 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARE: A Conformal Safety Layer for Medical Summarization
Jun 08, 2026Large language models (LLMs) are increasingly used for medical summarization, but their outputs can omit medically important information and introduce unsupported claims. Existing error-detection methods produce heuristic or uncalibrated scores, providing no formal control over missed errors and no principled way to trade off safety against clinician review burden. We introduce Conformal Assessment for Risk Evaluation (CARE), a post-hoc, model-agnostic safety layer that uses conformal risk control to overlay calibrated omission and hallucination flags onto summaries from any LLM without retraining. CARE provides finite-sample, distribution-free guarantees through two controllers: a hallucination controller that bounds the probability of a document containing any unflagged hallucinated sentence, and an omission controller that bounds the expected fraction of important omissions not surfaced for review. Unlike hallucination detection, omissions depend jointly on whether a source sentence is important and whether it is covered by the summary. We show that calibrating only one dimension can violate the target risk bound, while marginal decompositions remain valid but overly conservative. By jointly calibrating over the full $(τ,γ)$ threshold space, CARE preserves formal guarantees while surfacing up to 5$\times$ fewer sentences than alternative calibrated baselines. Across five medical summarization tasks, CARE satisfies the target risk bound at $α= 0.15$ with 95% confidence across 100 calibration/test resplits, using only ~100 labeled documents per domain. In a preliminary clinician study (75 document reviews), calibrated flags improved omission detection by 28.6 percentage points on average. These results show that sentence-level safety guarantees are feasible for LLM-assisted medical summarization and offer a tunable mechanism for balancing residual risk and review effort.
Development, Evaluation, and Deployment of a Multi-Agent System for Thoracic Tumor Board
Apr 14, 2026Tumor boards are multidisciplinary conferences dedicated to producing actionable patient care recommendations with live review of primary radiology and pathology data. Succinct patient case summaries are needed to drive efficient and accurate case discussions. We developed a manual AI-based workflow to generate patient summaries to display live at the Stanford Thoracic Tumor board. To improve on this manually intensive process, we developed several automated AI chart summarization methods and evaluated them against physician gold standard summaries and fact-based scoring rubrics. We report these comparative evaluations as well as our deployment of the final state automated AI chart summarization tool along with post-deployment monitoring. We also validate the use of an LLM as a judge evaluation strategy for fact-based scoring. This work is an example of integrating AI-based workflows into routine clinical practice.
HealthAdminBench: Evaluating Computer-Use Agents on Healthcare Administration Tasks
Apr 10, 2026Healthcare administration accounts for over $1 trillion in annual spending, making it a promising target for LLM-based computer-use agents (CUAs). While clinical applications of LLMs have received significant attention, no benchmark exists for evaluating CUAs on end-to-end administrative workflows. To address this gap, we introduce HealthAdminBench, a benchmark comprising four realistic GUI environments: an EHR, two payer portals, and a fax system, and 135 expert-defined tasks spanning three administrative task types: Prior Authorization, Appeals and Denials Management, and Durable Medical Equipment (DME) Order Processing. Each task is decomposed into fine-grained, verifiable subtasks, yielding 1,698 evaluation points. We evaluate seven agent configurations under multiple prompting and observation settings and find that, despite strong subtask performance, end-to-end reliability remains low: the best-performing agent (Claude Opus 4.6 CUA) achieves only 36.3 percent task success, while GPT-5.4 CUA attains the highest subtask success rate (82.8 percent). These results reveal a substantial gap between current agent capabilities and the demands of real-world administrative workflows. HealthAdminBench provides a rigorous foundation for evaluating progress toward safe and reliable automation of healthcare administrative workflows.
Monitoring Deployed AI Systems in Health Care
Dec 09, 2025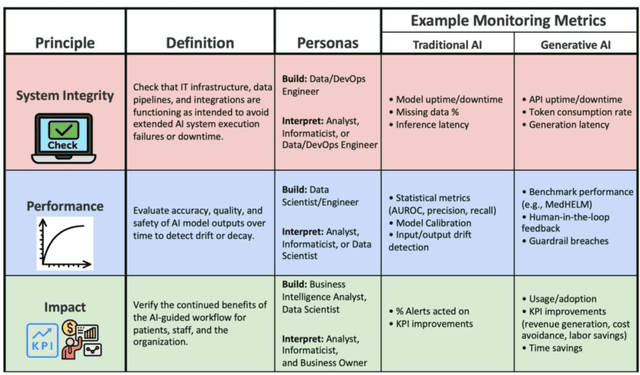
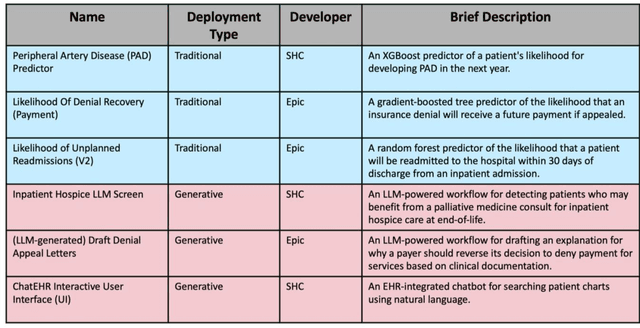
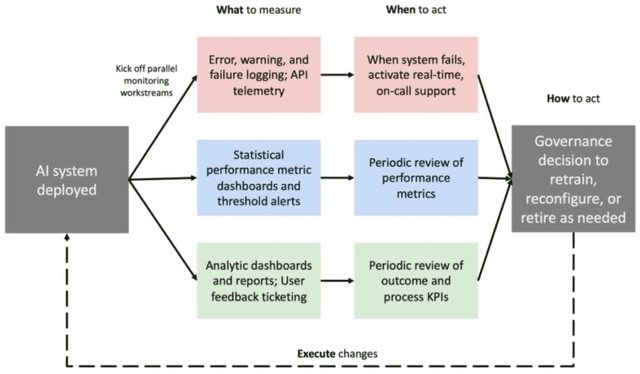
Post-deployment monitoring of artificial intelligence (AI) systems in health care is essential to ensure their safety, quality, and sustained benefit-and to support governance decisions about which systems to update, modify, or decommission. Motivated by these needs, we developed a framework for monitoring deployed AI systems grounded in the mandate to take specific actions when they fail to behave as intended. This framework, which is now actively used at Stanford Health Care, is organized around three complementary principles: system integrity, performance, and impact. System integrity monitoring focuses on maximizing system uptime, detecting runtime errors, and identifying when changes to the surrounding IT ecosystem have unintended effects. Performance monitoring focuses on maintaining accurate system behavior in the face of changing health care practices (and thus input data) over time. Impact monitoring assesses whether a deployed system continues to have value in the form of benefit to clinicians and patients. Drawing on examples of deployed AI systems at our academic medical center, we provide practical guidance for creating monitoring plans based on these principles that specify which metrics to measure, when those metrics should be reviewed, who is responsible for acting when metrics change, and what concrete follow-up actions should be taken-for both traditional and generative AI. We also discuss challenges to implementing this framework, including the effort and cost of monitoring for health systems with limited resources and the difficulty of incorporating data-driven monitoring practices into complex organizations where conflicting priorities and definitions of success often coexist. This framework offers a practical template and starting point for health systems seeking to ensure that AI deployments remain safe and effective over time.
The Optimization Paradox in Clinical AI Multi-Agent Systems
Jun 06, 2025Multi-agent artificial intelligence systems are increasingly deployed in clinical settings, yet the relationship between component-level optimization and system-wide performance remains poorly understood. We evaluated this relationship using 2,400 real patient cases from the MIMIC-CDM dataset across four abdominal pathologies (appendicitis, pancreatitis, cholecystitis, diverticulitis), decomposing clinical diagnosis into information gathering, interpretation, and differential diagnosis. We evaluated single agent systems (one model performing all tasks) against multi-agent systems (specialized models for each task) using comprehensive metrics spanning diagnostic outcomes, process adherence, and cost efficiency. Our results reveal a paradox: while multi-agent systems generally outperformed single agents, the component-optimized or Best of Breed system with superior components and excellent process metrics (85.5% information accuracy) significantly underperformed in diagnostic accuracy (67.7% vs. 77.4% for a top multi-agent system). This finding underscores that successful integration of AI in healthcare requires not just component level optimization but also attention to information flow and compatibility between agents. Our findings highlight the need for end to end system validation rather than relying on component metrics alone.
MedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Context Clues: Evaluating Long Context Models for Clinical Prediction Tasks on EHRs
Dec 09, 2024



Foundation Models (FMs) trained on Electronic Health Records (EHRs) have achieved state-of-the-art results on numerous clinical prediction tasks. However, most existing EHR FMs have context windows of <1k tokens. This prevents them from modeling full patient EHRs which can exceed 10k's of events. Recent advancements in subquadratic long-context architectures (e.g., Mamba) offer a promising solution. However, their application to EHR data has not been well-studied. We address this gap by presenting the first systematic evaluation of the effect of context length on modeling EHR data. We find that longer context models improve predictive performance -- our Mamba-based model surpasses the prior state-of-the-art on 9/14 tasks on the EHRSHOT prediction benchmark. For clinical applications, however, model performance alone is insufficient -- robustness to the unique properties of EHR is crucial. Thus, we also evaluate models across three previously underexplored properties of EHR data: (1) the prevalence of "copy-forwarded" diagnoses which creates artificial repetition of tokens within EHR sequences; (2) the irregular time intervals between EHR events which can lead to a wide range of timespans within a context window; and (3) the natural increase in disease complexity over time which makes later tokens in the EHR harder to predict than earlier ones. Stratifying our EHRSHOT results, we find that higher levels of each property correlate negatively with model performance, but that longer context models are more robust to more extreme levels of these properties. Our work highlights the potential for using long-context architectures to model EHR data, and offers a case study for identifying new challenges in modeling sequential data motivated by domains outside of natural language. We release our models and code at: https://github.com/som-shahlab/long_context_clues
Time-to-Event Pretraining for 3D Medical Imaging
Nov 14, 2024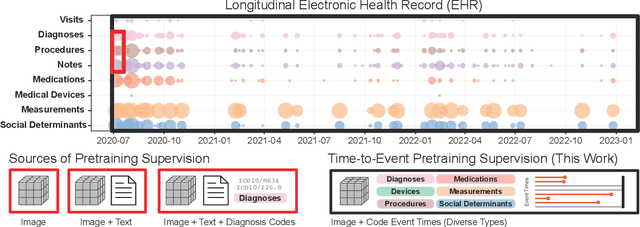
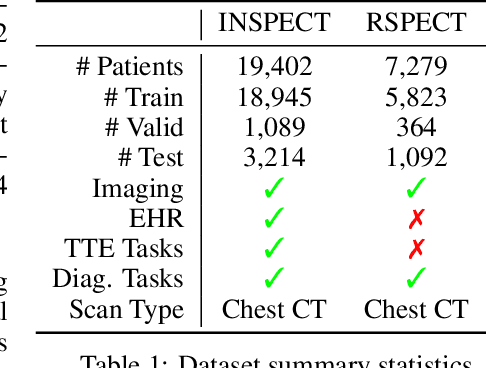
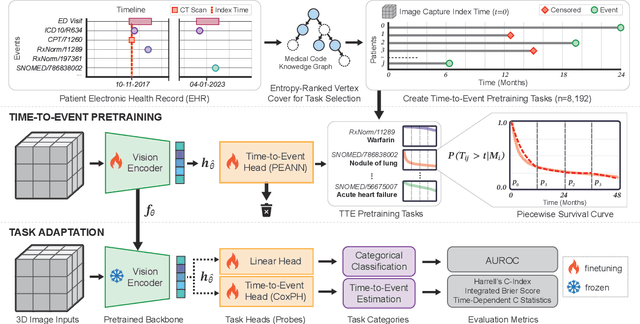
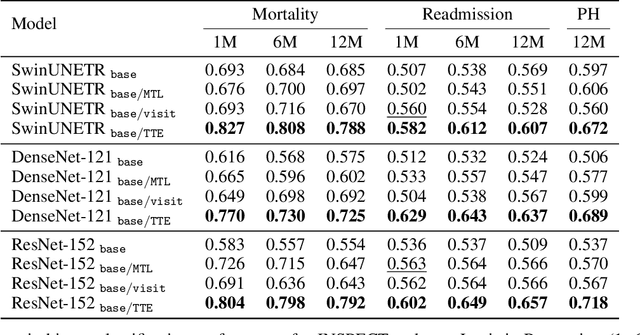
With the rise of medical foundation models and the growing availability of imaging data, scalable pretraining techniques offer a promising way to identify imaging biomarkers predictive of future disease risk. While current self-supervised methods for 3D medical imaging models capture local structural features like organ morphology, they fail to link pixel biomarkers with long-term health outcomes due to a missing context problem. Current approaches lack the temporal context necessary to identify biomarkers correlated with disease progression, as they rely on supervision derived only from images and concurrent text descriptions. To address this, we introduce time-to-event pretraining, a pretraining framework for 3D medical imaging models that leverages large-scale temporal supervision from paired, longitudinal electronic health records (EHRs). Using a dataset of 18,945 CT scans (4.2 million 2D images) and time-to-event distributions across thousands of EHR-derived tasks, our method improves outcome prediction, achieving an average AUROC increase of 23.7% and a 29.4% gain in Harrell's C-index across 8 benchmark tasks. Importantly, these gains are achieved without sacrificing diagnostic classification performance. This study lays the foundation for integrating longitudinal EHR and 3D imaging data to advance clinical risk prediction.
meds_reader: A fast and efficient EHR processing library
Sep 12, 2024



The growing demand for machine learning in healthcare requires processing increasingly large electronic health record (EHR) datasets, but existing pipelines are not computationally efficient or scalable. In this paper, we introduce meds_reader, an optimized Python package for efficient EHR data processing that is designed to take advantage of many intrinsic properties of EHR data for improved speed. We then demonstrate the benefits of meds_reader by reimplementing key components of two major EHR processing pipelines, achieving 10-100x improvements in memory, speed, and disk usage. The code for meds_reader can be found at https://github.com/som-shahlab/meds_reader.
Answering real-world clinical questions using large language model based systems
Jun 29, 2024



Evidence to guide healthcare decisions is often limited by a lack of relevant and trustworthy literature as well as difficulty in contextualizing existing research for a specific patient. Large language models (LLMs) could potentially address both challenges by either summarizing published literature or generating new studies based on real-world data (RWD). We evaluated the ability of five LLM-based systems in answering 50 clinical questions and had nine independent physicians review the responses for relevance, reliability, and actionability. As it stands, general-purpose LLMs (ChatGPT-4, Claude 3 Opus, Gemini Pro 1.5) rarely produced answers that were deemed relevant and evidence-based (2% - 10%). In contrast, retrieval augmented generation (RAG)-based and agentic LLM systems produced relevant and evidence-based answers for 24% (OpenEvidence) to 58% (ChatRWD) of questions. Only the agentic ChatRWD was able to answer novel questions compared to other LLMs (65% vs. 0-9%). These results suggest that while general-purpose LLMs should not be used as-is, a purpose-built system for evidence summarization based on RAG and one for generating novel evidence working synergistically would improve availability of pertinent evidence for patient care.