 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStanding on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
DEPLOYR: A technical framework for deploying custom real-time machine learning models into the electronic medical record
Mar 11, 2023Machine learning (ML) applications in healthcare are extensively researched, but successful translations to the bedside are scant. Healthcare institutions are establishing frameworks to govern and promote the implementation of accurate, actionable and reliable models that integrate with clinical workflow. Such governance frameworks require an accompanying technical framework to deploy models in a resource efficient manner. Here we present DEPLOYR, a technical framework for enabling real-time deployment and monitoring of researcher created clinical ML models into a widely used electronic medical record (EMR) system. We discuss core functionality and design decisions, including mechanisms to trigger inference based on actions within EMR software, modules that collect real-time data to make inferences, mechanisms that close-the-loop by displaying inferences back to end-users within their workflow, monitoring modules that track performance of deployed models over time, silent deployment capabilities, and mechanisms to prospectively evaluate a deployed model's impact. We demonstrate the use of DEPLOYR by silently deploying and prospectively evaluating twelve ML models triggered by clinician button-clicks in Stanford Health Care's production instance of Epic. Our study highlights the need and feasibility for such silent deployment, because prospectively measured performance varies from retrospective estimates. By describing DEPLOYR, we aim to inform ML deployment best practices and help bridge the model implementation gap.
Avoiding Biased Clinical Machine Learning Model Performance Estimates in the Presence of Label Selection
Sep 15, 2022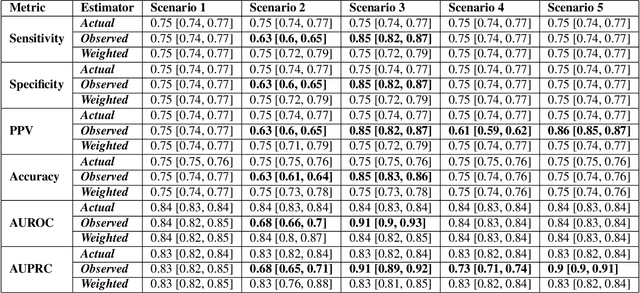

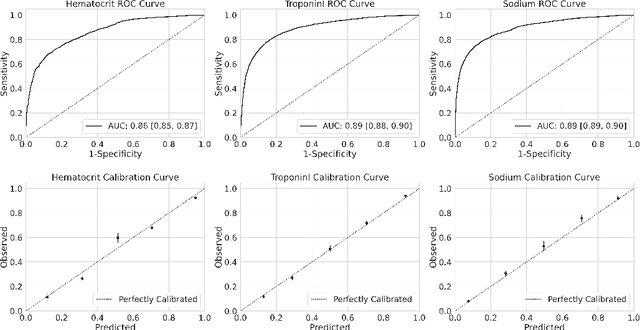

When evaluating the performance of clinical machine learning models, one must consider the deployment population. When the population of patients with observed labels is only a subset of the deployment population (label selection), standard model performance estimates on the observed population may be misleading. In this study we describe three classes of label selection and simulate five causally distinct scenarios to assess how particular selection mechanisms bias a suite of commonly reported binary machine learning model performance metrics. Simulations reveal that when selection is affected by observed features, naive estimates of model discrimination may be misleading. When selection is affected by labels, naive estimates of calibration fail to reflect reality. We borrow traditional weighting estimators from causal inference literature and find that when selection probabilities are properly specified, they recover full population estimates. We then tackle the real-world task of monitoring the performance of deployed machine learning models whose interactions with clinicians feed-back and affect the selection mechanism of the labels. We train three machine learning models to flag low-yield laboratory diagnostics, and simulate their intended consequence of reducing wasteful laboratory utilization. We find that naive estimates of AUROC on the observed population undershoot actual performance by up to 20%. Such a disparity could be large enough to lead to the wrongful termination of a successful clinical decision support tool. We propose an altered deployment procedure, one that combines injected randomization with traditional weighted estimates, and find it recovers true model performance.
Language Models Are An Effective Patient Representation Learning Technique For Electronic Health Record Data
Jan 06, 2020

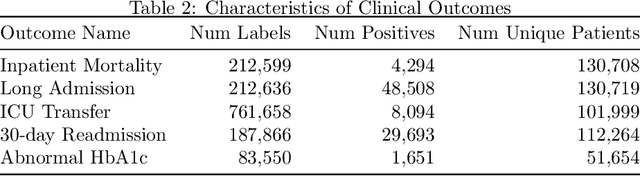

Widespread adoption of electronic health records (EHRs) has fueled development of clinical outcome models using machine learning. However, patient EHR data are complex, and how to optimally represent them is an open question. This complexity, along with often small training set sizes available to train these clinical outcome models, are two core challenges for training high quality models. In this paper, we demonstrate that learning generic representations from the data of all the patients in the EHR enables better performing prediction models for clinical outcomes, allowing for these challenges to be overcome. We adapt common representation learning techniques used in other domains and find that representations inspired by language models enable a 3.5% mean improvement in AUROC on five clinical outcomes compared to standard baselines, with the average improvement rising to 19% when only a small number of patients are available for training a prediction model for a given clinical outcome.