 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores
Paper and Code
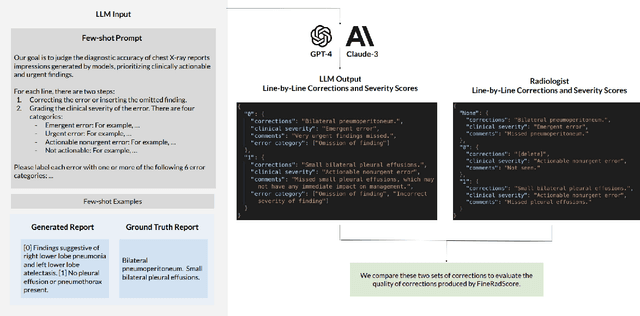
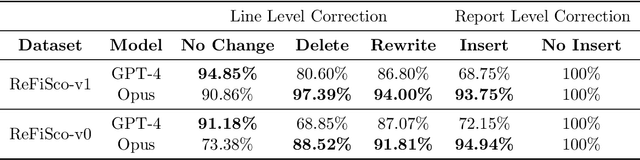
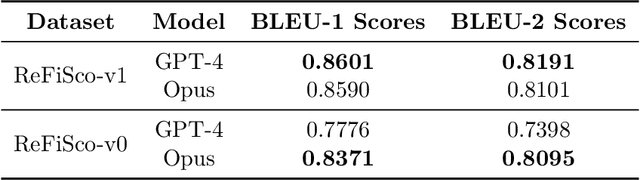
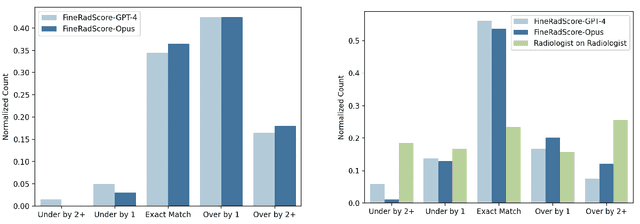
The current gold standard for evaluating generated chest x-ray (CXR) reports is through radiologist annotations. However, this process can be extremely time-consuming and costly, especially when evaluating large numbers of reports. In this work, we present FineRadScore, a Large Language Model (LLM)-based automated evaluation metric for generated CXR reports. Given a candidate report and a ground-truth report, FineRadScore gives the minimum number of line-by-line corrections required to go from the candidate to the ground-truth report. Additionally, FineRadScore provides an error severity rating with each correction and generates comments explaining why the correction was needed. We demonstrate that FineRadScore's corrections and error severity scores align with radiologist opinions. We also show that, when used to judge the quality of the report as a whole, FineRadScore aligns with radiologists as well as current state-of-the-art automated CXR evaluation metrics. Finally, we analyze FineRadScore's shortcomings to provide suggestions for future improvements.