 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent KB: Leveraging Cross-Domain Experience for Agentic Problem Solving
Jul 08, 2025As language agents tackle increasingly complex tasks, they struggle with effective error correction and experience reuse across domains. We introduce Agent KB, a hierarchical experience framework that enables complex agentic problem solving via a novel Reason-Retrieve-Refine pipeline. Agent KB addresses a core limitation: agents traditionally cannot learn from each other's experiences. By capturing both high-level strategies and detailed execution logs, Agent KB creates a shared knowledge base that enables cross-agent knowledge transfer. Evaluated on the GAIA benchmark, Agent KB improves success rates by up to 16.28 percentage points. On the most challenging tasks, Claude-3 improves from 38.46% to 57.69%, while GPT-4 improves from 53.49% to 73.26% on intermediate tasks. On SWE-bench code repair, Agent KB enables Claude-3 to improve from 41.33% to 53.33%. Our results suggest that Agent KB provides a modular, framework-agnostic infrastructure for enabling agents to learn from past experiences and generalize successful strategies to new tasks.
Do Multiple Instance Learning Models Transfer?
Jun 11, 2025Multiple Instance Learning (MIL) is a cornerstone approach in computational pathology (CPath) for generating clinically meaningful slide-level embeddings from gigapixel tissue images. However, MIL often struggles with small, weakly supervised clinical datasets. In contrast to fields such as NLP and conventional computer vision, where transfer learning is widely used to address data scarcity, the transferability of MIL models remains poorly understood. In this study, we systematically evaluate the transfer learning capabilities of pretrained MIL models by assessing 11 models across 21 pretraining tasks for morphological and molecular subtype prediction. Our results show that pretrained MIL models, even when trained on different organs than the target task, consistently outperform models trained from scratch. Moreover, pretraining on pancancer datasets enables strong generalization across organs and tasks, outperforming slide foundation models while using substantially less pretraining data. These findings highlight the robust adaptability of MIL models and demonstrate the benefits of leveraging transfer learning to boost performance in CPath. Lastly, we provide a resource which standardizes the implementation of MIL models and collection of pretrained model weights on popular CPath tasks, available at https://github.com/mahmoodlab/MIL-Lab
MedAgentsBench: Benchmarking Thinking Models and Agent Frameworks for Complex Medical Reasoning
Mar 10, 2025



Large Language Models (LLMs) have shown impressive performance on existing medical question-answering benchmarks. This high performance makes it increasingly difficult to meaningfully evaluate and differentiate advanced methods. We present MedAgentsBench, a benchmark that focuses on challenging medical questions requiring multi-step clinical reasoning, diagnosis formulation, and treatment planning-scenarios where current models still struggle despite their strong performance on standard tests. Drawing from seven established medical datasets, our benchmark addresses three key limitations in existing evaluations: (1) the prevalence of straightforward questions where even base models achieve high performance, (2) inconsistent sampling and evaluation protocols across studies, and (3) lack of systematic analysis of the interplay between performance, cost, and inference time. Through experiments with various base models and reasoning methods, we demonstrate that the latest thinking models, DeepSeek R1 and OpenAI o3, exhibit exceptional performance in complex medical reasoning tasks. Additionally, advanced search-based agent methods offer promising performance-to-cost ratios compared to traditional approaches. Our analysis reveals substantial performance gaps between model families on complex questions and identifies optimal model selections for different computational constraints. Our benchmark and evaluation framework are publicly available at https://github.com/gersteinlab/medagents-benchmark.
A General-Purpose Self-Supervised Model for Computational Pathology
Aug 29, 2023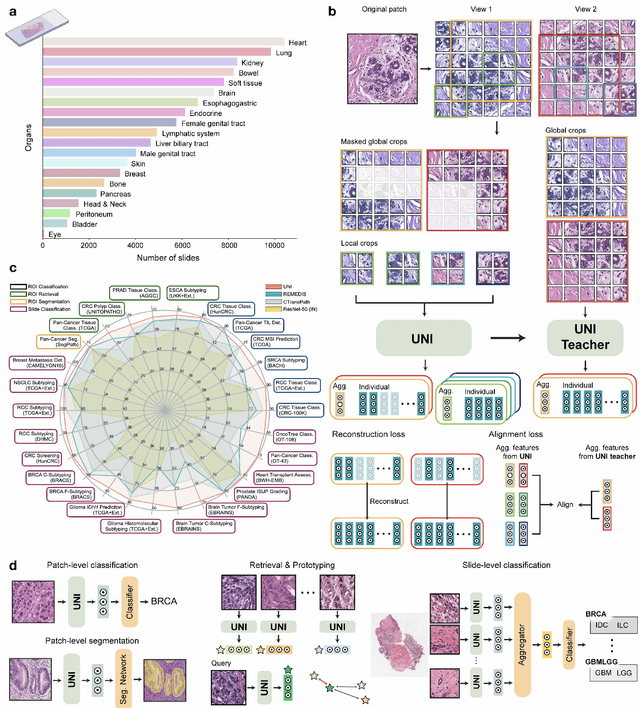

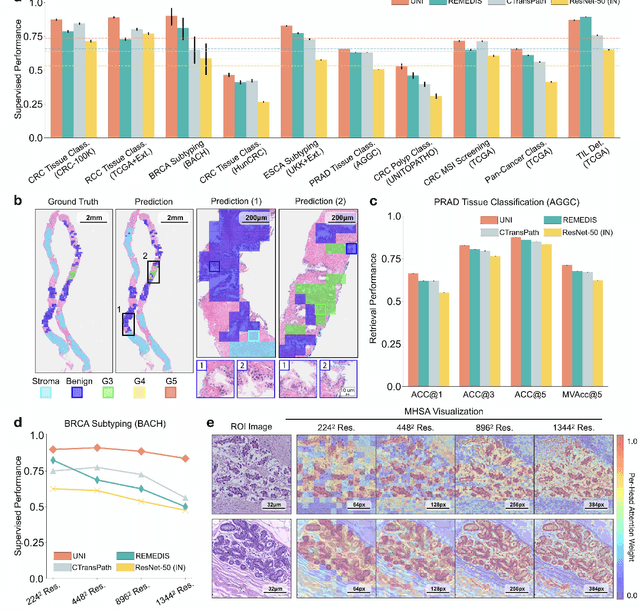

Tissue phenotyping is a fundamental computational pathology (CPath) task in learning objective characterizations of histopathologic biomarkers in anatomic pathology. However, whole-slide imaging (WSI) poses a complex computer vision problem in which the large-scale image resolutions of WSIs and the enormous diversity of morphological phenotypes preclude large-scale data annotation. Current efforts have proposed using pretrained image encoders with either transfer learning from natural image datasets or self-supervised pretraining on publicly-available histopathology datasets, but have not been extensively developed and evaluated across diverse tissue types at scale. We introduce UNI, a general-purpose self-supervised model for pathology, pretrained using over 100 million tissue patches from over 100,000 diagnostic haematoxylin and eosin-stained WSIs across 20 major tissue types, and evaluated on 33 representative CPath clinical tasks in CPath of varying diagnostic difficulties. In addition to outperforming previous state-of-the-art models, we demonstrate new modeling capabilities in CPath such as resolution-agnostic tissue classification, slide classification using few-shot class prototypes, and disease subtyping generalization in classifying up to 108 cancer types in the OncoTree code classification system. UNI advances unsupervised representation learning at scale in CPath in terms of both pretraining data and downstream evaluation, enabling data-efficient AI models that can generalize and transfer to a gamut of diagnostically-challenging tasks and clinical workflows in anatomic pathology.