 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of AI Assistance on Radiology Reporting: A Pilot Study Using Simulated AI Draft Reports
Dec 16, 2024



Radiologists face increasing workload pressures amid growing imaging volumes, creating risks of burnout and delayed reporting times. While artificial intelligence (AI) based automated radiology report generation shows promise for reporting workflow optimization, evidence of its real-world impact on clinical accuracy and efficiency remains limited. This study evaluated the effect of draft reports on radiology reporting workflows by conducting a three reader multi-case study comparing standard versus AI-assisted reporting workflows. In both workflows, radiologists reviewed the cases and modified either a standard template (standard workflow) or an AI-generated draft report (AI-assisted workflow) to create the final report. For controlled evaluation, we used GPT-4 to generate simulated AI drafts and deliberately introduced 1-3 errors in half the cases to mimic real AI system performance. The AI-assisted workflow significantly reduced average reporting time from 573 to 435 seconds (p=0.003), without a statistically significant difference in clinically significant errors between workflows. These findings suggest that AI-generated drafts can meaningfully accelerate radiology reporting while maintaining diagnostic accuracy, offering a practical solution to address mounting workload challenges in clinical practice.
ReXamine-Global: A Framework for Uncovering Inconsistencies in Radiology Report Generation Metrics
Aug 29, 2024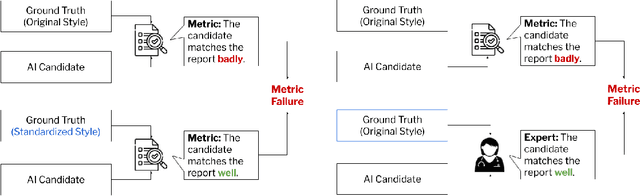


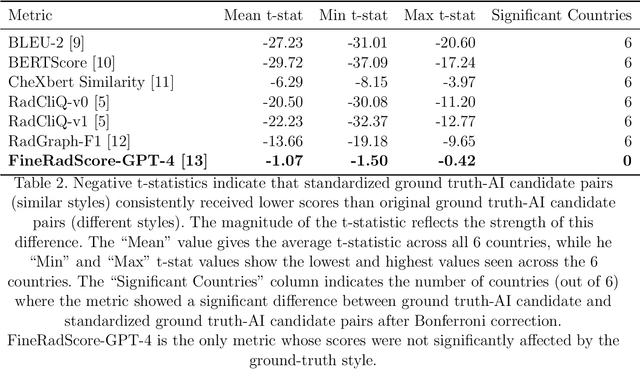
Given the rapidly expanding capabilities of generative AI models for radiology, there is a need for robust metrics that can accurately measure the quality of AI-generated radiology reports across diverse hospitals. We develop ReXamine-Global, a LLM-powered, multi-site framework that tests metrics across different writing styles and patient populations, exposing gaps in their generalization. First, our method tests whether a metric is undesirably sensitive to reporting style, providing different scores depending on whether AI-generated reports are stylistically similar to ground-truth reports or not. Second, our method measures whether a metric reliably agrees with experts, or whether metric and expert scores of AI-generated report quality diverge for some sites. Using 240 reports from 6 hospitals around the world, we apply ReXamine-Global to 7 established report evaluation metrics and uncover serious gaps in their generalizability. Developers can apply ReXamine-Global when designing new report evaluation metrics, ensuring their robustness across sites. Additionally, our analysis of existing metrics can guide users of those metrics towards evaluation procedures that work reliably at their sites of interest.
Direct Preference Optimization for Suppressing Hallucinated Prior Exams in Radiology Report Generation
Jun 10, 2024



Recent advances in generative vision-language models (VLMs) have exciting potential implications for AI in radiology, yet VLMs are also known to produce hallucinations, nonsensical text, and other unwanted behaviors that can waste clinicians' time and cause patient harm. Drawing on recent work on direct preference optimization (DPO), we propose a simple method for modifying the behavior of pretrained VLMs performing radiology report generation by suppressing unwanted types of generations. We apply our method to the prevention of hallucinations of prior exams, addressing a long-established problem behavior in models performing chest X-ray report generation. Across our experiments, we find that DPO fine-tuning achieves a 3.2-4.8x reduction in lines hallucinating prior exams while maintaining model performance on clinical accuracy metrics. Our work is, to the best of our knowledge, the first work to apply DPO to medical VLMs, providing a data- and compute- efficient way to suppress problem behaviors while maintaining overall clinical accuracy.
FineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores
May 31, 2024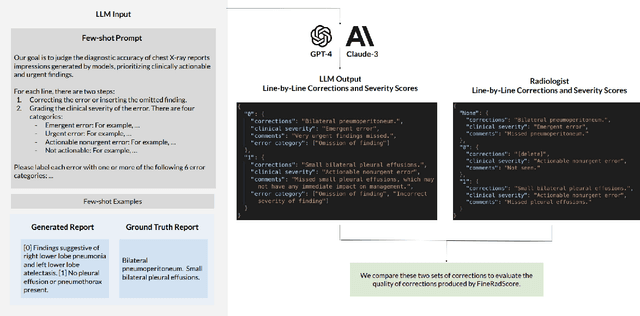
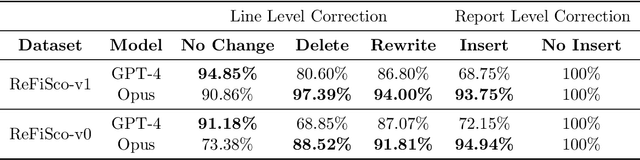
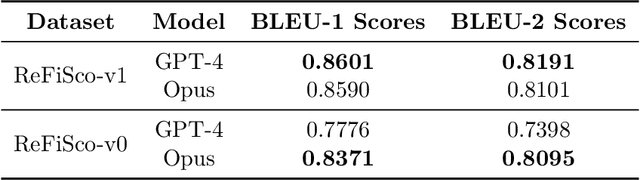
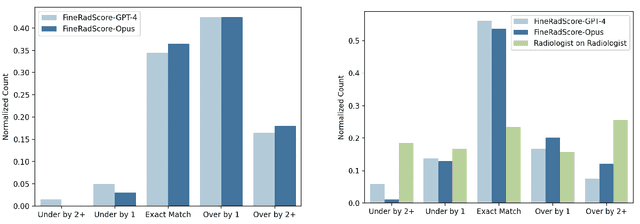
The current gold standard for evaluating generated chest x-ray (CXR) reports is through radiologist annotations. However, this process can be extremely time-consuming and costly, especially when evaluating large numbers of reports. In this work, we present FineRadScore, a Large Language Model (LLM)-based automated evaluation metric for generated CXR reports. Given a candidate report and a ground-truth report, FineRadScore gives the minimum number of line-by-line corrections required to go from the candidate to the ground-truth report. Additionally, FineRadScore provides an error severity rating with each correction and generates comments explaining why the correction was needed. We demonstrate that FineRadScore's corrections and error severity scores align with radiologist opinions. We also show that, when used to judge the quality of the report as a whole, FineRadScore aligns with radiologists as well as current state-of-the-art automated CXR evaluation metrics. Finally, we analyze FineRadScore's shortcomings to provide suggestions for future improvements.