 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Environments Drive Generalizable Agents
May 18, 2026Generalizable agents should adapt to diverse tasks and unseen environments beyond their training distribution. This position paper argues that such generalization requires environment scaling: expanding the distribution of executable rule-sets that agents interact with, rather than only increasing trajectories or tasks within fixed benchmarks. Current scaling practices largely focus on collecting more experience or broader task sets under fixed interaction rules, leaving agents brittle when underlying interfaces, dynamics, observations, or feedback signals change. The core challenge is therefore a world-level distribution shift: agents need systematic exposure to environments with meaningfully different executable rule-sets. To clarify this challenge, we propose a unified taxonomy that separates trajectory scaling, task scaling, and environment scaling by their primary deliverables and by what changes in the executable rule-set. Building on this taxonomy, we synthesize construction paradigms for scalable environments, contrasting programmatic generators that prioritize controllability and verifiability with generative world models that offer broader coverage and open-endedness. We further outline how environment scaling can be coupled with stateful learning mechanisms, emphasizing learned update rules for cross-environment adaptation. We conclude by discussing alternative perspectives and argue that scalable environments provide the essential substrate for measurable and controllable progress toward robust general agents.
Harnessing Agentic Evolution
May 13, 2026Agentic evolution has emerged as a powerful paradigm for improving programs, workflows, and scientific solutions by iteratively generating candidates, evaluating them, and using feedback to guide future search. However, existing methods are typically instantiated either as fixed hand-designed procedures that are modular but rigid, or as general-purpose agents that flexibly integrate feedback but can drift in long-horizon evolution. Both forms accumulate rich evidence over time, including candidates, feedback, traces, and failures, yet lack a stable interface for organizing this evidence and revising the mechanism that drives future evolution. We address this limitation by formulating agentic evolution as an interactive environment, where the accumulated evolution context serves as a process-level state. We introduce AEvo, a harnessed meta-editing framework in which a meta-agent observes this state and acts not by directly proposing the next candidate, but by editing the procedure or agent context that controls future evolution. This unified interface enables AEvo to steer both procedure-based and agent-based evolution, making accumulated evidence actionable for long-horizon search. Empirical evaluations on agentic and reasoning benchmarks show that AEvo outperforms five evolution baselines, achieving a 26 relative improvement over the strongest baseline. Across three open-ended optimization tasks, AEvo further outperforms four evolution baselines and achieves state-of-the-art performance under the same iteration budget.
AOrchestra: Automating Sub-Agent Creation for Agentic Orchestration
Feb 03, 2026Language agents have shown strong promise for task automation. Realizing this promise for increasingly complex, long-horizon tasks has driven the rise of a sub-agent-as-tools paradigm for multi-turn task solving. However, existing designs still lack a dynamic abstraction view of sub-agents, thereby hurting adaptability. We address this challenge with a unified, framework-agnostic agent abstraction that models any agent as a tuple Instruction, Context, Tools, Model. This tuple acts as a compositional recipe for capabilities, enabling the system to spawn specialized executors for each task on demand. Building on this abstraction, we introduce an agentic system AOrchestra, where the central orchestrator concretizes the tuple at each step: it curates task-relevant context, selects tools and models, and delegates execution via on-the-fly automatic agent creation. Such designs enable reducing human engineering efforts, and remain framework-agnostic with plug-and-play support for diverse agents as task executors. It also enables a controllable performance-cost trade-off, allowing the system to approach Pareto-efficient. Across three challenging benchmarks (GAIA, SWE-Bench, Terminal-Bench), AOrchestra achieves 16.28% relative improvement against the strongest baseline when paired with Gemini-3-Flash. The code is available at: https://github.com/FoundationAgents/AOrchestra
A Survey of Self-Evolving Agents: On Path to Artificial Super Intelligence
Jul 28, 2025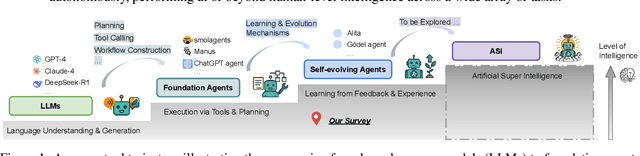

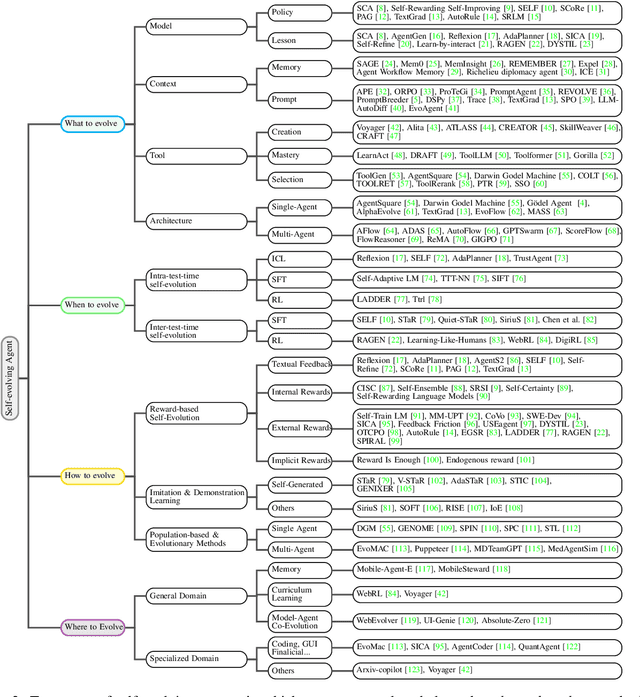
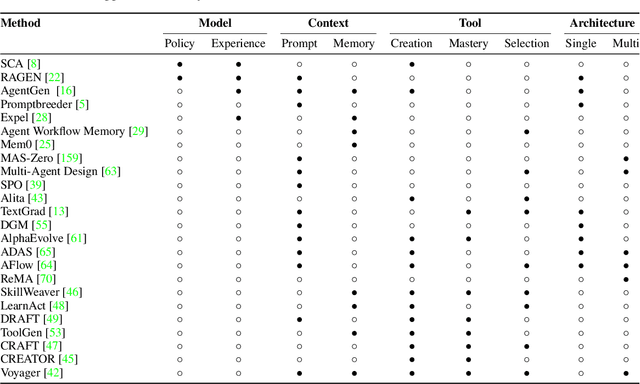
Large Language Models (LLMs) have demonstrated strong capabilities but remain fundamentally static, unable to adapt their internal parameters to novel tasks, evolving knowledge domains, or dynamic interaction contexts. As LLMs are increasingly deployed in open-ended, interactive environments, this static nature has become a critical bottleneck, necessitating agents that can adaptively reason, act, and evolve in real time. This paradigm shift -- from scaling static models to developing self-evolving agents -- has sparked growing interest in architectures and methods enabling continual learning and adaptation from data, interactions, and experiences. This survey provides the first systematic and comprehensive review of self-evolving agents, organized around three foundational dimensions -- what to evolve, when to evolve, and how to evolve. We examine evolutionary mechanisms across agent components (e.g., models, memory, tools, architecture), categorize adaptation methods by stages (e.g., intra-test-time, inter-test-time), and analyze the algorithmic and architectural designs that guide evolutionary adaptation (e.g., scalar rewards, textual feedback, single-agent and multi-agent systems). Additionally, we analyze evaluation metrics and benchmarks tailored for self-evolving agents, highlight applications in domains such as coding, education, and healthcare, and identify critical challenges and research directions in safety, scalability, and co-evolutionary dynamics. By providing a structured framework for understanding and designing self-evolving agents, this survey establishes a roadmap for advancing adaptive agentic systems in both research and real-world deployments, ultimately shedding lights to pave the way for the realization of Artificial Super Intelligence (ASI), where agents evolve autonomously, performing at or beyond human-level intelligence across a wide array of tasks.
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Mar 10, 2025



Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
Self-Supervised Prompt Optimization
Feb 07, 2025



Well-designed prompts are crucial for enhancing Large language models' (LLMs) reasoning capabilities while aligning their outputs with task requirements across diverse domains. However, manually designed prompts require expertise and iterative experimentation. While existing prompt optimization methods aim to automate this process, they rely heavily on external references such as ground truth or by humans, limiting their applicability in real-world scenarios where such data is unavailable or costly to obtain. To address this, we propose Self-Supervised Prompt Optimization (SPO), a cost-efficient framework that discovers effective prompts for both closed and open-ended tasks without requiring external reference. Motivated by the observations that prompt quality manifests directly in LLM outputs and LLMs can effectively assess adherence to task requirements, we derive evaluation and optimization signals purely from output comparisons. Specifically, SPO selects superior prompts through pairwise output comparisons evaluated by an LLM evaluator, followed by an LLM optimizer that aligns outputs with task requirements. Extensive experiments demonstrate that SPO outperforms state-of-the-art prompt optimization methods, achieving comparable or superior results with significantly lower costs (e.g., 1.1% to 5.6% of existing methods) and fewer samples (e.g., three samples). The code is available at https://github.com/geekan/MetaGPT.
AFlow: Automating Agentic Workflow Generation
Oct 14, 2024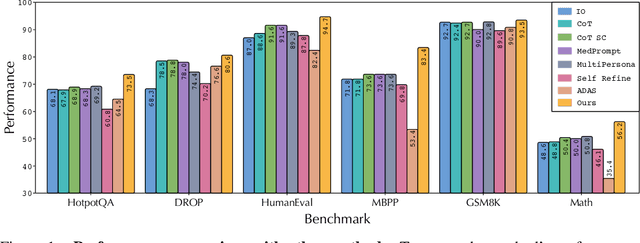

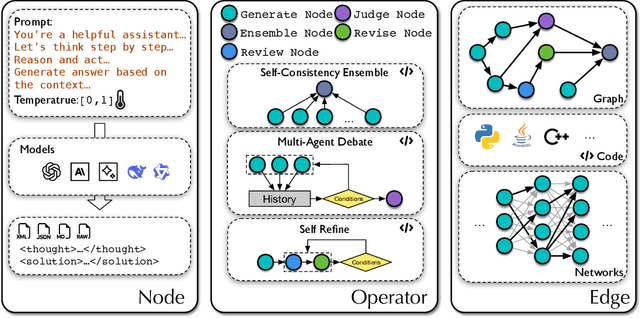
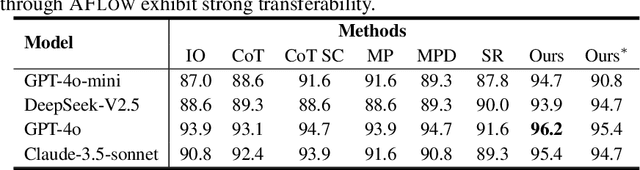
Large language models (LLMs) have demonstrated remarkable potential in solving complex tasks across diverse domains, typically by employing agentic workflows that follow detailed instructions and operational sequences. However, constructing these workflows requires significant human effort, limiting scalability and generalizability. Recent research has sought to automate the generation and optimization of these workflows, but existing methods still rely on initial manual setup and fall short of achieving fully automated and effective workflow generation. To address this challenge, we reformulate workflow optimization as a search problem over code-represented workflows, where LLM-invoking nodes are connected by edges. We introduce AFlow, an automated framework that efficiently explores this space using Monte Carlo Tree Search, iteratively refining workflows through code modification, tree-structured experience, and execution feedback. Empirical evaluations across six benchmark datasets demonstrate AFlow's efficacy, yielding a 5.7% average improvement over state-of-the-art baselines. Furthermore, AFlow enables smaller models to outperform GPT-4o on specific tasks at 4.55% of its inference cost in dollars. The code will be available at https://github.com/geekan/MetaGPT.