error reports and decreased the average error severity compared to the baseline retrieval approach. Our code is available at: https://github.com/rajpurkarlab/X-REM