 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Immune Biomarkers with MultiModal Mixture-of-Expert Pathology Foundation Models Empowers Precision Oncology
Jun 16, 2026Predicting immune biomarkers associated with the tumor immune microenvironment (TIME) is critical for advancing precision oncology, yet existing approaches are largely limited to single image modalities and suffer from insufficient resolution and incomplete utilization of complementary clinical and biological information. Here we introduce MixTIME, a multimodal foundation model that leverages a mixture-of-experts (MoE) architecture to integrate pathology foundation models trained across distinct modalities: image only (UNIv2), image text (CONCHv1.5), and image transcriptomic (STPath) representations for pixel-level and slide-level prediction of multiplex immunofluorescence (mIF) protein expression from hematoxylin and eosin (HE) whole-slide images. MixTIME employs a learnable router to dynamically weight expert contributions and is trained with a distribution- and tendency-aware loss function. Benchmarked on two datasets of different scales, MixTIME achieves state-of-the-art performance across 17 protein markers as measured by correlation metrics. The predicted mIF profiles substantially enhance downstream tasks, including spatial domain identification, survival prediction, and AI-assisted pathology report generation validated by expert pathologists from multiple institutes across the world. Furthermore, MixTIME enables longitudinal tracking of protein expression dynamics across clinical time points and reveals protein gene interaction patterns linked to drug resistance and immune suppression in tumor microenvironments. Collectively, MixTIME provides a scalable framework for multimodal biomarker discovery and clinical translation in computational pathology.
BrainAnytime: Anatomy-Aware Cross-Modal Pretraining for Brain Image Analysis with Arbitrary Modality Availability
May 13, 2026Clinical diagnostic workups typically follow a modality escalation pathway: after initial clinical evaluation, clinicians begin with routine structural imaging (e.g., MRI), selectively add sequences such as FLAIR or T2 to refine the differential, and reserve molecular imaging (e.g., amyloid-PET) for cases that remain uncertain after standard evaluation. Consequently, patients are observed with heterogeneous and often incomplete modality subsets. However, most current AI models assume fixed data modalities as the model inputs. In this paper, we present BrainAnytime, a unified pretraining framework pretrained on 34,899 3D brain scans from five datasets that support brain image analysis under arbitrary modality availability spanning multi-sequence MRI and amyloid-PET. A single model accepts whatever imaging is available, from a lone T1 scan to a full multimodal workup. Pretraining learns structural-molecular correspondences between MRI and PET via cross-modal distillation (RCMD) and prioritizes disease-vulnerable anatomy via atlas-guided curriculum masking (PACM), all within a shared 3D masked autoencoder (Multi-MAE3D). Across four downstream tasks and five clinically motivated modality settings, BrainAnytime largely outperforms modality-specific models, missing-modality baselines, and large-scale brain MRI pretrained foundation models on most modality settings. Notably, it surpasses the strongest missing-modality baselines with relative improvements of 6.2% and 7.0% in average accuracy on CN vs. AD and CN vs. MCI classification, respectively. Code is available at https://github.com/SDH-Lab/BrainAnytime.
A multimodal and temporal foundation model for virtual patient representations at healthcare system scale
Apr 21, 2026Modern medicine generates vast multimodal data across siloed systems, yet no existing model integrates the full breadth and temporal depth of the clinical record into a unified patient representation. We introduce Apollo, a multimodal temporal foundation model trained and evaluated on over three decades of longitudinal hospital records from a major US hospital system, composed of 25 billion records from 7.2 million patients, representing 28 distinct medical modalities and 12 major medical specialties. Apollo learns a unified representation space integrating over 100 thousand unique medical events in our clinical vocabulary as well as images and clinical text. This "atlas of medical concepts" forms a computational substrate for modeling entire patient care journeys comprised of sequences of structured and unstructured events, which are compressed by Apollo into virtual patient representations. To assess the potential of these whole-patient representations, we created 322 prognosis and retrieval tasks from a held-out test set of 1.4 million patients. We demonstrate the generalized clinical forecasting potential of Apollo embeddings, including predicting new disease onset risk up to five years in advance (95 tasks), disease progression (78 tasks), treatment response (59 tasks), risk of treatment-related adverse events (17 tasks), and hospital operations endpoints (12 tasks). Using feature attribution techniques, we show that model predictions align with clinically-interpretable multimodal biomarkers. We evaluate semantic similarity search on 61 retrieval tasks, and moreover demonstrate the potential of Apollo as a multimodal medical search engine using text and image queries. Together, these modeling capabilities establish the foundation for computable medicine, where the full context of patient care becomes accessible to computational reasoning.
Parameter estimation of range-migrating targets using OTFS signals from LEO satellites
Jul 03, 2025This study investigates a communication-centric integrated sensing and communication (ISAC) system that utilizes orthogonal time frequency space (OTFS) modulated signals emitted by low Earth orbit (LEO) satellites to estimate the parameters of space targets experiencing range migration, henceforth referred to as high-speed targets. Leveraging the specific signal processing performed by OTFS transceivers, we derive a novel input-output model for the echo generated by a high-speed target in scenarios where ideal and rectangular shaping filters are employed. Our findings reveal that the target response exhibits a sparse structure in the delay-Doppler domain, dependent solely upon the initial range and range-rate; notably, range migration causes a spread in the target response, marking a significant departure from previous studies. Utilizing this signal structure, we propose an approximate implementation of the maximum likelihood estimator for the target's initial range, range-rate, and amplitude. The estimation process involves obtaining coarse information on the target response using a block orthogonal matching pursuit algorithm, followed by a refinement step using a bank of matched filters focused on a smaller range and range-rate region. Finally, numerical examples are provided to evaluate the estimation performance.
Evidence-based diagnostic reasoning with multi-agent copilot for human pathology
Jun 26, 2025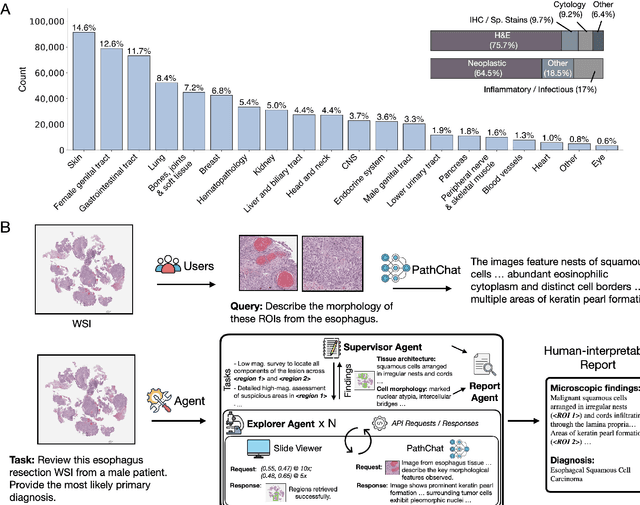
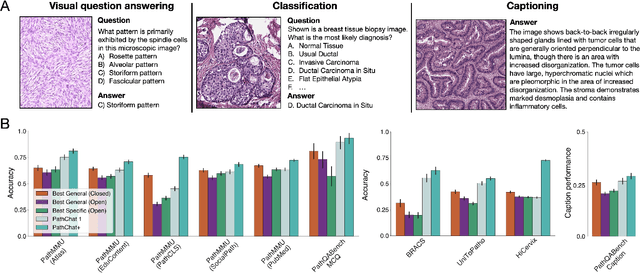
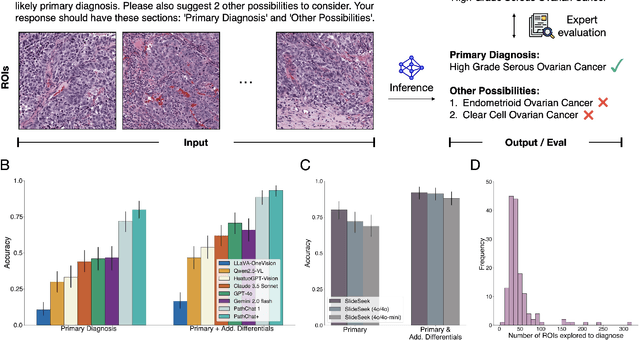
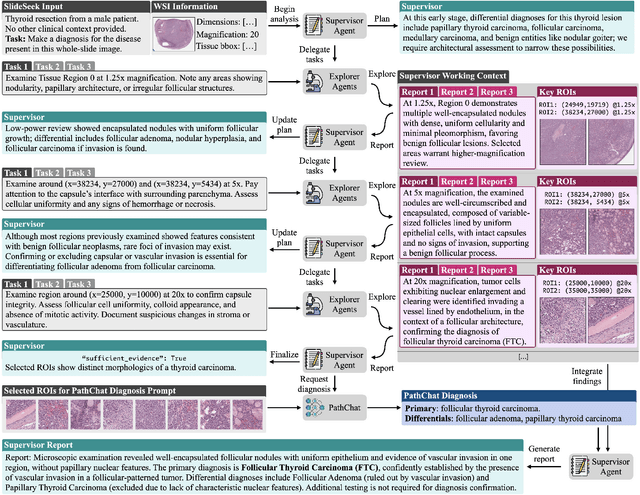
Pathology is experiencing rapid digital transformation driven by whole-slide imaging and artificial intelligence (AI). While deep learning-based computational pathology has achieved notable success, traditional models primarily focus on image analysis without integrating natural language instruction or rich, text-based context. Current multimodal large language models (MLLMs) in computational pathology face limitations, including insufficient training data, inadequate support and evaluation for multi-image understanding, and a lack of autonomous, diagnostic reasoning capabilities. To address these limitations, we introduce PathChat+, a new MLLM specifically designed for human pathology, trained on over 1 million diverse, pathology-specific instruction samples and nearly 5.5 million question answer turns. Extensive evaluations across diverse pathology benchmarks demonstrated that PathChat+ substantially outperforms the prior PathChat copilot, as well as both state-of-the-art (SOTA) general-purpose and other pathology-specific models. Furthermore, we present SlideSeek, a reasoning-enabled multi-agent AI system leveraging PathChat+ to autonomously evaluate gigapixel whole-slide images (WSIs) through iterative, hierarchical diagnostic reasoning, reaching high accuracy on DDxBench, a challenging open-ended differential diagnosis benchmark, while also capable of generating visually grounded, humanly-interpretable summary reports.
Do Multiple Instance Learning Models Transfer?
Jun 11, 2025Multiple Instance Learning (MIL) is a cornerstone approach in computational pathology (CPath) for generating clinically meaningful slide-level embeddings from gigapixel tissue images. However, MIL often struggles with small, weakly supervised clinical datasets. In contrast to fields such as NLP and conventional computer vision, where transfer learning is widely used to address data scarcity, the transferability of MIL models remains poorly understood. In this study, we systematically evaluate the transfer learning capabilities of pretrained MIL models by assessing 11 models across 21 pretraining tasks for morphological and molecular subtype prediction. Our results show that pretrained MIL models, even when trained on different organs than the target task, consistently outperform models trained from scratch. Moreover, pretraining on pancancer datasets enables strong generalization across organs and tasks, outperforming slide foundation models while using substantially less pretraining data. These findings highlight the robust adaptability of MIL models and demonstrate the benefits of leveraging transfer learning to boost performance in CPath. Lastly, we provide a resource which standardizes the implementation of MIL models and collection of pretrained model weights on popular CPath tasks, available at https://github.com/mahmoodlab/MIL-Lab
Accelerating Data Processing and Benchmarking of AI Models for Pathology
Feb 10, 2025Advances in foundation modeling have reshaped computational pathology. However, the increasing number of available models and lack of standardized benchmarks make it increasingly complex to assess their strengths, limitations, and potential for further development. To address these challenges, we introduce a new suite of software tools for whole-slide image processing, foundation model benchmarking, and curated publicly available tasks. We anticipate that these resources will promote transparency, reproducibility, and continued progress in the field.
Molecular-driven Foundation Model for Oncologic Pathology
Jan 28, 2025Foundation models are reshaping computational pathology by enabling transfer learning, where models pre-trained on vast datasets can be adapted for downstream diagnostic, prognostic, and therapeutic response tasks. Despite these advances, foundation models are still limited in their ability to encode the entire gigapixel whole-slide images without additional training and often lack complementary multimodal data. Here, we introduce Threads, a slide-level foundation model capable of generating universal representations of whole-slide images of any size. Threads was pre-trained using a multimodal learning approach on a diverse cohort of 47,171 hematoxylin and eosin (H&E)-stained tissue sections, paired with corresponding genomic and transcriptomic profiles - the largest such paired dataset to be used for foundation model development to date. This unique training paradigm enables Threads to capture the tissue's underlying molecular composition, yielding powerful representations applicable to a wide array of downstream tasks. In extensive benchmarking across 54 oncology tasks, including clinical subtyping, grading, mutation prediction, immunohistochemistry status determination, treatment response prediction, and survival prediction, Threads outperformed all baselines while demonstrating remarkable generalizability and label efficiency. It is particularly well suited for predicting rare events, further emphasizing its clinical utility. We intend to make the model publicly available for the broader community.
Multimodal Whole Slide Foundation Model for Pathology
Nov 29, 2024



The field of computational pathology has been transformed with recent advances in foundation models that encode histopathology region-of-interests (ROIs) into versatile and transferable feature representations via self-supervised learning (SSL). However, translating these advancements to address complex clinical challenges at the patient and slide level remains constrained by limited clinical data in disease-specific cohorts, especially for rare clinical conditions. We propose TITAN, a multimodal whole slide foundation model pretrained using 335,645 WSIs via visual self-supervised learning and vision-language alignment with corresponding pathology reports and 423,122 synthetic captions generated from a multimodal generative AI copilot for pathology. Without any finetuning or requiring clinical labels, TITAN can extract general-purpose slide representations and generate pathology reports that generalize to resource-limited clinical scenarios such as rare disease retrieval and cancer prognosis. We evaluate TITAN on diverse clinical tasks and find that TITAN outperforms both ROI and slide foundation models across machine learning settings such as linear probing, few-shot and zero-shot classification, rare cancer retrieval and cross-modal retrieval, and pathology report generation.
Tree of Attributes Prompt Learning for Vision-Language Models
Oct 15, 2024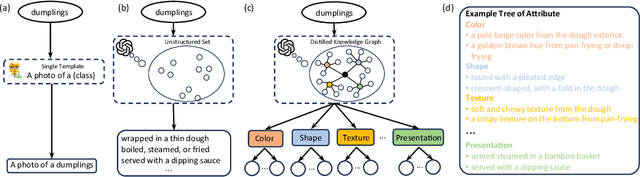
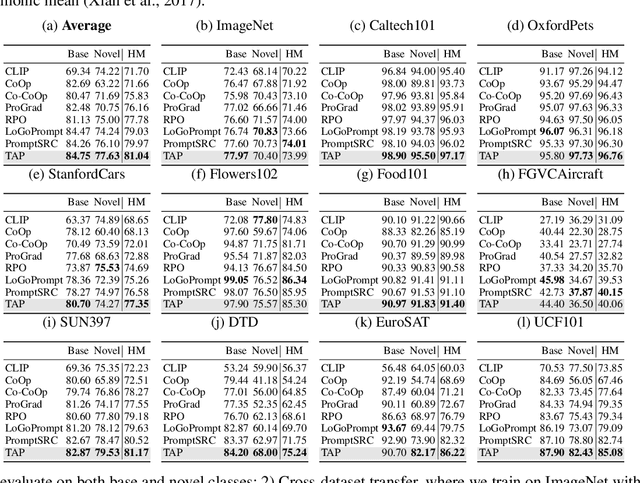
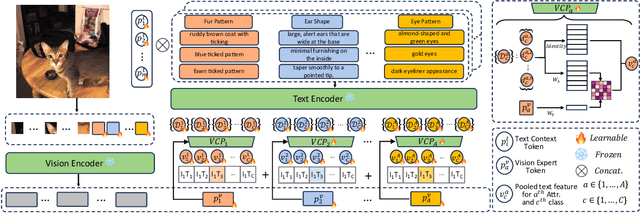
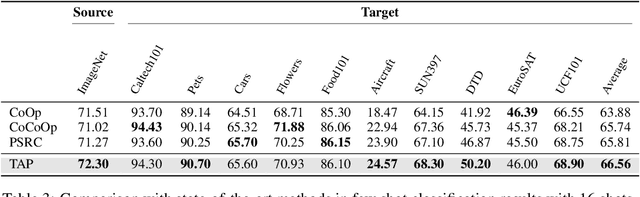
Prompt learning has proven effective in adapting vision language models for downstream tasks. However, existing methods usually append learnable prompt tokens solely with the category names to obtain textual features, which fails to fully leverage the rich context indicated in the category name. To address this issue, we propose the Tree of Attributes Prompt learning (TAP), which first instructs LLMs to generate a tree of attributes with a "concept - attribute - description" structure for each category, and then learn the hierarchy with vision and text prompt tokens. Unlike existing methods that merely augment category names with a set of unstructured descriptions, our approach essentially distills structured knowledge graphs associated with class names from LLMs. Furthermore, our approach introduces text and vision prompts designed to explicitly learn the corresponding visual attributes, effectively serving as domain experts. Additionally, the general and diverse descriptions generated based on the class names may be wrong or absent in the specific given images. To address this misalignment, we further introduce a vision-conditional pooling module to extract instance-specific text features. Extensive experimental results demonstrate that our approach outperforms state-of-the-art methods on the zero-shot base-to-novel generalization, cross-dataset transfer, as well as few-shot classification across 11 diverse datasets.