 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Center Study on the Adaptability of a Shared Foundation Model for Electronic Health Records
Nov 20, 2023Foundation models hold promise for transforming AI in healthcare by providing modular components that are easily adaptable to downstream healthcare tasks, making AI development more scalable and cost-effective. Structured EHR foundation models, trained on coded medical records from millions of patients, demonstrated benefits including increased performance with fewer training labels, and improved robustness to distribution shifts. However, questions remain on the feasibility of sharing these models across different hospitals and their performance for local task adaptation. This multi-center study examined the adaptability of a recently released structured EHR foundation model ($FM_{SM}$), trained on longitudinal medical record data from 2.57M Stanford Medicine patients. Experiments were conducted using EHR data at The Hospital for Sick Children and MIMIC-IV. We assessed both adaptability via continued pretraining on local data, and task adaptability compared to baselines of training models from scratch at each site, including a local foundation model. We evaluated the performance of these models on 8 clinical prediction tasks. In both datasets, adapting the off-the-shelf $FM_{SM}$ matched the performance of GBM models locally trained on all data while providing a 13% improvement in settings with few task-specific training labels. With continued pretraining on local data, label efficiency substantially improved, such that $FM_{SM}$ required fewer than 1% of training examples to match the fully trained GBM's performance. Continued pretraining was also 60 to 90% more sample-efficient than training local foundation models from scratch. Our findings show that adapting shared EHR foundation models across hospitals provides improved prediction performance at less cost, underscoring the utility of base foundation models as modular components to streamline the development of healthcare AI.
Integrating Flowsheet Data in OMOP Common Data Model for Clinical Research
Sep 16, 2021

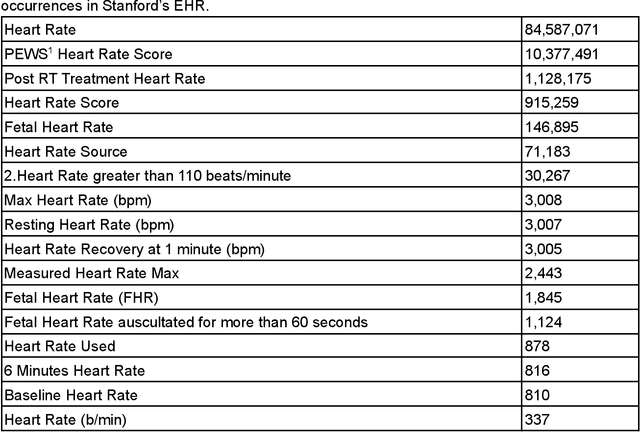

Flowsheet data presents unique challenges and opportunities for integration into standardized Common Data Models (CDMs) such as the Observational Medical Outcomes Partnership (OMOP) CDM from the Observational Health Data Sciences and Informatics (OHDSI) program. These data are a potentially rich source of detailed curated health outcomes data such as pain scores, vital signs, lines drains and airways (LDA) and other measurements that can be invaluable in building a robust model of patient health journey during an inpatient stay. We present two approaches to integration of flowsheet measures into the OMOP CDM. One approach was computationally straightforward but of potentially limited research utility. The second approach was far more computationally and labor intensive and involved mapping to standardized terms in controlled clinical vocabularies such as Logical Observation Identifiers Names and Codes (LOINC), resulting in a research data set of higher utility to population health studies.
Trove: Ontology-driven weak supervision for medical entity classification
Aug 05, 2020



Motivation: Recognizing named entities (NER) and their associated attributes like negation are core tasks in natural language processing. However, manually labeling data for entity tasks is time consuming and expensive, creating barriers to using machine learning in new medical applications. Weakly supervised learning, which automatically builds imperfect training sets from low cost, less accurate labeling rules, offers a potential solution. Medical ontologies are compelling sources for generating labels, however combining multiple ontologies without ground truth data creates challenges due to label noise introduced by conflicting entity definitions. Key questions remain on the extent to which weakly supervised entity classification can be automated using ontologies, or how much additional task-specific rule engineering is required for state-of-the-art performance. Also unclear is how pre-trained language models, such as BioBERT, improve the ability to generalize from imperfectly labeled data. Results: We present Trove, a framework for weakly supervised entity classification using medical ontologies. We report state-of-the-art, weakly supervised performance on two NER benchmark datasets and establish new baselines for two entity classification tasks in clinical text. We perform within an average of 3.5 F1 points (4.2%) of NER classifiers trained with hand-labeled data. Automatically learning label source accuracies to correct for label noise provided an average improvement of 3.9 F1 points. BioBERT provided an average improvement of 0.9 F1 points. We measure the impact of combining large numbers of ontologies and present a case study on rapidly building classifiers for COVID-19 clinical tasks. Our framework demonstrates how a wide range of medical entity classifiers can be quickly constructed using weak supervision and without requiring manually-labeled training data.