 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonitoring Deployed AI Systems in Health Care
Dec 09, 2025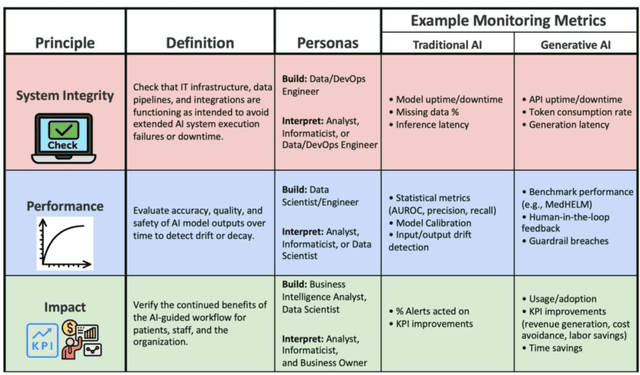
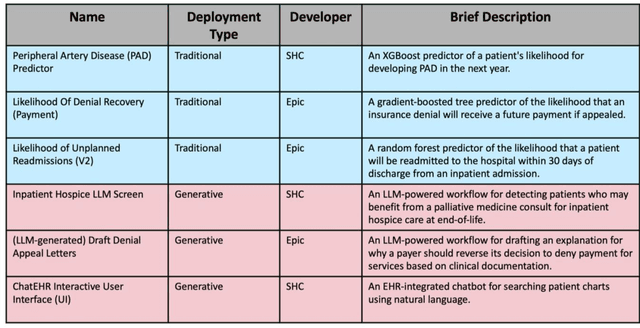
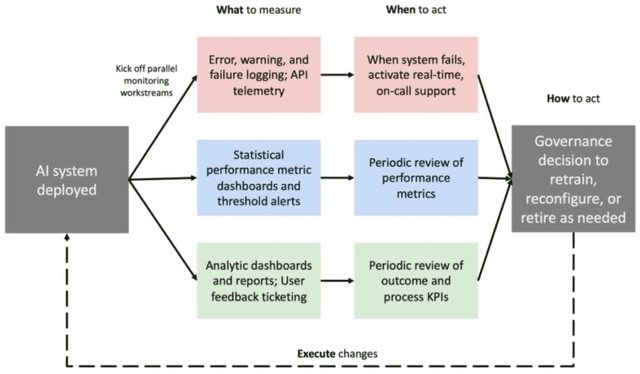
Post-deployment monitoring of artificial intelligence (AI) systems in health care is essential to ensure their safety, quality, and sustained benefit-and to support governance decisions about which systems to update, modify, or decommission. Motivated by these needs, we developed a framework for monitoring deployed AI systems grounded in the mandate to take specific actions when they fail to behave as intended. This framework, which is now actively used at Stanford Health Care, is organized around three complementary principles: system integrity, performance, and impact. System integrity monitoring focuses on maximizing system uptime, detecting runtime errors, and identifying when changes to the surrounding IT ecosystem have unintended effects. Performance monitoring focuses on maintaining accurate system behavior in the face of changing health care practices (and thus input data) over time. Impact monitoring assesses whether a deployed system continues to have value in the form of benefit to clinicians and patients. Drawing on examples of deployed AI systems at our academic medical center, we provide practical guidance for creating monitoring plans based on these principles that specify which metrics to measure, when those metrics should be reviewed, who is responsible for acting when metrics change, and what concrete follow-up actions should be taken-for both traditional and generative AI. We also discuss challenges to implementing this framework, including the effort and cost of monitoring for health systems with limited resources and the difficulty of incorporating data-driven monitoring practices into complex organizations where conflicting priorities and definitions of success often coexist. This framework offers a practical template and starting point for health systems seeking to ensure that AI deployments remain safe and effective over time.
Standing on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023
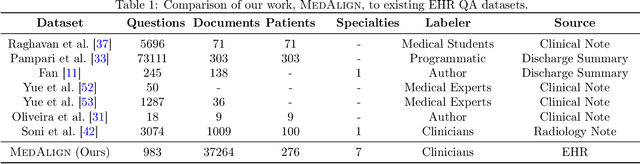


The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
BigBIO: A Framework for Data-Centric Biomedical Natural Language Processing
Jun 30, 2022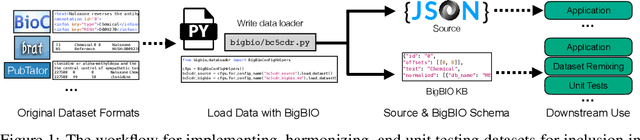
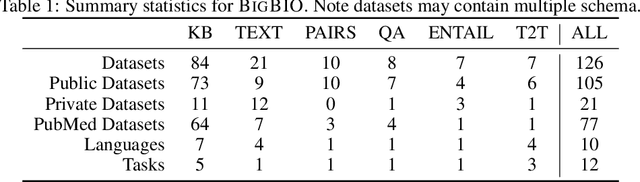

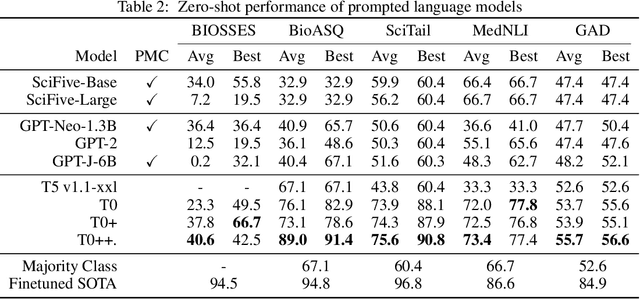
Training and evaluating language models increasingly requires the construction of meta-datasets --diverse collections of curated data with clear provenance. Natural language prompting has recently lead to improved zero-shot generalization by transforming existing, supervised datasets into a diversity of novel pretraining tasks, highlighting the benefits of meta-dataset curation. While successful in general-domain text, translating these data-centric approaches to biomedical language modeling remains challenging, as labeled biomedical datasets are significantly underrepresented in popular data hubs. To address this challenge, we introduce BigBIO a community library of 126+ biomedical NLP datasets, currently covering 12 task categories and 10+ languages. BigBIO facilitates reproducible meta-dataset curation via programmatic access to datasets and their metadata, and is compatible with current platforms for prompt engineering and end-to-end few/zero shot language model evaluation. We discuss our process for task schema harmonization, data auditing, contribution guidelines, and outline two illustrative use cases: zero-shot evaluation of biomedical prompts and large-scale, multi-task learning. BigBIO is an ongoing community effort and is available at https://github.com/bigscience-workshop/biomedical
Trove: Ontology-driven weak supervision for medical entity classification
Aug 05, 2020



Motivation: Recognizing named entities (NER) and their associated attributes like negation are core tasks in natural language processing. However, manually labeling data for entity tasks is time consuming and expensive, creating barriers to using machine learning in new medical applications. Weakly supervised learning, which automatically builds imperfect training sets from low cost, less accurate labeling rules, offers a potential solution. Medical ontologies are compelling sources for generating labels, however combining multiple ontologies without ground truth data creates challenges due to label noise introduced by conflicting entity definitions. Key questions remain on the extent to which weakly supervised entity classification can be automated using ontologies, or how much additional task-specific rule engineering is required for state-of-the-art performance. Also unclear is how pre-trained language models, such as BioBERT, improve the ability to generalize from imperfectly labeled data. Results: We present Trove, a framework for weakly supervised entity classification using medical ontologies. We report state-of-the-art, weakly supervised performance on two NER benchmark datasets and establish new baselines for two entity classification tasks in clinical text. We perform within an average of 3.5 F1 points (4.2%) of NER classifiers trained with hand-labeled data. Automatically learning label source accuracies to correct for label noise provided an average improvement of 3.9 F1 points. BioBERT provided an average improvement of 0.9 F1 points. We measure the impact of combining large numbers of ontologies and present a case study on rapidly building classifiers for COVID-19 clinical tasks. Our framework demonstrates how a wide range of medical entity classifiers can be quickly constructed using weak supervision and without requiring manually-labeled training data.
Medical device surveillance with electronic health records
Apr 03, 2019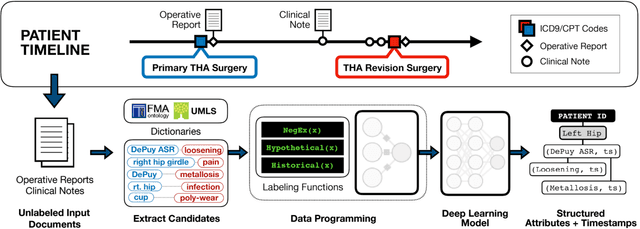
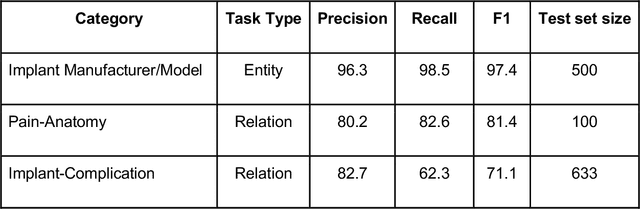

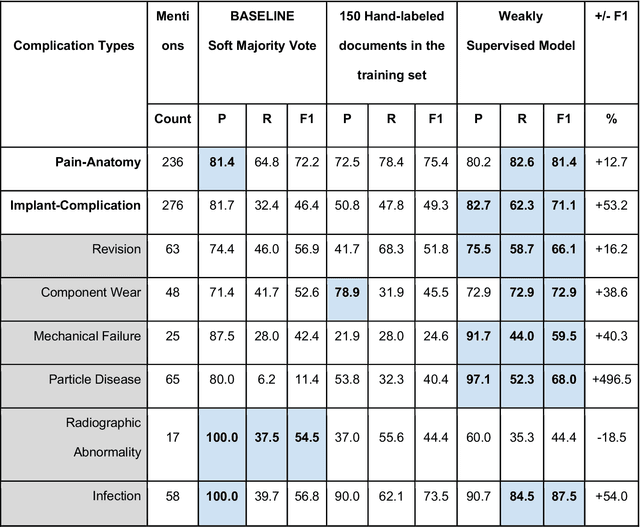
Post-market medical device surveillance is a challenge facing manufacturers, regulatory agencies, and health care providers. Electronic health records are valuable sources of real world evidence to assess device safety and track device-related patient outcomes over time. However, distilling this evidence remains challenging, as information is fractured across clinical notes and structured records. Modern machine learning methods for machine reading promise to unlock increasingly complex information from text, but face barriers due to their reliance on large and expensive hand-labeled training sets. To address these challenges, we developed and validated state-of-the-art deep learning methods that identify patient outcomes from clinical notes without requiring hand-labeled training data. Using hip replacements as a test case, our methods accurately extracted implant details and reports of complications and pain from electronic health records with up to 96.3% precision, 98.5% recall, and 97.4% F1, improved classification performance by 12.7- 53.0% over rule-based methods, and detected over 6 times as many complication events compared to using structured data alone. Using these events to assess complication-free survivorship of different implant systems, we found significant variation between implants, including for risk of revision surgery, which could not be detected using coded data alone. Patients with revision surgeries had more hip pain mentions in the post-hip replacement, pre-revision period compared to patients with no evidence of revision surgery (mean hip pain mentions 4.97 vs. 3.23; t = 5.14; p < 0.001). Some implant models were associated with higher or lower rates of hip pain mentions. Our methods complement existing surveillance mechanisms by requiring orders of magnitude less hand-labeled training data, offering a scalable solution for national medical device surveillance.