 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Improving the Effectiveness of Synthetic Chest X-Rays for Medical Image Analysis
Nov 27, 2024Purpose: To explore best-practice approaches for generating synthetic chest X-ray images and augmenting medical imaging datasets to optimize the performance of deep learning models in downstream tasks like classification and segmentation. Materials and Methods: We utilized a latent diffusion model to condition the generation of synthetic chest X-rays on text prompts and/or segmentation masks. We explored methods like using a proxy model and using radiologist feedback to improve the quality of synthetic data. These synthetic images were then generated from relevant disease information or geometrically transformed segmentation masks and added to ground truth training set images from the CheXpert, CANDID-PTX, SIIM, and RSNA Pneumonia datasets to measure improvements in classification and segmentation model performance on the test sets. F1 and Dice scores were used to evaluate classification and segmentation respectively. One-tailed t-tests with Bonferroni correction assessed the statistical significance of performance improvements with synthetic data. Results: Across all experiments, the synthetic data we generated resulted in a maximum mean classification F1 score improvement of 0.150453 (CI: 0.099108-0.201798; P=0.0031) compared to using only real data. For segmentation, the maximum Dice score improvement was 0.14575 (CI: 0.108267-0.183233; P=0.0064). Conclusion: Best practices for generating synthetic chest X-ray images for downstream tasks include conditioning on single-disease labels or geometrically transformed segmentation masks, as well as potentially using proxy modeling for fine-tuning such generations.
Preference Fine-Tuning for Factuality in Chest X-Ray Interpretation Models Without Human Feedback
Oct 09, 2024



Radiologists play a crucial role by translating medical images into medical reports. However, the field faces staffing shortages and increasing workloads. While automated approaches using vision-language models (VLMs) show promise as assistants, they require exceptionally high accuracy. Most current VLMs in radiology rely solely on supervised fine-tuning (SFT). Meanwhile, in the general domain, additional preference fine-tuning has become standard practice. The challenge in radiology lies in the prohibitive cost of obtaining radiologist feedback. We propose a scalable automated preference alignment technique for VLMs in radiology, focusing on chest X-ray (CXR) report generation. Our method leverages publicly available datasets with an LLM-as-a-Judge mechanism, eliminating the need for additional expert radiologist feedback. We evaluate and benchmark five direct alignment algorithms (DAAs). Our results show up to a 57.4% improvement in average GREEN scores, a LLM-based metric for evaluating CXR reports, and a 9.2% increase in an average across six metrics (domain specific and general), compared to the SFT baseline. We study reward overoptimization via length exploitation, with reports lengthening by up to 3.2x. To assess a potential alignment tax, we benchmark on six additional diverse tasks, finding no significant degradations. A reader study involving four board-certified radiologists indicates win rates of up to 0.62 over the SFT baseline, while significantly penalizing verbosity. Our analysis provides actionable insights for the development of VLMs in high-stakes fields like radiology.
FineRadScore: A Radiology Report Line-by-Line Evaluation Technique Generating Corrections with Severity Scores
May 31, 2024
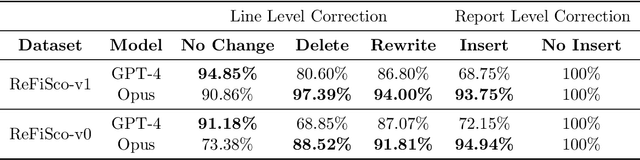
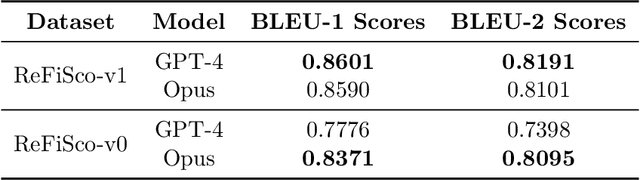
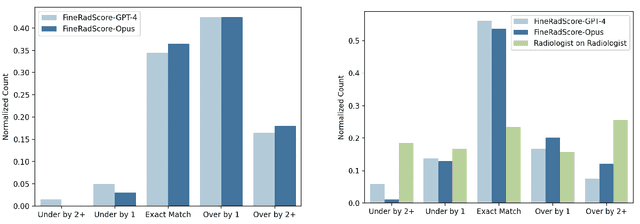
The current gold standard for evaluating generated chest x-ray (CXR) reports is through radiologist annotations. However, this process can be extremely time-consuming and costly, especially when evaluating large numbers of reports. In this work, we present FineRadScore, a Large Language Model (LLM)-based automated evaluation metric for generated CXR reports. Given a candidate report and a ground-truth report, FineRadScore gives the minimum number of line-by-line corrections required to go from the candidate to the ground-truth report. Additionally, FineRadScore provides an error severity rating with each correction and generates comments explaining why the correction was needed. We demonstrate that FineRadScore's corrections and error severity scores align with radiologist opinions. We also show that, when used to judge the quality of the report as a whole, FineRadScore aligns with radiologists as well as current state-of-the-art automated CXR evaluation metrics. Finally, we analyze FineRadScore's shortcomings to provide suggestions for future improvements.
A Benchmark of Domain-Adapted Large Language Models for Generating Brief Hospital Course Summaries
Mar 08, 2024



Brief hospital course (BHC) summaries are common clinical documents generated by summarizing clinical notes. While large language models (LLMs) depict remarkable capabilities in automating real-world tasks, their capabilities for healthcare applications such as BHC synthesis have not been shown. To enable the adaptation of LLMs for BHC synthesis, we introduce a novel benchmark consisting of a pre-processed dataset extracted from MIMIC-IV notes, encapsulating clinical note, and brief hospital course (BHC) pairs. We assess the performance of two general-purpose LLMs and three healthcare-adapted LLMs to improve BHC synthesis from clinical notes. Using clinical notes as input for generating BHCs, we apply prompting-based (using in-context learning) and fine-tuning-based adaptation strategies to three open-source LLMs (Clinical-T5-Large, Llama2-13B, FLAN-UL2) and two proprietary LLMs (GPT-3.5, GPT-4). We quantitatively evaluate the performance of these LLMs across varying context-length inputs using conventional natural language similarity metrics. We further perform a qualitative study where five diverse clinicians blindly compare clinician-written BHCs and two LLM-generated BHCs for 30 samples across metrics of comprehensiveness, conciseness, factual correctness, and fluency. Overall, we present a new benchmark and pre-processed dataset for using LLMs in BHC synthesis from clinical notes. We observe high-quality summarization performance for both in-context proprietary and fine-tuned open-source LLMs using both quantitative metrics and a qualitative clinical reader study. We propose our work as a benchmark to motivate future works to adapt and assess the performance of LLMs in BHC synthesis.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
Style-Aware Radiology Report Generation with RadGraph and Few-Shot Prompting
Oct 31, 2023



Automatically generated reports from medical images promise to improve the workflow of radiologists. Existing methods consider an image-to-report modeling task by directly generating a fully-fledged report from an image. However, this conflates the content of the report (e.g., findings and their attributes) with its style (e.g., format and choice of words), which can lead to clinically inaccurate reports. To address this, we propose a two-step approach for radiology report generation. First, we extract the content from an image; then, we verbalize the extracted content into a report that matches the style of a specific radiologist. For this, we leverage RadGraph -- a graph representation of reports -- together with large language models (LLMs). In our quantitative evaluations, we find that our approach leads to beneficial performance. Our human evaluation with clinical raters highlights that the AI-generated reports are indistinguishably tailored to the style of individual radiologist despite leveraging only a few examples as context.
Med-Flamingo: a Multimodal Medical Few-shot Learner
Jul 27, 2023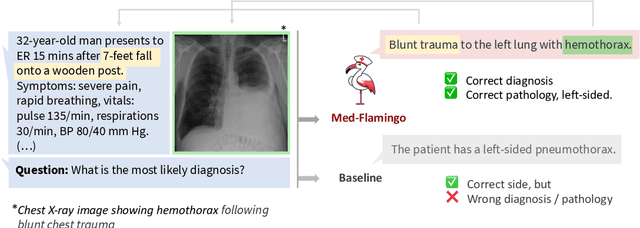

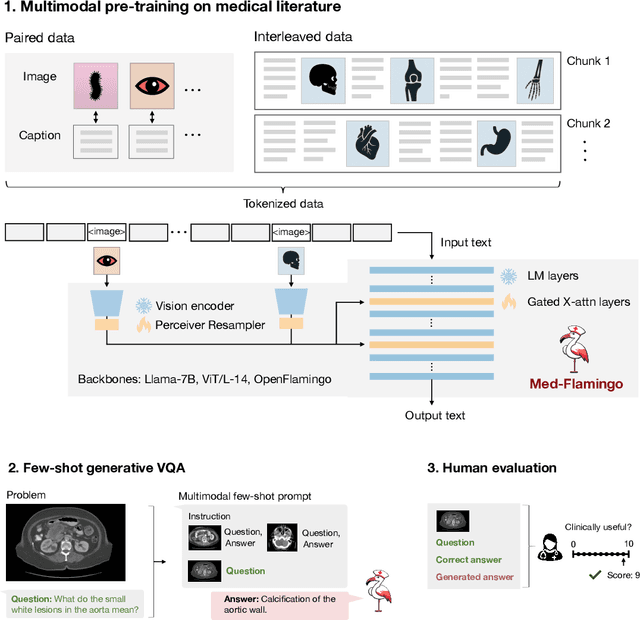
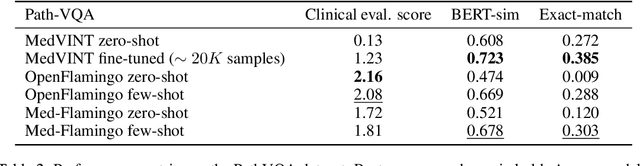
Medicine, by its nature, is a multifaceted domain that requires the synthesis of information across various modalities. Medical generative vision-language models (VLMs) make a first step in this direction and promise many exciting clinical applications. However, existing models typically have to be fine-tuned on sizeable down-stream datasets, which poses a significant limitation as in many medical applications data is scarce, necessitating models that are capable of learning from few examples in real-time. Here we propose Med-Flamingo, a multimodal few-shot learner adapted to the medical domain. Based on OpenFlamingo-9B, we continue pre-training on paired and interleaved medical image-text data from publications and textbooks. Med-Flamingo unlocks few-shot generative medical visual question answering (VQA) abilities, which we evaluate on several datasets including a novel challenging open-ended VQA dataset of visual USMLE-style problems. Furthermore, we conduct the first human evaluation for generative medical VQA where physicians review the problems and blinded generations in an interactive app. Med-Flamingo improves performance in generative medical VQA by up to 20\% in clinician's rating and firstly enables multimodal medical few-shot adaptations, such as rationale generation. We release our model, code, and evaluation app under https://github.com/snap-stanford/med-flamingo.