 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Real-time Assessment of Intracranial Hemorrhage Detection AI Using an Ensembled Monitoring Model (EMM)
May 16, 2025Artificial intelligence (AI) tools for radiology are commonly unmonitored once deployed. The lack of real-time case-by-case assessments of AI prediction confidence requires users to independently distinguish between trustworthy and unreliable AI predictions, which increases cognitive burden, reduces productivity, and potentially leads to misdiagnoses. To address these challenges, we introduce Ensembled Monitoring Model (EMM), a framework inspired by clinical consensus practices using multiple expert reviews. Designed specifically for black-box commercial AI products, EMM operates independently without requiring access to internal AI components or intermediate outputs, while still providing robust confidence measurements. Using intracranial hemorrhage detection as our test case on a large, diverse dataset of 2919 studies, we demonstrate that EMM successfully categorizes confidence in the AI-generated prediction, suggesting different actions and helping improve the overall performance of AI tools to ultimately reduce cognitive burden. Importantly, we provide key technical considerations and best practices for successfully translating EMM into clinical settings.
Efficient Noise Calculation in Deep Learning-based MRI Reconstructions
May 04, 2025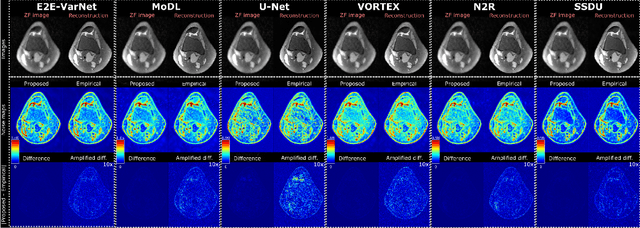
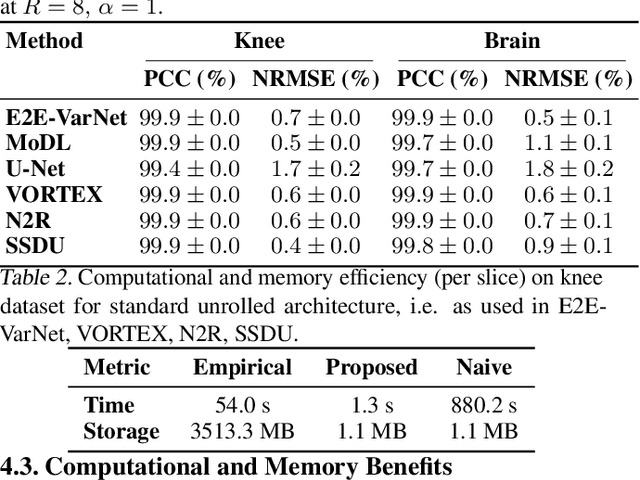
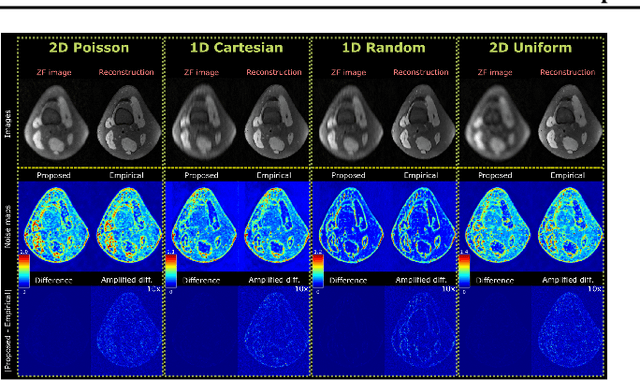
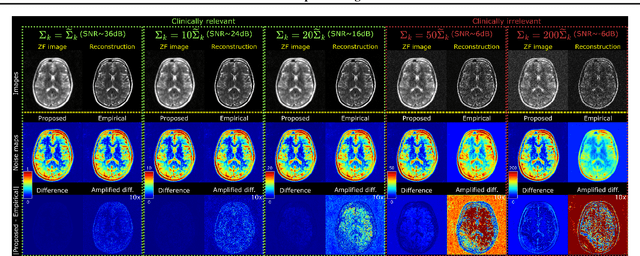
Accelerated MRI reconstruction involves solving an ill-posed inverse problem where noise in acquired data propagates to the reconstructed images. Noise analyses are central to MRI reconstruction for providing an explicit measure of solution fidelity and for guiding the design and deployment of novel reconstruction methods. However, deep learning (DL)-based reconstruction methods have often overlooked noise propagation due to inherent analytical and computational challenges, despite its critical importance. This work proposes a theoretically grounded, memory-efficient technique to calculate voxel-wise variance for quantifying uncertainty due to acquisition noise in accelerated MRI reconstructions. Our approach approximates noise covariance using the DL network's Jacobian, which is intractable to calculate. To circumvent this, we derive an unbiased estimator for the diagonal of this covariance matrix (voxel-wise variance) and introduce a Jacobian sketching technique to efficiently implement it. We evaluate our method on knee and brain MRI datasets for both data- and physics-driven networks trained in supervised and unsupervised manners. Compared to empirical references obtained via Monte Carlo simulations, our technique achieves near-equivalent performance while reducing computational and memory demands by an order of magnitude or more. Furthermore, our method is robust across varying input noise levels, acceleration factors, and diverse undersampling schemes, highlighting its broad applicability. Our work reintroduces accurate and efficient noise analysis as a central tenet of reconstruction algorithms, holding promise to reshape how we evaluate and deploy DL-based MRI. Our code will be made publicly available upon acceptance.
Time-to-Event Pretraining for 3D Medical Imaging
Nov 14, 2024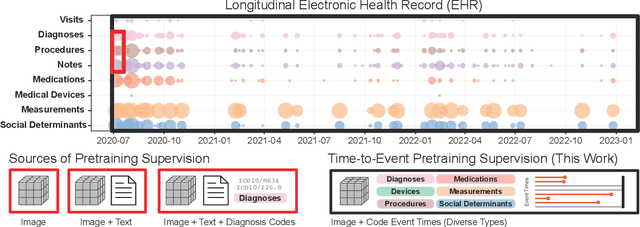
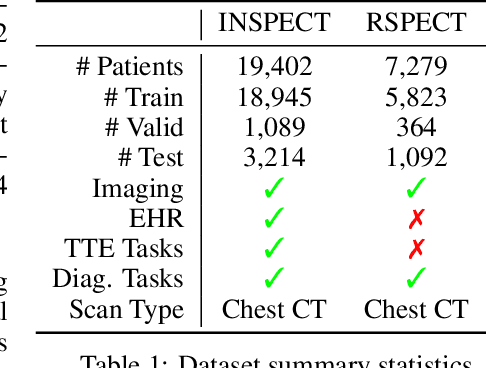
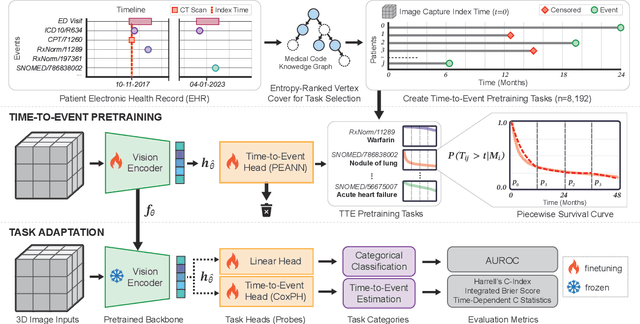
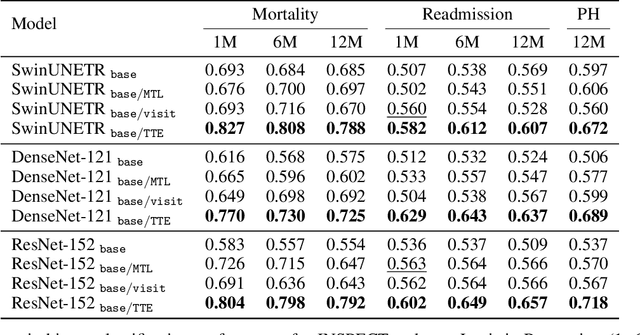
With the rise of medical foundation models and the growing availability of imaging data, scalable pretraining techniques offer a promising way to identify imaging biomarkers predictive of future disease risk. While current self-supervised methods for 3D medical imaging models capture local structural features like organ morphology, they fail to link pixel biomarkers with long-term health outcomes due to a missing context problem. Current approaches lack the temporal context necessary to identify biomarkers correlated with disease progression, as they rely on supervision derived only from images and concurrent text descriptions. To address this, we introduce time-to-event pretraining, a pretraining framework for 3D medical imaging models that leverages large-scale temporal supervision from paired, longitudinal electronic health records (EHRs). Using a dataset of 18,945 CT scans (4.2 million 2D images) and time-to-event distributions across thousands of EHR-derived tasks, our method improves outcome prediction, achieving an average AUROC increase of 23.7% and a 29.4% gain in Harrell's C-index across 8 benchmark tasks. Importantly, these gains are achieved without sacrificing diagnostic classification performance. This study lays the foundation for integrating longitudinal EHR and 3D imaging data to advance clinical risk prediction.
Detecting Underdiagnosed Medical Conditions with Deep Learning-Based Opportunistic CT Imaging
Sep 18, 2024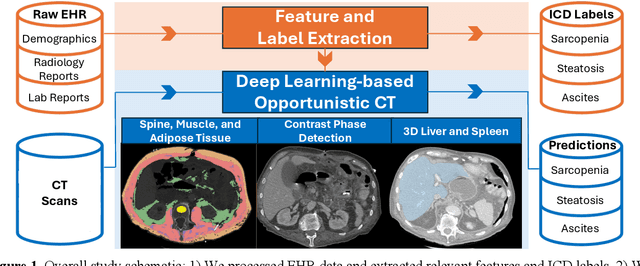
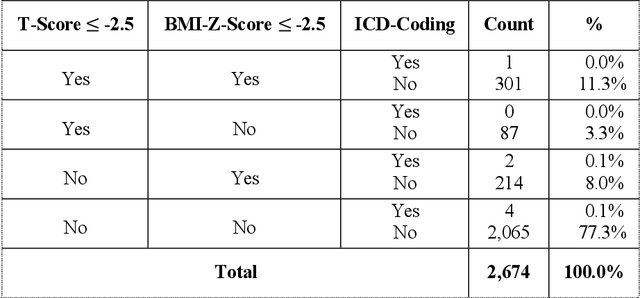
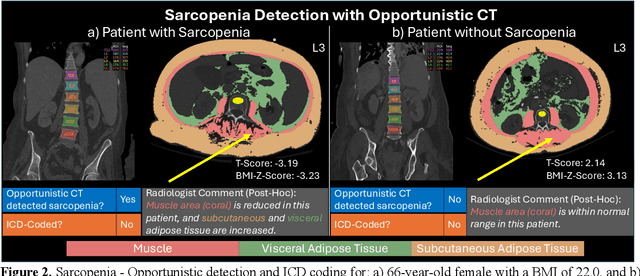
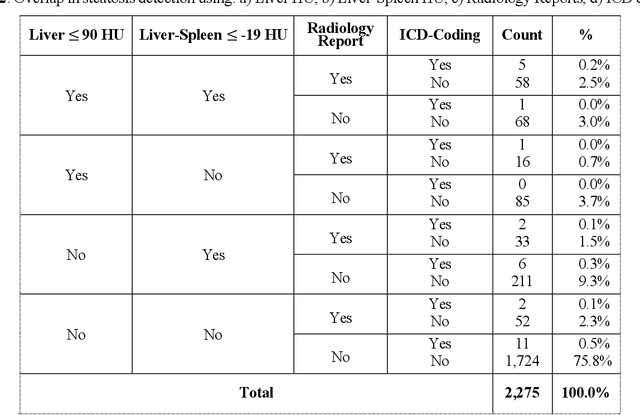
Abdominal computed tomography (CT) scans are frequently performed in clinical settings. Opportunistic CT involves repurposing routine CT images to extract diagnostic information and is an emerging tool for detecting underdiagnosed conditions such as sarcopenia, hepatic steatosis, and ascites. This study utilizes deep learning methods to promote accurate diagnosis and clinical documentation. We analyze 2,674 inpatient CT scans to identify discrepancies between imaging phenotypes (characteristics derived from opportunistic CT scans) and their corresponding documentation in radiology reports and ICD coding. Through our analysis, we find that only 0.5%, 3.2%, and 30.7% of scans diagnosed with sarcopenia, hepatic steatosis, and ascites (respectively) through either opportunistic imaging or radiology reports were ICD-coded. Our findings demonstrate opportunistic CT's potential to enhance diagnostic precision and accuracy of risk adjustment models, offering advancements in precision medicine.
Enhance the Image: Super Resolution using Artificial Intelligence in MRI
Jun 19, 2024



This chapter provides an overview of deep learning techniques for improving the spatial resolution of MRI, ranging from convolutional neural networks, generative adversarial networks, to more advanced models including transformers, diffusion models, and implicit neural representations. Our exploration extends beyond the methodologies to scrutinize the impact of super-resolved images on clinical and neuroscientific assessments. We also cover various practical topics such as network architectures, image evaluation metrics, network loss functions, and training data specifics, including downsampling methods for simulating low-resolution images and dataset selection. Finally, we discuss existing challenges and potential future directions regarding the feasibility and reliability of deep learning-based MRI super-resolution, with the aim to facilitate its wider adoption to benefit various clinical and neuroscientific applications.
Merlin: A Vision Language Foundation Model for 3D Computed Tomography
Jun 10, 2024



Over 85 million computed tomography (CT) scans are performed annually in the US, of which approximately one quarter focus on the abdomen. Given the current radiologist shortage, there is a large impetus to use artificial intelligence to alleviate the burden of interpreting these complex imaging studies. Prior state-of-the-art approaches for automated medical image interpretation leverage vision language models (VLMs). However, current medical VLMs are generally limited to 2D images and short reports, and do not leverage electronic health record (EHR) data for supervision. We introduce Merlin - a 3D VLM that we train using paired CT scans (6+ million images from 15,331 CTs), EHR diagnosis codes (1.8+ million codes), and radiology reports (6+ million tokens). We evaluate Merlin on 6 task types and 752 individual tasks. The non-adapted (off-the-shelf) tasks include zero-shot findings classification (31 findings), phenotype classification (692 phenotypes), and zero-shot cross-modal retrieval (image to findings and image to impressions), while model adapted tasks include 5-year disease prediction (6 diseases), radiology report generation, and 3D semantic segmentation (20 organs). We perform internal validation on a test set of 5,137 CTs, and external validation on 7,000 clinical CTs and on two public CT datasets (VerSe, TotalSegmentator). Beyond these clinically-relevant evaluations, we assess the efficacy of various network architectures and training strategies to depict that Merlin has favorable performance to existing task-specific baselines. We derive data scaling laws to empirically assess training data needs for requisite downstream task performance. Furthermore, unlike conventional VLMs that require hundreds of GPUs for training, we perform all training on a single GPU.
A Benchmark of Domain-Adapted Large Language Models for Generating Brief Hospital Course Summaries
Mar 08, 2024



Brief hospital course (BHC) summaries are common clinical documents generated by summarizing clinical notes. While large language models (LLMs) depict remarkable capabilities in automating real-world tasks, their capabilities for healthcare applications such as BHC synthesis have not been shown. To enable the adaptation of LLMs for BHC synthesis, we introduce a novel benchmark consisting of a pre-processed dataset extracted from MIMIC-IV notes, encapsulating clinical note, and brief hospital course (BHC) pairs. We assess the performance of two general-purpose LLMs and three healthcare-adapted LLMs to improve BHC synthesis from clinical notes. Using clinical notes as input for generating BHCs, we apply prompting-based (using in-context learning) and fine-tuning-based adaptation strategies to three open-source LLMs (Clinical-T5-Large, Llama2-13B, FLAN-UL2) and two proprietary LLMs (GPT-3.5, GPT-4). We quantitatively evaluate the performance of these LLMs across varying context-length inputs using conventional natural language similarity metrics. We further perform a qualitative study where five diverse clinicians blindly compare clinician-written BHCs and two LLM-generated BHCs for 30 samples across metrics of comprehensiveness, conciseness, factual correctness, and fluency. Overall, we present a new benchmark and pre-processed dataset for using LLMs in BHC synthesis from clinical notes. We observe high-quality summarization performance for both in-context proprietary and fine-tuned open-source LLMs using both quantitative metrics and a qualitative clinical reader study. We propose our work as a benchmark to motivate future works to adapt and assess the performance of LLMs in BHC synthesis.
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Jan 22, 2024



Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
Clinical Text Summarization: Adapting Large Language Models Can Outperform Human Experts
Sep 14, 2023Sifting through vast textual data and summarizing key information imposes a substantial burden on how clinicians allocate their time. Although large language models (LLMs) have shown immense promise in natural language processing (NLP) tasks, their efficacy across diverse clinical summarization tasks has not yet been rigorously examined. In this work, we employ domain adaptation methods on eight LLMs, spanning six datasets and four distinct summarization tasks: radiology reports, patient questions, progress notes, and doctor-patient dialogue. Our thorough quantitative assessment reveals trade-offs between models and adaptation methods in addition to instances where recent advances in LLMs may not lead to improved results. Further, in a clinical reader study with six physicians, we depict that summaries from the best adapted LLM are preferable to human summaries in terms of completeness and correctness. Our ensuing qualitative analysis delineates mutual challenges faced by both LLMs and human experts. Lastly, we correlate traditional quantitative NLP metrics with reader study scores to enhance our understanding of how these metrics align with physician preferences. Our research marks the first evidence of LLMs outperforming human experts in clinical text summarization across multiple tasks. This implies that integrating LLMs into clinical workflows could alleviate documentation burden, empowering clinicians to focus more on personalized patient care and other irreplaceable human aspects of medicine.
MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023
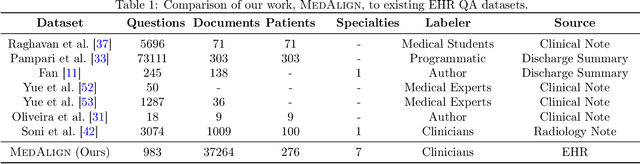


The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.