 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023
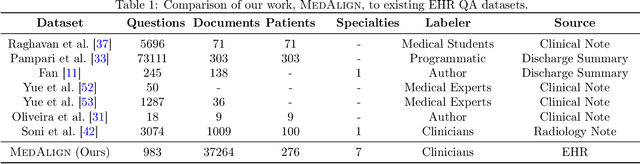


The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
Trove: Ontology-driven weak supervision for medical entity classification
Aug 05, 2020



Motivation: Recognizing named entities (NER) and their associated attributes like negation are core tasks in natural language processing. However, manually labeling data for entity tasks is time consuming and expensive, creating barriers to using machine learning in new medical applications. Weakly supervised learning, which automatically builds imperfect training sets from low cost, less accurate labeling rules, offers a potential solution. Medical ontologies are compelling sources for generating labels, however combining multiple ontologies without ground truth data creates challenges due to label noise introduced by conflicting entity definitions. Key questions remain on the extent to which weakly supervised entity classification can be automated using ontologies, or how much additional task-specific rule engineering is required for state-of-the-art performance. Also unclear is how pre-trained language models, such as BioBERT, improve the ability to generalize from imperfectly labeled data. Results: We present Trove, a framework for weakly supervised entity classification using medical ontologies. We report state-of-the-art, weakly supervised performance on two NER benchmark datasets and establish new baselines for two entity classification tasks in clinical text. We perform within an average of 3.5 F1 points (4.2%) of NER classifiers trained with hand-labeled data. Automatically learning label source accuracies to correct for label noise provided an average improvement of 3.9 F1 points. BioBERT provided an average improvement of 0.9 F1 points. We measure the impact of combining large numbers of ontologies and present a case study on rapidly building classifiers for COVID-19 clinical tasks. Our framework demonstrates how a wide range of medical entity classifiers can be quickly constructed using weak supervision and without requiring manually-labeled training data.
Missingness as Stability: Understanding the Structure of Missingness in Longitudinal EHR data and its Impact on Reinforcement Learning in Healthcare
Nov 16, 2019

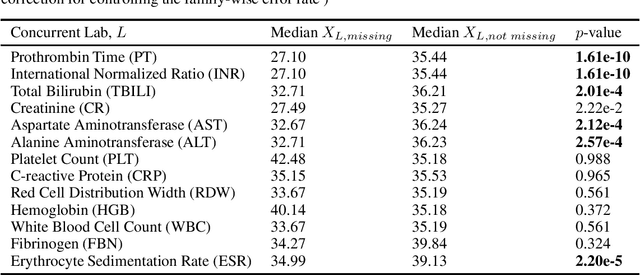
There is an emerging trend in the reinforcement learning for healthcare literature. In order to prepare longitudinal, irregularly sampled, clinical datasets for reinforcement learning algorithms, many researchers will resample the time series data to short, regular intervals and use last-observation-carried-forward (LOCF) imputation to fill in these gaps. Typically, they will not maintain any explicit information about which values were imputed. In this work, we (1) call attention to this practice and discuss its potential implications; (2) propose an alternative representation of the patient state that addresses some of these issues; and (3) demonstrate in a novel but representative clinical dataset that our alternative representation yields consistently better results for achieving optimal control, as measured by off-policy policy evaluation, compared to representations that do not incorporate missingness information.