 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
FineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores
May 31, 2024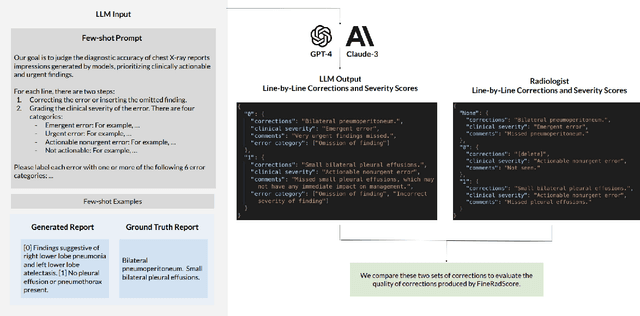
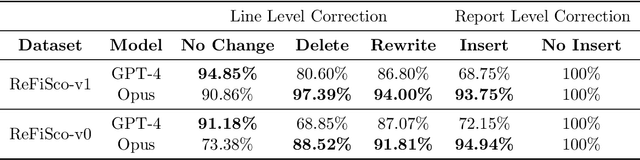
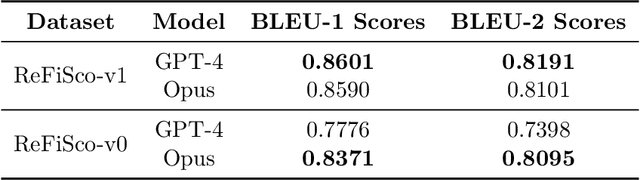
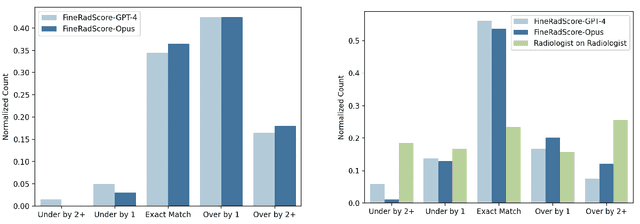
The current gold standard for evaluating generated chest x-ray (CXR) reports is through radiologist annotations. However, this process can be extremely time-consuming and costly, especially when evaluating large numbers of reports. In this work, we present FineRadScore, a Large Language Model (LLM)-based automated evaluation metric for generated CXR reports. Given a candidate report and a ground-truth report, FineRadScore gives the minimum number of line-by-line corrections required to go from the candidate to the ground-truth report. Additionally, FineRadScore provides an error severity rating with each correction and generates comments explaining why the correction was needed. We demonstrate that FineRadScore's corrections and error severity scores align with radiologist opinions. We also show that, when used to judge the quality of the report as a whole, FineRadScore aligns with radiologists as well as current state-of-the-art automated CXR evaluation metrics. Finally, we analyze FineRadScore's shortcomings to provide suggestions for future improvements.
Safeguarding Data in Multimodal AI: A Differentially Private Approach to CLIP Training
Jun 13, 2023



The surge in multimodal AI's success has sparked concerns over data privacy in vision-and-language tasks. While CLIP has revolutionized multimodal learning through joint training on images and text, its potential to unintentionally disclose sensitive information necessitates the integration of privacy-preserving mechanisms. We introduce a differentially private adaptation of the Contrastive Language-Image Pretraining (CLIP) model that effectively addresses privacy concerns while retaining accuracy. Our proposed method, Dp-CLIP, is rigorously evaluated on benchmark datasets encompassing diverse vision-and-language tasks such as image classification and visual question answering. We demonstrate that our approach retains performance on par with the standard non-private CLIP model. Furthermore, we analyze our proposed algorithm under linear representation settings. We derive the convergence rate of our algorithm and show a trade-off between utility and privacy when gradients are clipped per-batch and the loss function does not satisfy smoothness conditions assumed in the literature for the analysis of DP-SGD.