 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisJudge-Bench: Aesthetics and Quality Assessment of Visualizations
Oct 25, 2025Visualization, a domain-specific yet widely used form of imagery, is an effective way to turn complex datasets into intuitive insights, and its value depends on whether data are faithfully represented, clearly communicated, and aesthetically designed. However, evaluating visualization quality is challenging: unlike natural images, it requires simultaneous judgment across data encoding accuracy, information expressiveness, and visual aesthetics. Although multimodal large language models (MLLMs) have shown promising performance in aesthetic assessment of natural images, no systematic benchmark exists for measuring their capabilities in evaluating visualizations. To address this, we propose VisJudge-Bench, the first comprehensive benchmark for evaluating MLLMs' performance in assessing visualization aesthetics and quality. It contains 3,090 expert-annotated samples from real-world scenarios, covering single visualizations, multiple visualizations, and dashboards across 32 chart types. Systematic testing on this benchmark reveals that even the most advanced MLLMs (such as GPT-5) still exhibit significant gaps compared to human experts in judgment, with a Mean Absolute Error (MAE) of 0.551 and a correlation with human ratings of only 0.429. To address this issue, we propose VisJudge, a model specifically designed for visualization aesthetics and quality assessment. Experimental results demonstrate that VisJudge significantly narrows the gap with human judgment, reducing the MAE to 0.442 (a 19.8% reduction) and increasing the consistency with human experts to 0.681 (a 58.7% improvement) compared to GPT-5. The benchmark is available at https://github.com/HKUSTDial/VisJudgeBench.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
FACT: Examining the Effectiveness of Iterative Context Rewriting for Multi-fact Retrieval
Oct 28, 2024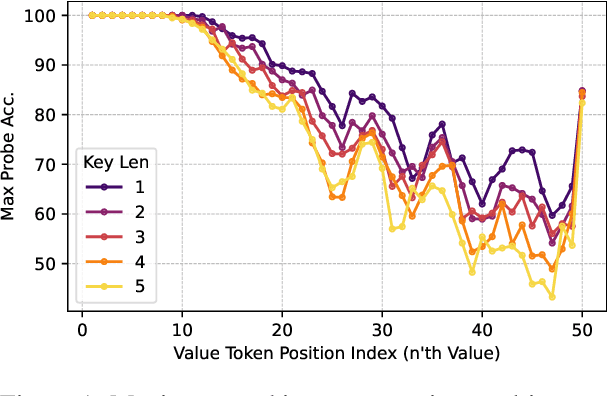
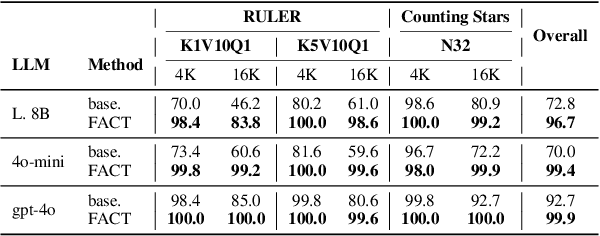
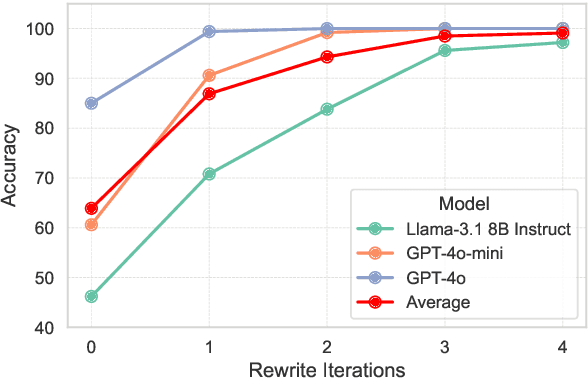
Large Language Models (LLMs) are proficient at retrieving single facts from extended contexts, yet they struggle with tasks requiring the simultaneous retrieval of multiple facts, especially during generation. This paper identifies a novel "lost-in-the-middle" phenomenon, where LLMs progressively lose track of critical information throughout the generation process, resulting in incomplete or inaccurate retrieval. To address this challenge, we introduce Find All Crucial Texts (FACT), an iterative retrieval method that refines context through successive rounds of rewriting. This approach enables models to capture essential facts incrementally, which are often overlooked in single-pass retrieval. Experiments demonstrate that FACT substantially enhances multi-fact retrieval performance across various tasks, though improvements are less notable in general-purpose QA scenarios. Our findings shed light on the limitations of LLMs in multi-fact retrieval and underscore the need for more resilient long-context retrieval strategies.
AFlow: Automating Agentic Workflow Generation
Oct 14, 2024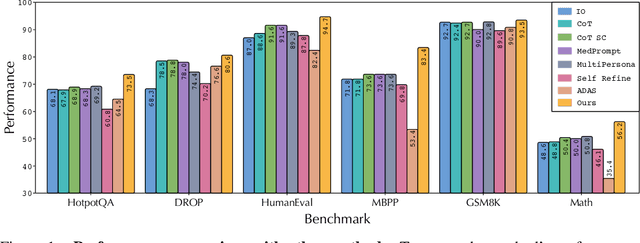

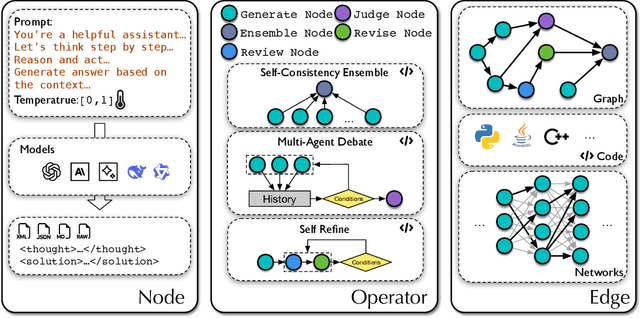
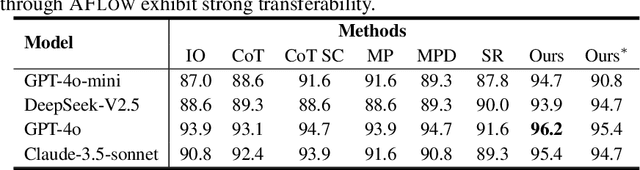
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at https://github.com/geekan/MetaGPT.
Data Interpreter: An LLM Agent For Data Science
Mar 12, 2024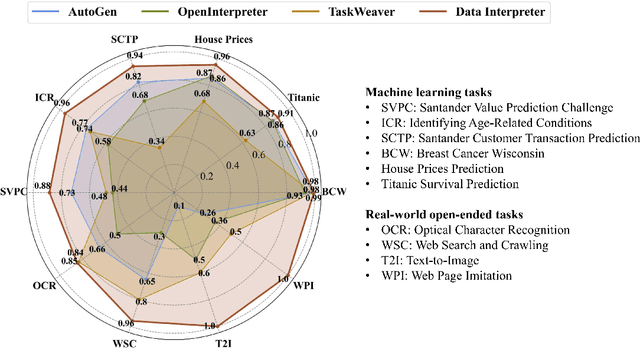
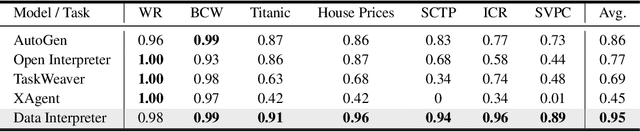
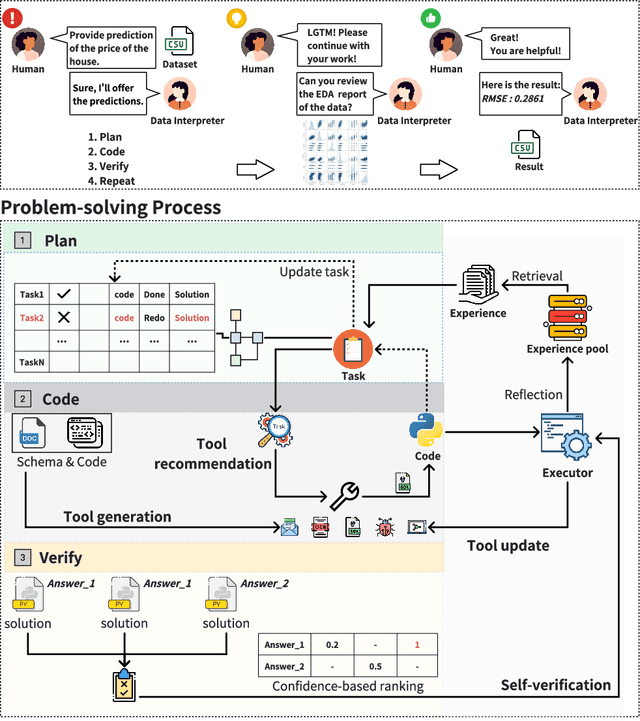

Large Language Model (LLM)-based agents have demonstrated remarkable effectiveness. However, their performance can be compromised in data science scenarios that require real-time data adjustment, expertise in optimization due to complex dependencies among various tasks, and the ability to identify logical errors for precise reasoning. In this study, we introduce the Data Interpreter, a solution designed to solve with code that emphasizes three pivotal techniques to augment problem-solving in data science: 1) dynamic planning with hierarchical graph structures for real-time data adaptability;2) tool integration dynamically to enhance code proficiency during execution, enriching the requisite expertise;3) logical inconsistency identification in feedback, and efficiency enhancement through experience recording. We evaluate the Data Interpreter on various data science and real-world tasks. Compared to open-source baselines, it demonstrated superior performance, exhibiting significant improvements in machine learning tasks, increasing from 0.86 to 0.95. Additionally, it showed a 26% increase in the MATH dataset and a remarkable 112% improvement in open-ended tasks. The solution will be released at https://github.com/geekan/MetaGPT.
MetaGPT: Meta Programming for Multi-Agent Collaborative Framework
Aug 17, 2023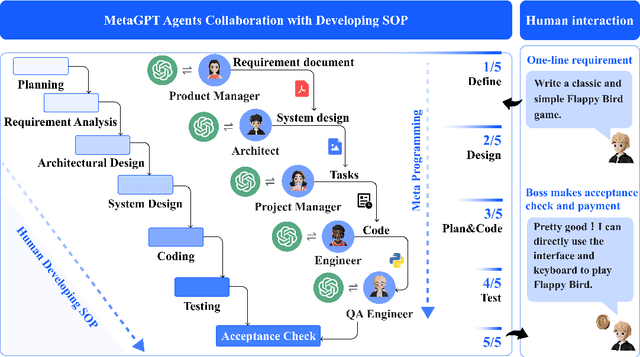
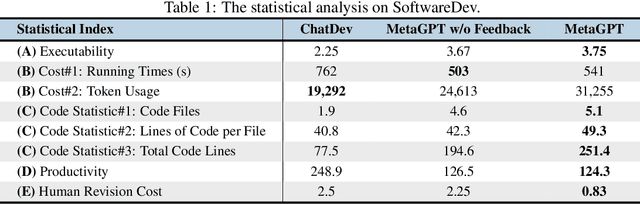
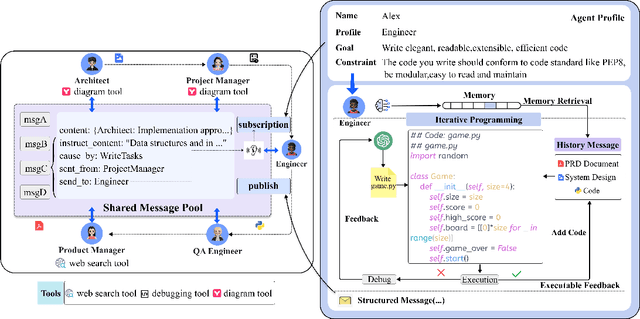
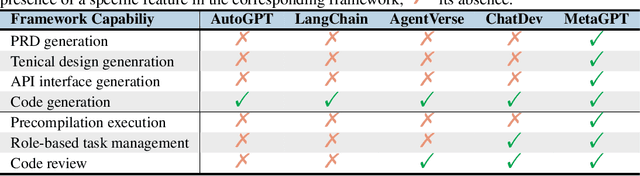
Recently, remarkable progress has been made in automated task-solving through the use of multi-agent driven by large language models (LLMs). However, existing LLM-based multi-agent works primarily focus on solving simple dialogue tasks, and complex tasks are rarely studied, mainly due to the LLM hallucination problem. This type of hallucination becomes cascading when naively chaining multiple intelligent agents, resulting in a failure to effectively address complex problems. Therefore, we introduce MetaGPT, an innovative framework that incorporates efficient human workflows as a meta programming approach into LLM-based multi-agent collaboration. Specifically, MetaGPT encodes Standardized Operating Procedures (SOPs) into prompts to enhance structured coordination. Subsequently, it mandates modular outputs, empowering agents with domain expertise comparable to human professionals, to validate outputs and minimize compounded errors. In this way, MetaGPT leverages the assembly line paradigm to assign diverse roles to various agents, thereby establishing a framework that can effectively and cohesively deconstruct complex multi-agent collaborative problems. Our experiments on collaborative software engineering benchmarks demonstrate that MetaGPT generates more coherent and correct solutions compared to existing chat-based multi-agent systems. This highlights the potential of integrating human domain knowledge into multi-agent systems, thereby creating new opportunities to tackle complex real-world challenges. The GitHub repository of this project is publicly available on:https://github.com/geekan/MetaGPT.