 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models Are An Effective Patient Representation Learning Technique For Electronic Health Record Data
Jan 06, 2020

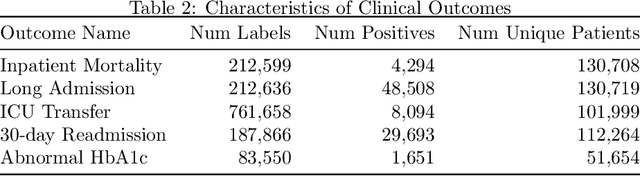

Widespread adoption of electronic health records (EHRs) has fueled development of clinical outcome models using machine learning. However, patient EHR data are complex, and how to optimally represent them is an open question. This complexity, along with often small training set sizes available to train these clinical outcome models, are two core challenges for training high quality models. In this paper, we demonstrate that learning generic representations from the data of all the patients in the EHR enables better performing prediction models for clinical outcomes, allowing for these challenges to be overcome. We adapt common representation learning techniques used in other domains and find that representations inspired by language models enable a 3.5% mean improvement in AUROC on five clinical outcomes compared to standard baselines, with the average improvement rising to 19% when only a small number of patients are available for training a prediction model for a given clinical outcome.
Synth-Validation: Selecting the Best Causal Inference Method for a Given Dataset
Oct 31, 2017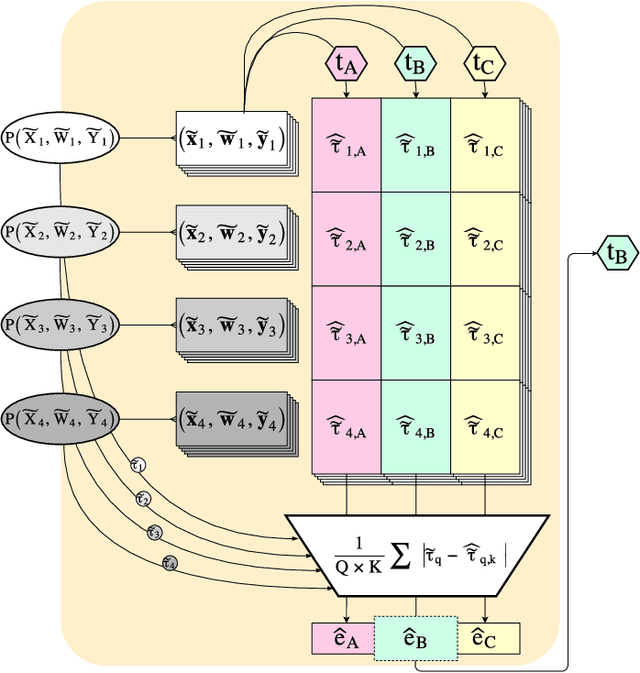
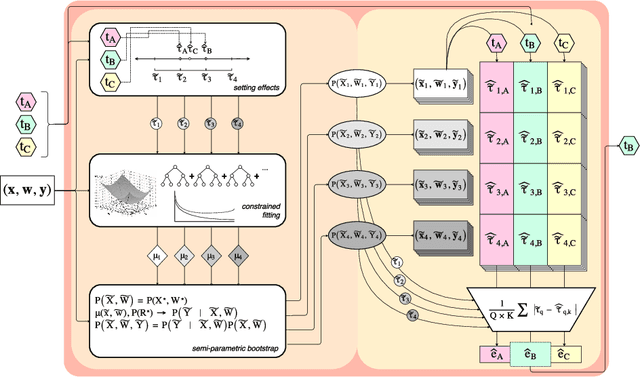
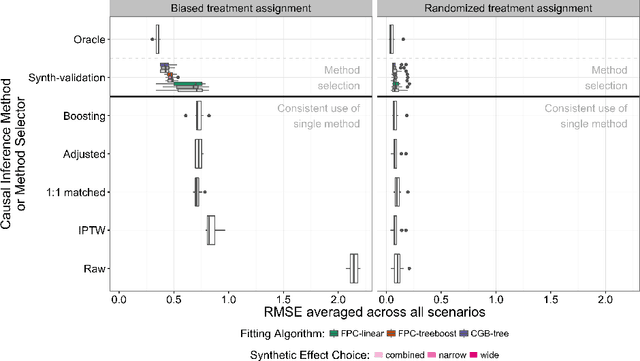
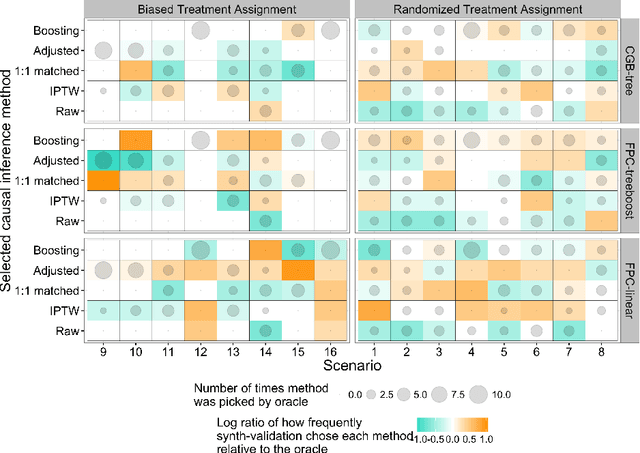
Many decisions in healthcare, business, and other policy domains are made without the support of rigorous evidence due to the cost and complexity of performing randomized experiments. Using observational data to answer causal questions is risky: subjects who receive different treatments also differ in other ways that affect outcomes. Many causal inference methods have been developed to mitigate these biases. However, there is no way to know which method might produce the best estimate of a treatment effect in a given study. In analogy to cross-validation, which estimates the prediction error of predictive models applied to a given dataset, we propose synth-validation, a procedure that estimates the estimation error of causal inference methods applied to a given dataset. In synth-validation, we use the observed data to estimate generative distributions with known treatment effects. We apply each causal inference method to datasets sampled from these distributions and compare the effect estimates with the known effects to estimate error. Using simulations, we show that using synth-validation to select a causal inference method for each study lowers the expected estimation error relative to consistently using any single method.