 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmerican Family Cohort, a data resource description
Sep 22, 2023This manuscript is a research resource description and presents a large and novel Electronic Health Records (EHR) data resource, American Family Cohort (AFC). The AFC data is derived from Centers for Medicare and Medicaid Services (CMS) certified American Board of Family Medicine (ABFM) PRIME registry. The PRIME registry is the largest national Qualified Clinical Data Registry (QCDR) for Primary Care. The data is converted to a popular common data model, the Observational Health Data Sciences and Informatics (OHDSI) Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM). The resource presents approximately 90 million encounters for 7.5 million patients. All 100% of the patients present age, gender, and address information, and 73% report race. Nealy 93% of patients have lab data in LOINC, 86% have medication data in RxNorm, 93% have diagnosis in SNOWMED and ICD, 81% have procedures in HCPCS or CPT, and 61% have insurance information. The richness, breadth, and diversity of this research accessible and research ready data is expected to accelerate observational studies in many diverse areas. We expect this resource to facilitate research in many years to come.
A study linking patient EHR data to external death data at Stanford Medicine
Nov 02, 2022This manuscript explores linking real-world patient data with external death data in the context of research Clinical Data Warehouses (r-CDWs). We specifically present the linking of Electronic Health Records (EHR) data for Stanford Health Care (SHC) patients and data from the Social Security Administration (SSA) Limited Access Death Master File (LADMF) made available by the US Department of Commerce's National Technical Information Service (NTIS). The data analysis framework presented in this manuscript extends prior approaches and is generalizable to linking any two cross-organizational real-world patient data sources. Electronic Health Record (EHR) data and NTIS LADMF are heavily used resources at other medical centers and we expect that the methods and learnings presented here will be valuable to others. Our findings suggest that strong linkages are incomplete and weak linkages are noisy i.e., there is no good linkage rule that provides coverage and accuracy. Furthermore, the best linkage rule for any two datasets is different from the best linkage rule for two other datasets i.e., there is no generalization of linkage rules. Finally, LADMF, a commonly used external death data resource for r-CDWs, has a significant gap in death data making it necessary for r-CDWs to seek out more than one external death data source. We anticipate that presentation of multiple linkages will make it hard to present the linkage outcome to the end user. This manuscript is a resource in support of Stanford Medicine STARR (STAnford medicine Research data Repository) r-CDWs. The data are stored and analyzed as PHI in our HIPAA-compliant data center and are used under research and development (R&D) activities of STARR IRB.
Integrating Flowsheet Data in OMOP Common Data Model for Clinical Research
Sep 16, 2021

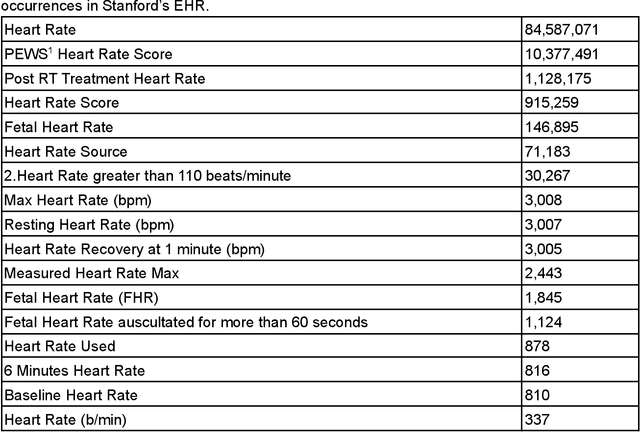

Flowsheet data presents unique challenges and opportunities for integration into standardized Common Data Models (CDMs) such as the Observational Medical Outcomes Partnership (OMOP) CDM from the Observational Health Data Sciences and Informatics (OHDSI) program. These data are a potentially rich source of detailed curated health outcomes data such as pain scores, vital signs, lines drains and airways (LDA) and other measurements that can be invaluable in building a robust model of patient health journey during an inpatient stay. We present two approaches to integration of flowsheet measures into the OMOP CDM. One approach was computationally straightforward but of potentially limited research utility. The second approach was far more computationally and labor intensive and involved mapping to standardized terms in controlled clinical vocabularies such as Logical Observation Identifiers Names and Codes (LOINC), resulting in a research data set of higher utility to population health studies.
A highly scalable repository of waveform and vital signs data from bedside monitoring devices
Jun 07, 2021

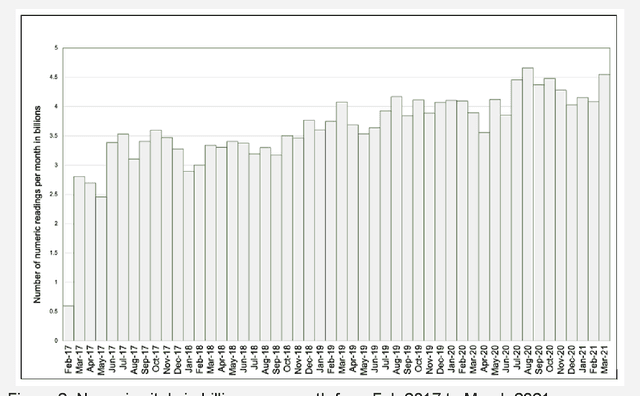

The advent of cost effective cloud computing over the past decade and ever-growing accumulation of high-fidelity clinical data in a modern hospital setting is leading to new opportunities for translational medicine. Machine learning is driving the appetite of the research community for various types of signal data such as patient vitals. Health care systems, however, are ill suited for massive processing of large volumes of data. In addition, due to the sheer magnitude of the data being collected, it is not feasible to retain all of the data in health care systems in perpetuity. This gold mine of information gets purged periodically thereby losing invaluable future research opportunities. We have developed a highly scalable solution that: a) siphons off patient vital data on a nightly basis from on-premises bio-medical systems to a cloud storage location as a permanent archive, b) reconstructs the database in the cloud, c) generates waveforms, alarms and numeric data in a research-ready format, and d) uploads the processed data to a storage location in the cloud ready for research. The data is de-identified and catalogued such that it can be joined with Electronic Medical Records (EMR) and other ancillary data types such as electroencephalogram (EEG), radiology, video monitoring etc. This technique eliminates the research burden from health care systems. This highly scalable solution is used to process high density patient monitoring data aggregated by the Philips Patient Information Center iX (PIC iX) hospital surveillance system for archival storage in the Philips Data Warehouse Connect enterprise-level database. The solution is part of a broader platform that supports a secure high performance clinical data science platform.