 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Are An Effective Patient Representation Learning Technique For Electronic Health Record Data
Paper and Code
Jan 06, 2020

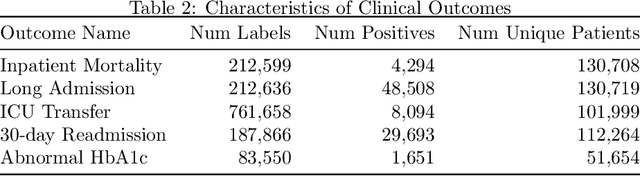

Widespread adoption of electronic health records (EHRs) has fueled development of clinical outcome models using machine learning. However, patient EHR data are complex, and how to optimally represent them is an open question. This complexity, along with often small training set sizes available to train these clinical outcome models, are two core challenges for training high quality models. In this paper, we demonstrate that learning generic representations from the data of all the patients in the EHR enables better performing prediction models for clinical outcomes, allowing for these challenges to be overcome. We adapt common representation learning techniques used in other domains and find that representations inspired by language models enable a 3.5% mean improvement in AUROC on five clinical outcomes compared to standard baselines, with the average improvement rising to 19% when only a small number of patients are available for training a prediction model for a given clinical outcome.