 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHealthAdminBench: Evaluating Computer-Use Agents on Healthcare Administration Tasks
Apr 10, 2026Healthcare administration accounts for over $1 trillion in annual spending, making it a promising target for LLM-based computer-use agents (CUAs). While clinical applications of LLMs have received significant attention, no benchmark exists for evaluating CUAs on end-to-end administrative workflows. To address this gap, we introduce HealthAdminBench, a benchmark comprising four realistic GUI environments: an EHR, two payer portals, and a fax system, and 135 expert-defined tasks spanning three administrative task types: Prior Authorization, Appeals and Denials Management, and Durable Medical Equipment (DME) Order Processing. Each task is decomposed into fine-grained, verifiable subtasks, yielding 1,698 evaluation points. We evaluate seven agent configurations under multiple prompting and observation settings and find that, despite strong subtask performance, end-to-end reliability remains low: the best-performing agent (Claude Opus 4.6 CUA) achieves only 36.3 percent task success, while GPT-5.4 CUA attains the highest subtask success rate (82.8 percent). These results reveal a substantial gap between current agent capabilities and the demands of real-world administrative workflows. HealthAdminBench provides a rigorous foundation for evaluating progress toward safe and reliable automation of healthcare administrative workflows.
The Optimization Paradox in Clinical AI Multi-Agent Systems
Jun 06, 2025Multi-agent artificial intelligence systems are increasingly deployed in clinical settings, yet the relationship between component-level optimization and system-wide performance remains poorly understood. We evaluated this relationship using 2,400 real patient cases from the MIMIC-CDM dataset across four abdominal pathologies (appendicitis, pancreatitis, cholecystitis, diverticulitis), decomposing clinical diagnosis into information gathering, interpretation, and differential diagnosis. We evaluated single agent systems (one model performing all tasks) against multi-agent systems (specialized models for each task) using comprehensive metrics spanning diagnostic outcomes, process adherence, and cost efficiency. Our results reveal a paradox: while multi-agent systems generally outperformed single agents, the component-optimized or Best of Breed system with superior components and excellent process metrics (85.5% information accuracy) significantly underperformed in diagnostic accuracy (67.7% vs. 77.4% for a top multi-agent system). This finding underscores that successful integration of AI in healthcare requires not just component level optimization but also attention to information flow and compatibility between agents. Our findings highlight the need for end to end system validation rather than relying on component metrics alone.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Disentangling Reasoning and Knowledge in Medical Large Language Models
May 16, 2025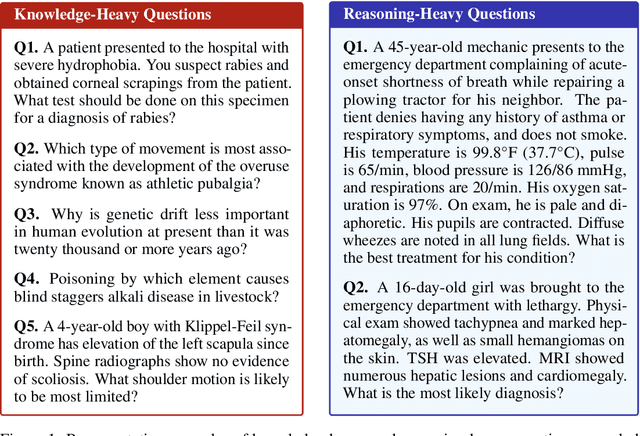
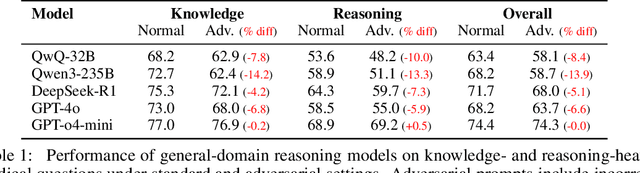
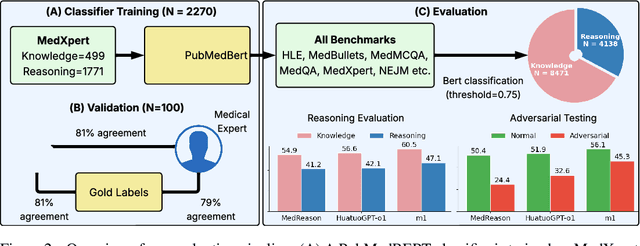
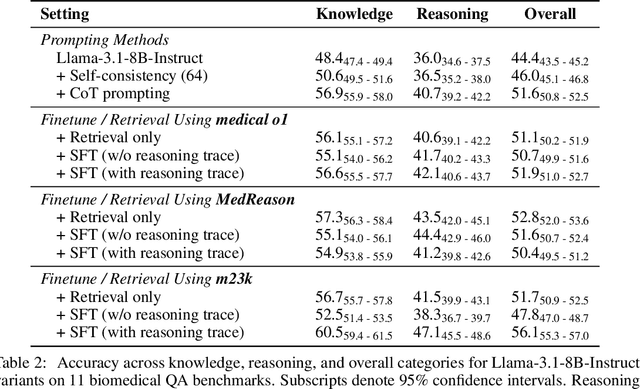
Medical reasoning in large language models (LLMs) aims to emulate clinicians' diagnostic thinking, but current benchmarks such as MedQA-USMLE, MedMCQA, and PubMedQA often mix reasoning with factual recall. We address this by separating 11 biomedical QA benchmarks into reasoning- and knowledge-focused subsets using a PubMedBERT classifier that reaches 81 percent accuracy, comparable to human performance. Our analysis shows that only 32.8 percent of questions require complex reasoning. We evaluate biomedical models (HuatuoGPT-o1, MedReason, m1) and general-domain models (DeepSeek-R1, o4-mini, Qwen3), finding consistent gaps between knowledge and reasoning performance. For example, m1 scores 60.5 on knowledge but only 47.1 on reasoning. In adversarial tests where models are misled with incorrect initial reasoning, biomedical models degrade sharply, while larger or RL-trained general models show more robustness. To address this, we train BioMed-R1 using fine-tuning and reinforcement learning on reasoning-heavy examples. It achieves the strongest performance among similarly sized models. Further gains may come from incorporating clinical case reports and training with adversarial and backtracking scenarios.
Measurement to Meaning: A Validity-Centered Framework for AI Evaluation
May 13, 2025While the capabilities and utility of AI systems have advanced, rigorous norms for evaluating these systems have lagged. Grand claims, such as models achieving general reasoning capabilities, are supported with model performance on narrow benchmarks, like performance on graduate-level exam questions, which provide a limited and potentially misleading assessment. We provide a structured approach for reasoning about the types of evaluative claims that can be made given the available evidence. For instance, our framework helps determine whether performance on a mathematical benchmark is an indication of the ability to solve problems on math tests or instead indicates a broader ability to reason. Our framework is well-suited for the contemporary paradigm in machine learning, where various stakeholders provide measurements and evaluations that downstream users use to validate their claims and decisions. At the same time, our framework also informs the construction of evaluations designed to speak to the validity of the relevant claims. By leveraging psychometrics' breakdown of validity, evaluations can prioritize the most critical facets for a given claim, improving empirical utility and decision-making efficacy. We illustrate our framework through detailed case studies of vision and language model evaluations, highlighting how explicitly considering validity strengthens the connection between evaluation evidence and the claims being made.
Context Clues: Evaluating Long Context Models for Clinical Prediction Tasks on EHRs
Dec 09, 2024



Foundation Models (FMs) trained on Electronic Health Records (EHRs) have achieved state-of-the-art results on numerous clinical prediction tasks. However, most existing EHR FMs have context windows of <1k tokens. This prevents them from modeling full patient EHRs which can exceed 10k's of events. Recent advancements in subquadratic long-context architectures (e.g., Mamba) offer a promising solution. However, their application to EHR data has not been well-studied. We address this gap by presenting the first systematic evaluation of the effect of context length on modeling EHR data. We find that longer context models improve predictive performance -- our Mamba-based model surpasses the prior state-of-the-art on 9/14 tasks on the EHRSHOT prediction benchmark. For clinical applications, however, model performance alone is insufficient -- robustness to the unique properties of EHR is crucial. Thus, we also evaluate models across three previously underexplored properties of EHR data: (1) the prevalence of "copy-forwarded" diagnoses which creates artificial repetition of tokens within EHR sequences; (2) the irregular time intervals between EHR events which can lead to a wide range of timespans within a context window; and (3) the natural increase in disease complexity over time which makes later tokens in the EHR harder to predict than earlier ones. Stratifying our EHRSHOT results, we find that higher levels of each property correlate negatively with model performance, but that longer context models are more robust to more extreme levels of these properties. Our work highlights the potential for using long-context architectures to model EHR data, and offers a case study for identifying new challenges in modeling sequential data motivated by domains outside of natural language. We release our models and code at: https://github.com/som-shahlab/long_context_clues
ZIP-FIT: Embedding-Free Data Selection via Compression-Based Alignment
Oct 23, 2024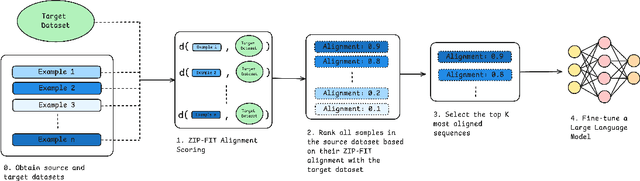

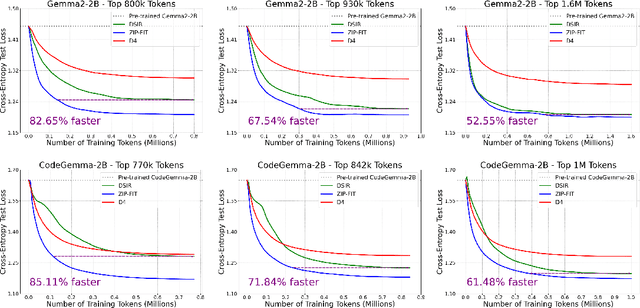
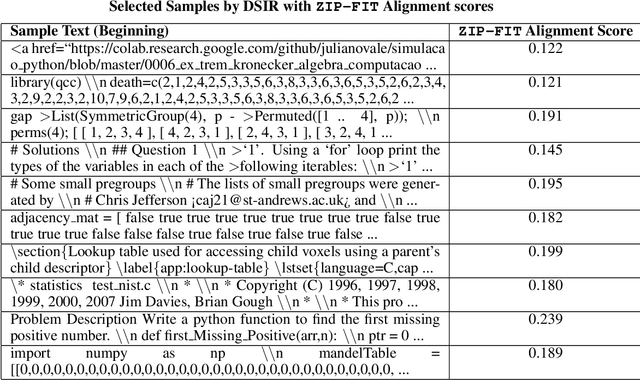
Data selection is crucial for optimizing language model (LM) performance on specific tasks, yet most existing methods fail to effectively consider the target task distribution. Current approaches either ignore task-specific requirements entirely or rely on approximations that fail to capture the nuanced patterns needed for tasks like Autoformalization or code generation. Methods that do consider the target distribution often rely on simplistic, sometimes noisy, representations, like hashed n-gram features, which can lead to collisions and introduce noise. We introduce ZIP-FIT, a data selection framework that uses gzip compression to directly measure alignment between potential training data and the target task distribution. In extensive evaluations on Autoformalization and Python code generation, ZIP-FIT significantly outperforms leading baselines like DSIR and D4. Models trained on ZIP-FIT-selected data achieve their lowest cross-entropy loss up to 85.1\% faster than baselines, demonstrating that better task alignment leads to more efficient learning. In addition, ZIP-FIT performs selection up to 65.8\% faster than DSIR and two orders of magnitude faster than D4. Notably, ZIP-FIT shows that smaller, well-aligned datasets often outperform larger but less targeted ones, demonstrating that a small amount of higher quality data is superior to a large amount of lower quality data. Our results imply that task-aware data selection is crucial for efficient domain adaptation, and that compression offers a principled way to measure task alignment. By showing that targeted data selection can dramatically improve task-specific performance, our work provides new insights into the relationship between data quality, task alignment, and model learning efficiency.
meds_reader: A fast and efficient EHR processing library
Sep 12, 2024



The growing demand for machine learning in healthcare requires processing increasingly large electronic health record (EHR) datasets, but existing pipelines are not computationally efficient or scalable. In this paper, we introduce meds_reader, an optimized Python package for efficient EHR data processing that is designed to take advantage of many intrinsic properties of EHR data for improved speed. We then demonstrate the benefits of meds_reader by reimplementing key components of two major EHR processing pipelines, achieving 10-100x improvements in memory, speed, and disk usage. The code for meds_reader can be found at https://github.com/som-shahlab/meds_reader.