 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINSPECT: A Multimodal Dataset for Pulmonary Embolism Diagnosis and Prognosis
Nov 17, 2023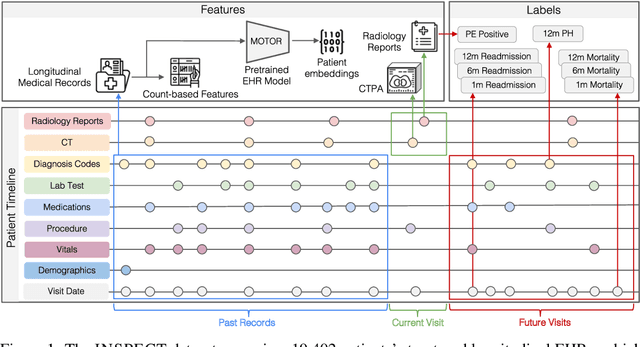
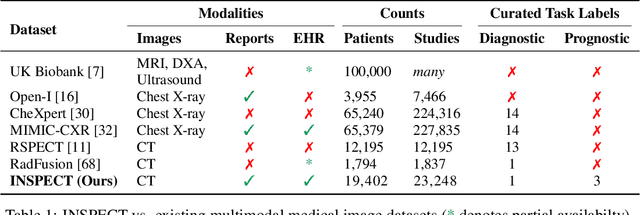
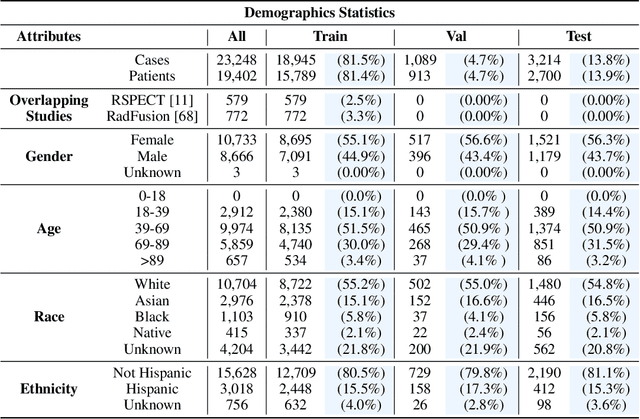
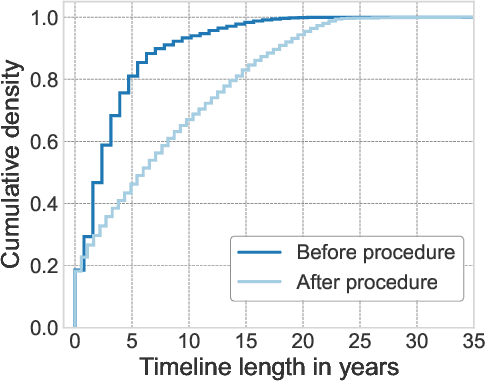
Synthesizing information from multiple data sources plays a crucial role in the practice of modern medicine. Current applications of artificial intelligence in medicine often focus on single-modality data due to a lack of publicly available, multimodal medical datasets. To address this limitation, we introduce INSPECT, which contains de-identified longitudinal records from a large cohort of patients at risk for pulmonary embolism (PE), along with ground truth labels for multiple outcomes. INSPECT contains data from 19,402 patients, including CT images, radiology report impression sections, and structured electronic health record (EHR) data (i.e. demographics, diagnoses, procedures, vitals, and medications). Using INSPECT, we develop and release a benchmark for evaluating several baseline modeling approaches on a variety of important PE related tasks. We evaluate image-only, EHR-only, and multimodal fusion models. Trained models and the de-identified dataset are made available for non-commercial use under a data use agreement. To the best of our knowledge, INSPECT is the largest multimodal dataset integrating 3D medical imaging and EHR for reproducible methods evaluation and research.
MedAlign: A Clinician-Generated Dataset for Instruction Following with Electronic Medical Records
Aug 27, 2023
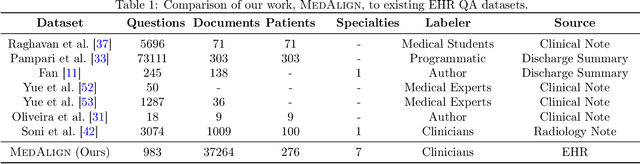


The ability of large language models (LLMs) to follow natural language instructions with human-level fluency suggests many opportunities in healthcare to reduce administrative burden and improve quality of care. However, evaluating LLMs on realistic text generation tasks for healthcare remains challenging. Existing question answering datasets for electronic health record (EHR) data fail to capture the complexity of information needs and documentation burdens experienced by clinicians. To address these challenges, we introduce MedAlign, a benchmark dataset of 983 natural language instructions for EHR data. MedAlign is curated by 15 clinicians (7 specialities), includes clinician-written reference responses for 303 instructions, and provides 276 longitudinal EHRs for grounding instruction-response pairs. We used MedAlign to evaluate 6 general domain LLMs, having clinicians rank the accuracy and quality of each LLM response. We found high error rates, ranging from 35% (GPT-4) to 68% (MPT-7B-Instruct), and an 8.3% drop in accuracy moving from 32k to 2k context lengths for GPT-4. Finally, we report correlations between clinician rankings and automated natural language generation metrics as a way to rank LLMs without human review. We make MedAlign available under a research data use agreement to enable LLM evaluations on tasks aligned with clinician needs and preferences.
Language Models in the Loop: Incorporating Prompting into Weak Supervision
May 04, 2022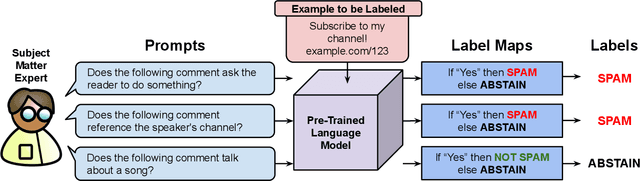

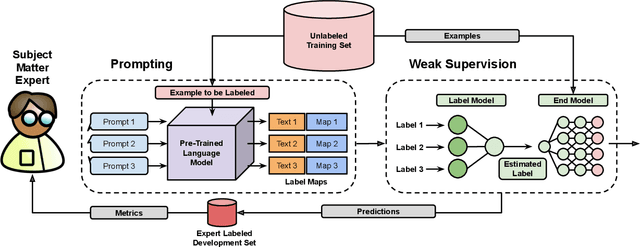

We propose a new strategy for applying large pre-trained language models to novel tasks when labeled training data is limited. Rather than apply the model in a typical zero-shot or few-shot fashion, we treat the model as the basis for labeling functions in a weak supervision framework. To create a classifier, we first prompt the model to answer multiple distinct queries about an example and define how the possible responses should be mapped to votes for labels and abstentions. We then denoise these noisy label sources using the Snorkel system and train an end classifier with the resulting training data. Our experimental evaluation shows that prompting large language models within a weak supervision framework can provide significant gains in accuracy. On the WRENCH weak supervision benchmark, this approach can significantly improve over zero-shot performance, an average 19.5% reduction in errors. We also find that this approach produces classifiers with comparable or superior accuracy to those trained from hand-engineered rules.
Trove: Ontology-driven weak supervision for medical entity classification
Aug 05, 2020



Motivation: Recognizing named entities (NER) and their associated attributes like negation are core tasks in natural language processing. However, manually labeling data for entity tasks is time consuming and expensive, creating barriers to using machine learning in new medical applications. Weakly supervised learning, which automatically builds imperfect training sets from low cost, less accurate labeling rules, offers a potential solution. Medical ontologies are compelling sources for generating labels, however combining multiple ontologies without ground truth data creates challenges due to label noise introduced by conflicting entity definitions. Key questions remain on the extent to which weakly supervised entity classification can be automated using ontologies, or how much additional task-specific rule engineering is required for state-of-the-art performance. Also unclear is how pre-trained language models, such as BioBERT, improve the ability to generalize from imperfectly labeled data. Results: We present Trove, a framework for weakly supervised entity classification using medical ontologies. We report state-of-the-art, weakly supervised performance on two NER benchmark datasets and establish new baselines for two entity classification tasks in clinical text. We perform within an average of 3.5 F1 points (4.2%) of NER classifiers trained with hand-labeled data. Automatically learning label source accuracies to correct for label noise provided an average improvement of 3.9 F1 points. BioBERT provided an average improvement of 0.9 F1 points. We measure the impact of combining large numbers of ontologies and present a case study on rapidly building classifiers for COVID-19 clinical tasks. Our framework demonstrates how a wide range of medical entity classifiers can be quickly constructed using weak supervision and without requiring manually-labeled training data.
Language Models Are An Effective Patient Representation Learning Technique For Electronic Health Record Data
Jan 06, 2020

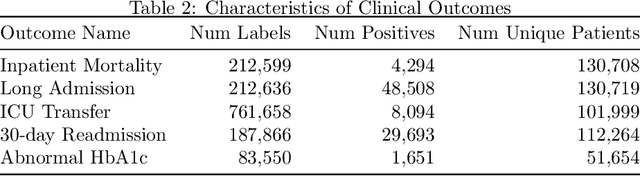

Widespread adoption of electronic health records (EHRs) has fueled development of clinical outcome models using machine learning. However, patient EHR data are complex, and how to optimally represent them is an open question. This complexity, along with often small training set sizes available to train these clinical outcome models, are two core challenges for training high quality models. In this paper, we demonstrate that learning generic representations from the data of all the patients in the EHR enables better performing prediction models for clinical outcomes, allowing for these challenges to be overcome. We adapt common representation learning techniques used in other domains and find that representations inspired by language models enable a 3.5% mean improvement in AUROC on five clinical outcomes compared to standard baselines, with the average improvement rising to 19% when only a small number of patients are available for training a prediction model for a given clinical outcome.