 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMMILE: An Expert-Driven Benchmark for Multimodal Medical In-Context Learning
Jun 26, 2025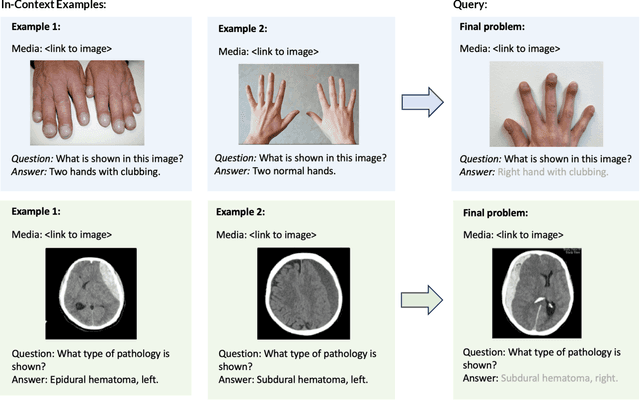



Multimodal in-context learning (ICL) remains underexplored despite significant potential for domains such as medicine. Clinicians routinely encounter diverse, specialized tasks requiring adaptation from limited examples, such as drawing insights from a few relevant prior cases or considering a constrained set of differential diagnoses. While multimodal large language models (MLLMs) have shown advances in medical visual question answering (VQA), their ability to learn multimodal tasks from context is largely unknown. We introduce SMMILE, the first expert-driven multimodal ICL benchmark for medical tasks. Eleven medical experts curated problems, each including a multimodal query and multimodal in-context examples as task demonstrations. SMMILE encompasses 111 problems (517 question-image-answer triplets) covering 6 medical specialties and 13 imaging modalities. We further introduce SMMILE++, an augmented variant with 1038 permuted problems. A comprehensive evaluation of 15 MLLMs demonstrates that most models exhibit moderate to poor multimodal ICL ability in medical tasks. In open-ended evaluations, ICL contributes only 8% average improvement over zero-shot on SMMILE and 9.4% on SMMILE++. We observe a susceptibility for irrelevant in-context examples: even a single noisy or irrelevant example can degrade performance by up to 9.5%. Moreover, example ordering exhibits a recency bias, i.e., placing the most relevant example last can lead to substantial performance improvements by up to 71%. Our findings highlight critical limitations and biases in current MLLMs when learning multimodal medical tasks from context.
The Impact of AI Assistance on Radiology Reporting: A Pilot Study Using Simulated AI Draft Reports
Dec 16, 2024



Radiologists face increasing workload pressures amid growing imaging volumes, creating risks of burnout and delayed reporting times. While artificial intelligence (AI) based automated radiology report generation shows promise for reporting workflow optimization, evidence of its real-world impact on clinical accuracy and efficiency remains limited. This study evaluated the effect of draft reports on radiology reporting workflows by conducting a three reader multi-case study comparing standard versus AI-assisted reporting workflows. In both workflows, radiologists reviewed the cases and modified either a standard template (standard workflow) or an AI-generated draft report (AI-assisted workflow) to create the final report. For controlled evaluation, we used GPT-4 to generate simulated AI drafts and deliberately introduced 1-3 errors in half the cases to mimic real AI system performance. The AI-assisted workflow significantly reduced average reporting time from 573 to 435 seconds (p=0.003), without a statistically significant difference in clinically significant errors between workflows. These findings suggest that AI-generated drafts can meaningfully accelerate radiology reporting while maintaining diagnostic accuracy, offering a practical solution to address mounting workload challenges in clinical practice.
ReXErr: Synthesizing Clinically Meaningful Errors in Diagnostic Radiology Reports
Sep 17, 2024Accurately interpreting medical images and writing radiology reports is a critical but challenging task in healthcare. Both human-written and AI-generated reports can contain errors, ranging from clinical inaccuracies to linguistic mistakes. To address this, we introduce ReXErr, a methodology that leverages Large Language Models to generate representative errors within chest X-ray reports. Working with board-certified radiologists, we developed error categories that capture common mistakes in both human and AI-generated reports. Our approach uses a novel sampling scheme to inject diverse errors while maintaining clinical plausibility. ReXErr demonstrates consistency across error categories and produces errors that closely mimic those found in real-world scenarios. This method has the potential to aid in the development and evaluation of report correction algorithms, potentially enhancing the quality and reliability of radiology reporting.
Direct Preference Optimization for Suppressing Hallucinated Prior Exams in Radiology Report Generation
Jun 10, 2024



Recent advances in generative vision-language models (VLMs) have exciting potential implications for AI in radiology, yet VLMs are also known to produce hallucinations, nonsensical text, and other unwanted behaviors that can waste clinicians' time and cause patient harm. Drawing on recent work on direct preference optimization (DPO), we propose a simple method for modifying the behavior of pretrained VLMs performing radiology report generation by suppressing unwanted types of generations. We apply our method to the prevention of hallucinations of prior exams, addressing a long-established problem behavior in models performing chest X-ray report generation. Across our experiments, we find that DPO fine-tuning achieves a 3.2-4.8x reduction in lines hallucinating prior exams while maintaining model performance on clinical accuracy metrics. Our work is, to the best of our knowledge, the first work to apply DPO to medical VLMs, providing a data- and compute- efficient way to suppress problem behaviors while maintaining overall clinical accuracy.
A Generalist Learner for Multifaceted Medical Image Interpretation
May 13, 2024Current medical artificial intelligence systems are often limited to narrow applications, hindering their widespread adoption in clinical practice. To address this limitation, we propose MedVersa, a generalist learner that enables flexible learning and tasking for medical image interpretation. By leveraging a large language model as a learnable orchestrator, MedVersa can learn from both visual and linguistic supervision, support multimodal inputs, and perform real-time task specification. This versatility allows MedVersa to adapt to various clinical scenarios and perform multifaceted medical image analysis. We introduce MedInterp, the largest multimodal dataset to date for medical image interpretation, consisting of over 13 million annotated instances spanning 11 tasks across 3 modalities, to support the development of MedVersa. Our experiments demonstrate that MedVersa achieves state-of-the-art performance in 9 tasks, sometimes outperforming specialist counterparts by over 10%. MedVersa is the first to showcase the viability of multimodal generative medical AI in implementing multimodal outputs, inputs, and dynamic task specification, highlighting its potential as a multifunctional system for comprehensive medical image analysis. This generalist approach to medical image interpretation paves the way for more adaptable and efficient AI-assisted clinical decision-making.
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 31, 2023



Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
Multimodal Image-Text Matching Improves Retrieval-based Chest X-Ray Report Generation
Mar 29, 2023
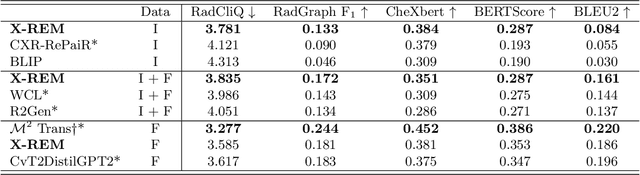
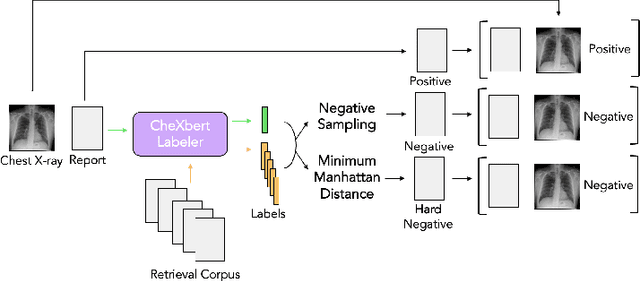

Automated generation of clinically accurate radiology reports can improve patient care. Previous report generation methods that rely on image captioning models often generate incoherent and incorrect text due to their lack of relevant domain knowledge, while retrieval-based attempts frequently retrieve reports that are irrelevant to the input image. In this work, we propose Contrastive X-Ray REport Match (X-REM), a novel retrieval-based radiology report generation module that uses an image-text matching score to measure the similarity of a chest X-ray image and radiology report for report retrieval. We observe that computing the image-text matching score with a language-image model can effectively capture the fine-grained interaction between image and text that is often lost when using cosine similarity. X-REM outperforms multiple prior radiology report generation modules in terms of both natural language and clinical metrics. Human evaluation of the generated reports suggests that X-REM increased the number of zero-error reports and decreased the average error severity compared to the baseline retrieval approach. Our code is available at: https://github.com/rajpurkarlab/X-REM