 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$S^3$: Stratified Scaling Search for Test-Time in Diffusion Language Models
Apr 07, 2026Test-time scaling investigates whether a fixed diffusion language model (DLM) can generate better outputs when given more inference compute, without additional training. However, naive best-of-$K$ sampling is fundamentally limited because it repeatedly draws from the same base diffusion distribution, whose high-probability regions are often misaligned with high-quality outputs. We propose $S^3$ (Stratified Scaling Search), a classical verifier-guided search method that improves generation by reallocating compute during the denoising process rather than only at the final output stage. At each denoising step, $S^3$ expands multiple candidate trajectories, evaluates them with a lightweight reference-free verifier, and selectively resamples promising candidates while preserving diversity within the search frontier. This procedure effectively approximates a reward-tilted sampling distribution that favors higher-quality outputs while remaining anchored to the model prior. Experiments with LLaDA-8B-Instruct on MATH-500, GSM8K, ARC-Challenge, and TruthfulQA demonstrate that $S^3$ consistently improves performance across benchmarks, achieving the largest gains on mathematical reasoning tasks while leaving the underlying model and decoding schedule unchanged. These results show that classical search over denoising trajectories provides a practical mechanism for test-time scaling in DLMs.
Compositional Neuro-Symbolic Reasoning
Apr 02, 2026We study structured abstraction-based reasoning for the Abstraction and Reasoning Corpus (ARC) and compare its generalization to test-time approaches. Purely neural architectures lack reliable combinatorial generalization, while strictly symbolic systems struggle with perceptual grounding. We therefore propose a neuro-symbolic architecture that extracts object-level structure from grids, uses neural priors to propose candidate transformations from a fixed domain-specific language (DSL) of atomic patterns, and filters hypotheses using cross-example consistency. Instantiated as a compositional reasoning framework based on unit patterns inspired by human visual abstraction, the system augments large language models (LLMs) with object representations and transformation proposals. On ARC-AGI-2, it improves base LLM performance from 16% to 24.4% on the public evaluation set, and to 30.8% when combined with ARC Lang Solver via a meta-classifier. These results demonstrate that separating perception, neural-guided transformation proposal, and symbolic consistency filtering improves generalization without task-specific finetuning or reinforcement learning, while reducing reliance on brute-force search and sampling-based test-time scaling. We open-source the ARC-AGI-2 Reasoner code (https://github.com/CoreThink-AI/arc-agi-2-reasoner).
Attention Head Entropy of LLMs Predicts Answer Correctness
Feb 14, 2026Large language models (LLMs) often generate plausible yet incorrect answers, posing risks in safety-critical settings such as medicine. Human evaluation is expensive, and LLM-as-judge approaches risk introducing hidden errors. Recent white-box methods detect contextual hallucinations using model internals, focusing on the localization of the attention mass, but two questions remain open: do these approaches extend to predicting answer correctness, and do they generalize out-of-domains? We introduce Head Entropy, a method that predicts answer correctness from attention entropy patterns, specifically measuring the spread of the attention mass. Using sparse logistic regression on per-head 2-Renyi entropies, Head Entropy matches or exceeds baselines in-distribution and generalizes substantially better on out-of-domains, it outperforms the closest baseline on average by +8.5% AUROC. We further show that attention patterns over the question/context alone, before answer generation, already carry predictive signal using Head Entropy with on average +17.7% AUROC over the closest baseline. We evaluate across 5 instruction-tuned LLMs and 3 QA datasets spanning general knowledge, multi-hop reasoning, and medicine.
Continuous-Utility Direct Preference Optimization
Jan 31, 2026Large language model reasoning is often treated as a monolithic capability, relying on binary preference supervision that fails to capture partial progress or fine-grained reasoning quality. We introduce Continuous Utility Direct Preference Optimization (CU-DPO), a framework that aligns models to a portfolio of prompt-based cognitive strategies by replacing binary labels with continuous scores that capture fine-grained reasoning quality. We prove that learning with K strategies yields a Theta(K log K) improvement in sample complexity over binary preferences, and that DPO converges to the entropy-regularized utility-maximizing policy. To exploit this signal, we propose a two-stage training pipeline: (i) strategy selection, which optimizes the model to choose the best strategy for a given problem via best-vs-all comparisons, and (ii) execution refinement, which trains the model to correctly execute the selected strategy using margin-stratified pairs. On mathematical reasoning benchmarks, CU-DPO improves strategy selection accuracy from 35-46 percent to 68-78 percent across seven base models, yielding consistent downstream reasoning gains of up to 6.6 points on in-distribution datasets with effective transfer to out-of-distribution tasks.
Training-Free Adaptation of New-Generation LLMs using Legacy Clinical Models
Jan 06, 2026Adapting language models to the clinical domain through continued pretraining and fine-tuning requires costly retraining for each new model generation. We propose Cross-Architecture Proxy Tuning (CAPT), a model-ensembling approach that enables training-free adaptation of state-of-the-art general-domain models using existing clinical models. CAPT supports models with disjoint vocabularies, leveraging contrastive decoding to selectively inject clinically relevant signals while preserving the general-domain model's reasoning and fluency. On six clinical classification and text-generation tasks, CAPT with a new-generation general-domain model and an older-generation clinical model consistently outperforms both models individually and state-of-the-art ensembling approaches (average +17.6% over UniTE, +41.4% over proxy tuning across tasks). Through token-level analysis and physician case studies, we demonstrate that CAPT amplifies clinically actionable language, reduces context errors, and increases clinical specificity.
Resolution-Independent Neural Operators for Multi-Rate Sparse-View CT
Dec 13, 2025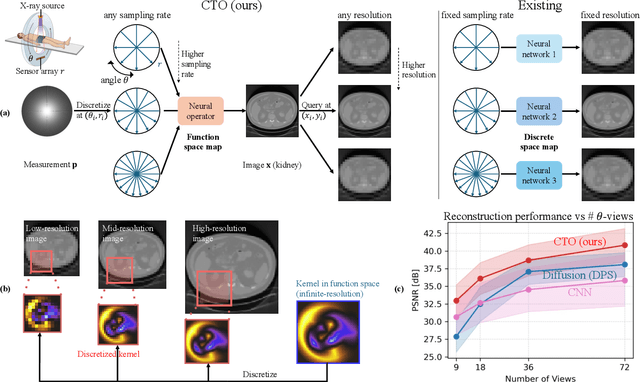
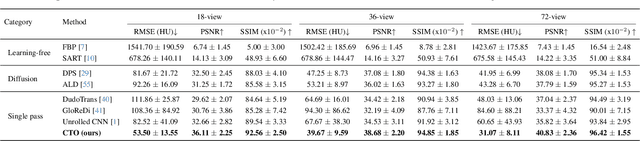
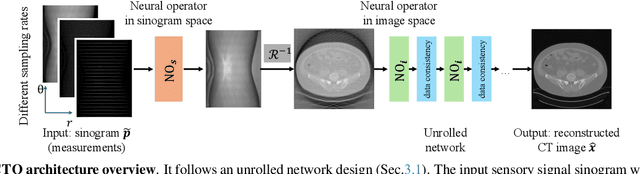
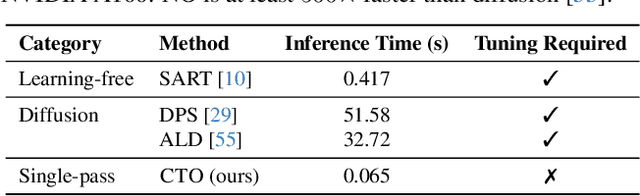
Sparse-view Computed Tomography (CT) reconstructs images from a limited number of X-ray projections to reduce radiation and scanning time, which makes reconstruction an ill-posed inverse problem. Deep learning methods achieve high-fidelity reconstructions but often overfit to a fixed acquisition setup, failing to generalize across sampling rates and image resolutions. For example, convolutional neural networks (CNNs) use the same learned kernels across resolutions, leading to artifacts when data resolution changes. We propose Computed Tomography neural Operator (CTO), a unified CT reconstruction framework that extends to continuous function space, enabling generalization (without retraining) across sampling rates and image resolutions. CTO operates jointly in the sinogram and image domains through rotation-equivariant Discrete-Continuous convolutions parametrized in the function space, making it inherently resolution- and sampling-agnostic. Empirically, CTO enables consistent multi-sampling-rate and cross-resolution performance, with on average >4dB PSNR gain over CNNs. Compared to state-of-the-art diffusion methods, CTO is 500$\times$ faster in inference time with on average 3dB gain. Empirical results also validate our design choices behind CTO's sinogram-space operator learning and rotation-equivariant convolution. Overall, CTO outperforms state-of-the-art baselines across sampling rates and resolutions, offering a scalable and generalizable solution that makes automated CT reconstruction more practical for deployment.
Prompt Triage: Structured Optimization Enhances Vision-Language Model Performance on Medical Imaging Benchmarks
Nov 14, 2025Vision-language foundation models (VLMs) show promise for diverse imaging tasks but often underperform on medical benchmarks. Prior efforts to improve performance include model finetuning, which requires large domain-specific datasets and significant compute, or manual prompt engineering, which is hard to generalize and often inaccessible to medical institutions seeking to deploy these tools. These challenges motivate interest in approaches that draw on a model's embedded knowledge while abstracting away dependence on human-designed prompts to enable scalable, weight-agnostic performance improvements. To explore this, we adapt the Declarative Self-improving Python (DSPy) framework for structured automated prompt optimization in medical vision-language systems through a comprehensive, formal evaluation. We implement prompting pipelines for five medical imaging tasks across radiology, gastroenterology, and dermatology, evaluating 10 open-source VLMs with four prompt optimization techniques. Optimized pipelines achieved a median relative improvement of 53% over zero-shot prompting baselines, with the largest gains ranging from 300% to 3,400% on tasks where zero-shot performance is low. These results highlight the substantial potential of applying automated prompt optimization to medical AI systems, demonstrating significant gains for vision-based applications requiring accurate clinical image interpretation. By reducing dependence on prompt design to elicit intended outputs, these techniques allow clinicians to focus on patient care and clinical decision-making. Furthermore, our experiments offer scalability and preserve data privacy, demonstrating performance improvement on open-source VLMs. We publicly release our evaluation pipelines to support reproducible research on specialized medical tasks, available at https://github.com/DaneshjouLab/prompt-triage-lab.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Enhancing Deep Learning-Driven Multi-Coil MRI Reconstruction via Self-Supervised Denoising
Nov 19, 2024We examine the effect of incorporating self-supervised denoising as a pre-processing step for training deep learning (DL) based reconstruction methods on data corrupted by Gaussian noise. K-space data employed for training are typically multi-coil and inherently noisy. Although DL-based reconstruction methods trained on fully sampled data can enable high reconstruction quality, obtaining large, noise-free datasets is impractical. We leverage Generalized Stein's Unbiased Risk Estimate (GSURE) for denoising. We evaluate two DL-based reconstruction methods: Diffusion Probabilistic Models (DPMs) and Model-Based Deep Learning (MoDL). We evaluate the impact of denoising on the performance of these DL-based methods in solving accelerated multi-coil magnetic resonance imaging (MRI) reconstruction. The experiments were carried out on T2-weighted brain and fat-suppressed proton-density knee scans. We observed that self-supervised denoising enhances the quality and efficiency of MRI reconstructions across various scenarios. Specifically, employing denoised images rather than noisy counterparts when training DL networks results in lower normalized root mean squared error (NRMSE), higher structural similarity index measure (SSIM) and peak signal-to-noise ratio (PSNR) across different SNR levels, including 32dB, 22dB, and 12dB for T2-weighted brain data, and 24dB, 14dB, and 4dB for fat-suppressed knee data. Overall, we showed that denoising is an essential pre-processing technique capable of improving the efficacy of DL-based MRI reconstruction methods under diverse conditions. By refining the quality of input data, denoising can enable the training of more effective DL networks, potentially bypassing the need for noise-free reference MRI scans.
Detecting Underdiagnosed Medical Conditions with Deep Learning-Based Opportunistic CT Imaging
Sep 18, 2024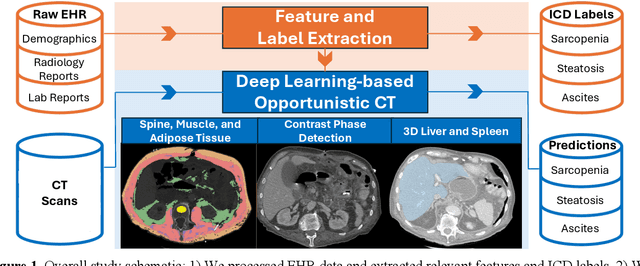
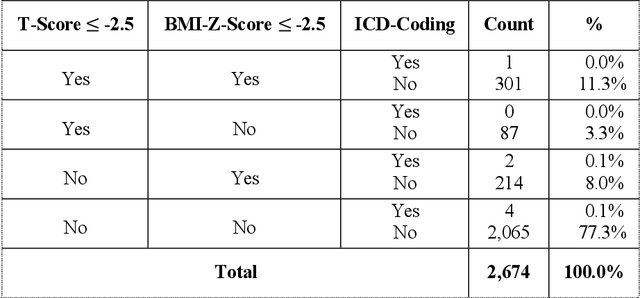
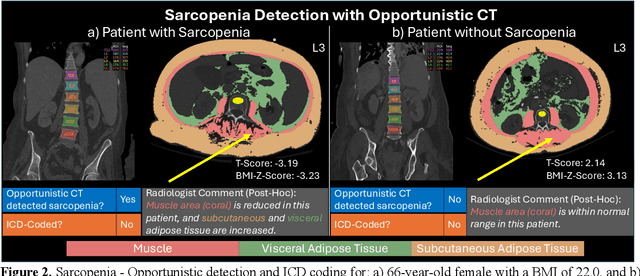
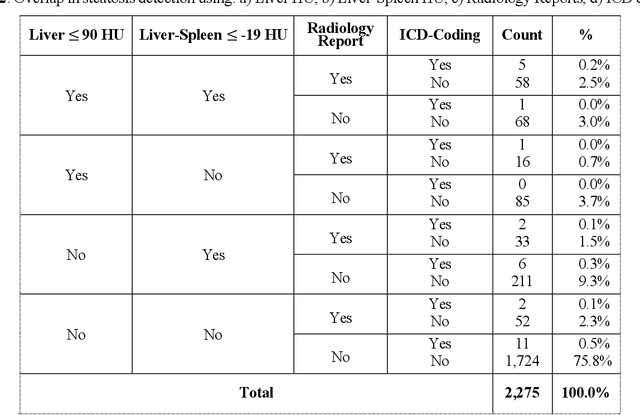
Abdominal computed tomography (CT) scans are frequently performed in clinical settings. Opportunistic CT involves repurposing routine CT images to extract diagnostic information and is an emerging tool for detecting underdiagnosed conditions such as sarcopenia, hepatic steatosis, and ascites. This study utilizes deep learning methods to promote accurate diagnosis and clinical documentation. We analyze 2,674 inpatient CT scans to identify discrepancies between imaging phenotypes (characteristics derived from opportunistic CT scans) and their corresponding documentation in radiology reports and ICD coding. Through our analysis, we find that only 0.5%, 3.2%, and 30.7% of scans diagnosed with sarcopenia, hepatic steatosis, and ascites (respectively) through either opportunistic imaging or radiology reports were ICD-coded. Our findings demonstrate opportunistic CT's potential to enhance diagnostic precision and accuracy of risk adjustment models, offering advancements in precision medicine.