 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedHELM: Holistic Evaluation of Large Language Models for Medical Tasks
May 26, 2025



While large language models (LLMs) achieve near-perfect scores on medical licensing exams, these evaluations inadequately reflect the complexity and diversity of real-world clinical practice. We introduce MedHELM, an extensible evaluation framework for assessing LLM performance for medical tasks with three key contributions. First, a clinician-validated taxonomy spanning 5 categories, 22 subcategories, and 121 tasks developed with 29 clinicians. Second, a comprehensive benchmark suite comprising 35 benchmarks (17 existing, 18 newly formulated) providing complete coverage of all categories and subcategories in the taxonomy. Third, a systematic comparison of LLMs with improved evaluation methods (using an LLM-jury) and a cost-performance analysis. Evaluation of 9 frontier LLMs, using the 35 benchmarks, revealed significant performance variation. Advanced reasoning models (DeepSeek R1: 66% win-rate; o3-mini: 64% win-rate) demonstrated superior performance, though Claude 3.5 Sonnet achieved comparable results at 40% lower estimated computational cost. On a normalized accuracy scale (0-1), most models performed strongly in Clinical Note Generation (0.73-0.85) and Patient Communication & Education (0.78-0.83), moderately in Medical Research Assistance (0.65-0.75), and generally lower in Clinical Decision Support (0.56-0.72) and Administration & Workflow (0.53-0.63). Our LLM-jury evaluation method achieved good agreement with clinician ratings (ICC = 0.47), surpassing both average clinician-clinician agreement (ICC = 0.43) and automated baselines including ROUGE-L (0.36) and BERTScore-F1 (0.44). Claude 3.5 Sonnet achieved comparable performance to top models at lower estimated cost. These findings highlight the importance of real-world, task-specific evaluation for medical use of LLMs and provides an open source framework to enable this.
Superhuman performance of a large language model on the reasoning tasks of a physician
Dec 14, 2024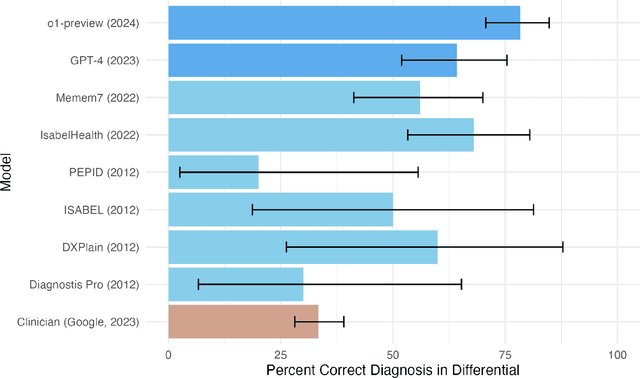
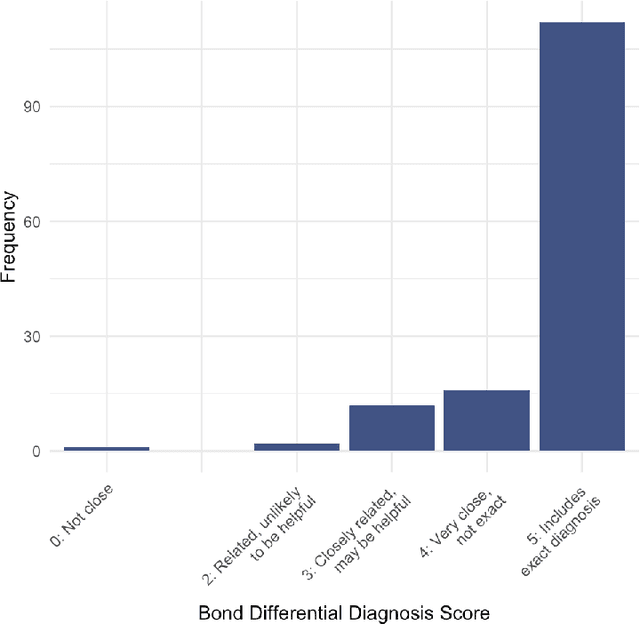

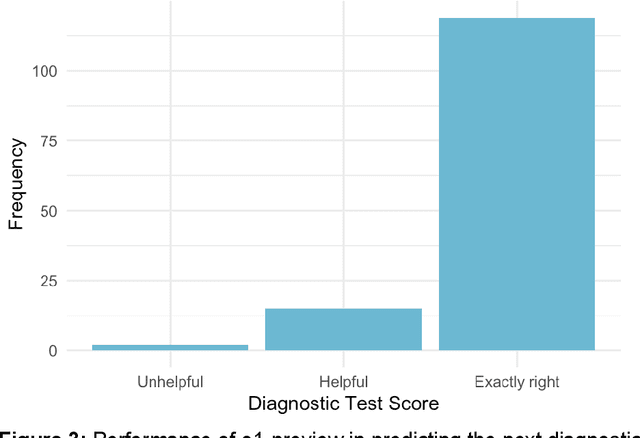
Performance of large language models (LLMs) on medical tasks has traditionally been evaluated using multiple choice question benchmarks. However, such benchmarks are highly constrained, saturated with repeated impressive performance by LLMs, and have an unclear relationship to performance in real clinical scenarios. Clinical reasoning, the process by which physicians employ critical thinking to gather and synthesize clinical data to diagnose and manage medical problems, remains an attractive benchmark for model performance. Prior LLMs have shown promise in outperforming clinicians in routine and complex diagnostic scenarios. We sought to evaluate OpenAI's o1-preview model, a model developed to increase run-time via chain of thought processes prior to generating a response. We characterize the performance of o1-preview with five experiments including differential diagnosis generation, display of diagnostic reasoning, triage differential diagnosis, probabilistic reasoning, and management reasoning, adjudicated by physician experts with validated psychometrics. Our primary outcome was comparison of the o1-preview output to identical prior experiments that have historical human controls and benchmarks of previous LLMs. Significant improvements were observed with differential diagnosis generation and quality of diagnostic and management reasoning. No improvements were observed with probabilistic reasoning or triage differential diagnosis. This study highlights o1-preview's ability to perform strongly on tasks that require complex critical thinking such as diagnosis and management while its performance on probabilistic reasoning tasks was similar to past models. New robust benchmarks and scalable evaluation of LLM capabilities compared to human physicians are needed along with trials evaluating AI in real clinical settings.
Reasoning and Tools for Human-Level Forecasting
Aug 21, 2024



Language models (LMs) trained on web-scale datasets are largely successful due to their ability to memorize large amounts of training data, even if only present in a few examples. These capabilities are often desirable in evaluation on tasks such as question answering but raise questions about whether these models can exhibit genuine reasoning or succeed only at mimicking patterns from the training data. This distinction is particularly salient in forecasting tasks, where the answer is not present in the training data, and the model must reason to make logical deductions. We present Reasoning and Tools for Forecasting (RTF), a framework of reasoning-and-acting (ReAct) agents that can dynamically retrieve updated information and run numerical simulation with equipped tools. We evaluate our model with questions from competitive forecasting platforms and demonstrate that our method is competitive with and can outperform human predictions. This suggests that LMs, with the right tools, can indeed think and adapt like humans, offering valuable insights for real-world decision-making.
Standing on FURM ground -- A framework for evaluating Fair, Useful, and Reliable AI Models in healthcare systems
Mar 14, 2024



The impact of using artificial intelligence (AI) to guide patient care or operational processes is an interplay of the AI model's output, the decision-making protocol based on that output, and the capacity of the stakeholders involved to take the necessary subsequent action. Estimating the effects of this interplay before deployment, and studying it in real time afterwards, are essential to bridge the chasm between AI model development and achievable benefit. To accomplish this, the Data Science team at Stanford Health Care has developed a Testing and Evaluation (T&E) mechanism to identify fair, useful and reliable AI models (FURM) by conducting an ethical review to identify potential value mismatches, simulations to estimate usefulness, financial projections to assess sustainability, as well as analyses to determine IT feasibility, design a deployment strategy, and recommend a prospective monitoring and evaluation plan. We report on FURM assessments done to evaluate six AI guided solutions for potential adoption, spanning clinical and operational settings, each with the potential to impact from several dozen to tens of thousands of patients each year. We describe the assessment process, summarize the six assessments, and share our framework to enable others to conduct similar assessments. Of the six solutions we assessed, two have moved into a planning and implementation phase. Our novel contributions - usefulness estimates by simulation, financial projections to quantify sustainability, and a process to do ethical assessments - as well as their underlying methods and open source tools, are available for other healthcare systems to conduct actionable evaluations of candidate AI solutions.
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
Aug 17, 2023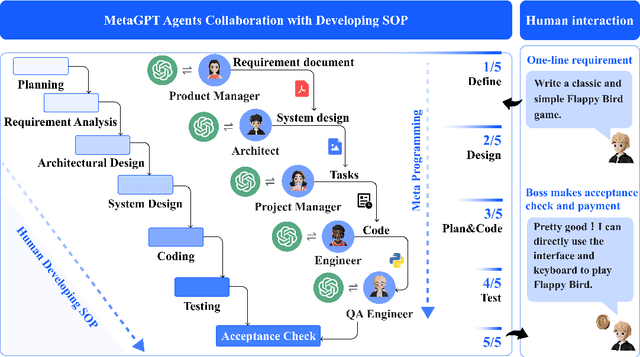
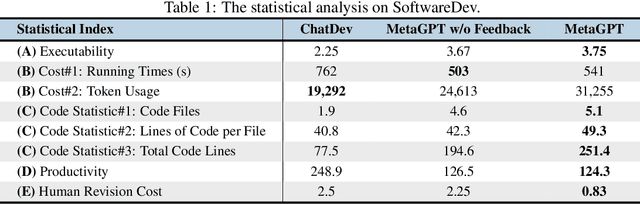
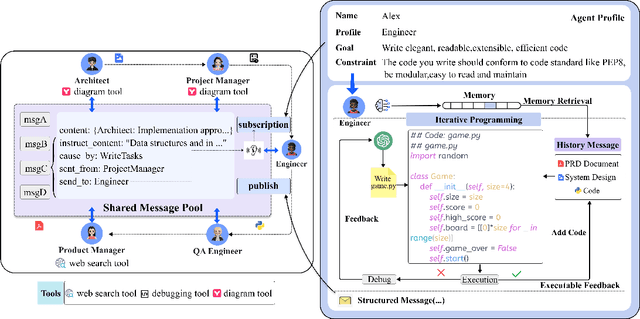
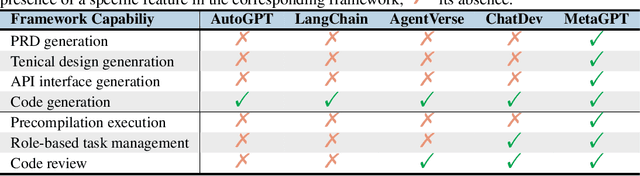
Recently, remarkable progress has been made in automated task-solving through the use of multi-agent driven by large language models (LLMs). However, existing LLM-based multi-agent works primarily focus on solving simple dialogue tasks, and complex tasks are rarely studied, mainly due to the LLM hallucination problem. This type of hallucination becomes cascading when naively chaining multiple intelligent agents, resulting in a failure to effectively address complex problems. Therefore, we introduce MetaGPT, an innovative framework that incorporates efficient human workflows as a meta programming approach into LLM-based multi-agent collaboration. Specifically, MetaGPT encodes Standardized Operating Procedures (SOPs) into prompts to enhance structured coordination. Subsequently, it mandates modular outputs, empowering agents with domain expertise comparable to human professionals, to validate outputs and minimize compounded errors. In this way, MetaGPT leverages the assembly line paradigm to assign diverse roles to various agents, thereby establishing a framework that can effectively and cohesively deconstruct complex multi-agent collaborative problems. Our experiments on collaborative software engineering benchmarks demonstrate that MetaGPT generates more coherent and correct solutions compared to existing chat-based multi-agent systems. This highlights the potential of integrating human domain knowledge into multi-agent systems, thereby creating new opportunities to tackle complex real-world challenges. The GitHub repository of this project is publicly available on:https://github.com/geekan/MetaGPT.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
Explainable PCGML via Game Design Patterns
Sep 25, 2018
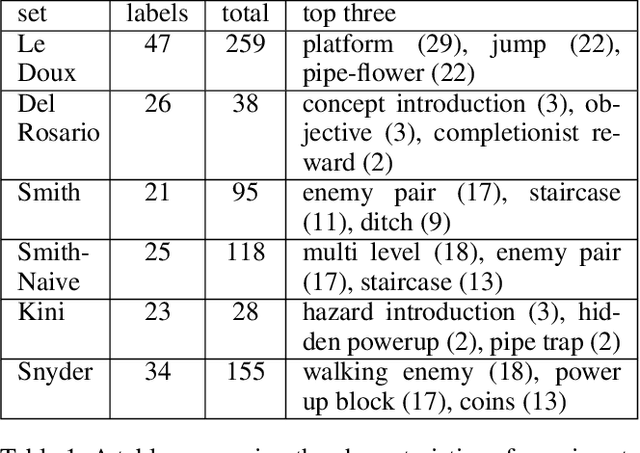
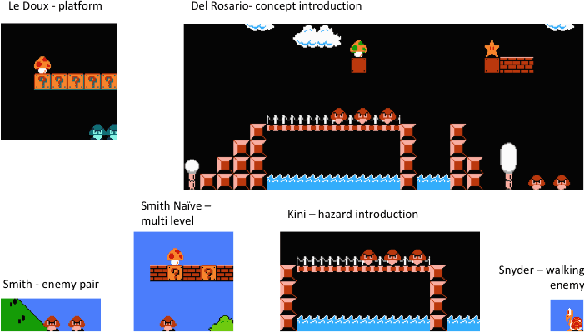
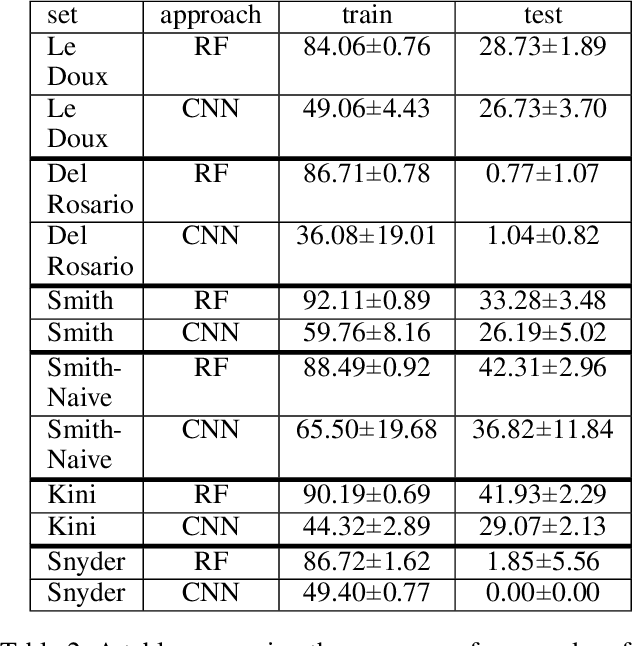
Procedural content generation via Machine Learning (PCGML) is the umbrella term for approaches that generate content for games via machine learning. One of the benefits of PCGML is that, unlike search or grammar-based PCG, it does not require hand authoring of initial content or rules. Instead, PCGML relies on existing content and black box models, which can be difficult to tune or tweak without expert knowledge. This is especially problematic when a human designer needs to understand how to manipulate their data or models to achieve desired results. We present an approach to Explainable PCGML via Design Patterns in which the design patterns act as a vocabulary and mode of interaction between user and model. We demonstrate that our technique outperforms non-explainable versions of our system in interactions with five expert designers, four of whom lack any machine learning expertise.