 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence-based diagnostic reasoning with multi-agent copilot for human pathology
Jun 26, 2025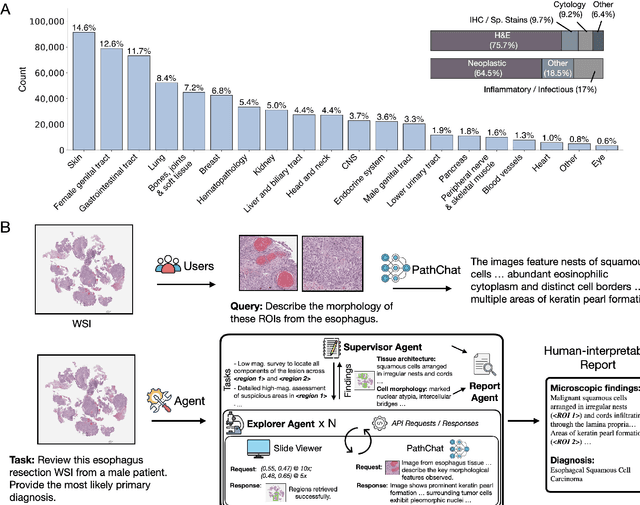
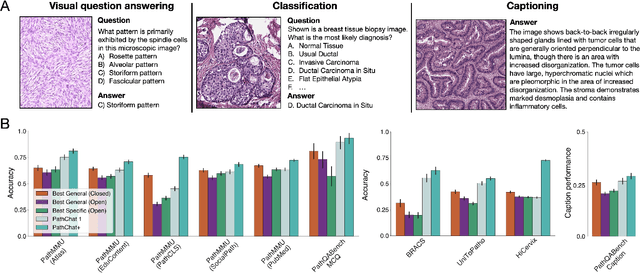
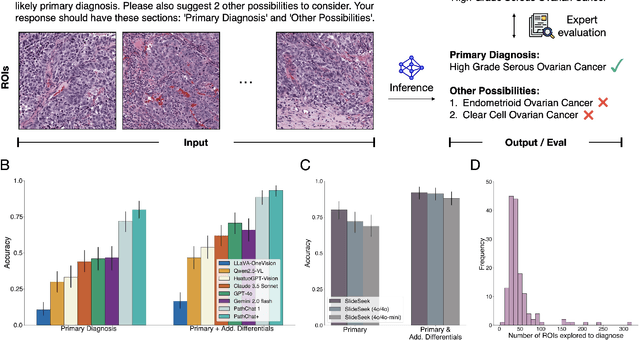
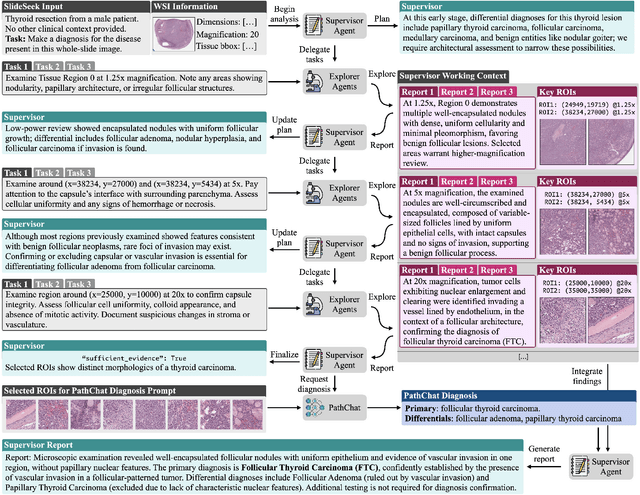
Pathology is experiencing rapid digital transformation driven by whole-slide imaging and artificial intelligence (AI). While deep learning-based computational pathology has achieved notable success, traditional models primarily focus on image analysis without integrating natural language instruction or rich, text-based context. Current multimodal large language models (MLLMs) in computational pathology face limitations, including insufficient training data, inadequate support and evaluation for multi-image understanding, and a lack of autonomous, diagnostic reasoning capabilities. To address these limitations, we introduce PathChat+, a new MLLM specifically designed for human pathology, trained on over 1 million diverse, pathology-specific instruction samples and nearly 5.5 million question answer turns. Extensive evaluations across diverse pathology benchmarks demonstrated that PathChat+ substantially outperforms the prior PathChat copilot, as well as both state-of-the-art (SOTA) general-purpose and other pathology-specific models. Furthermore, we present SlideSeek, a reasoning-enabled multi-agent AI system leveraging PathChat+ to autonomously evaluate gigapixel whole-slide images (WSIs) through iterative, hierarchical diagnostic reasoning, reaching high accuracy on DDxBench, a challenging open-ended differential diagnosis benchmark, while also capable of generating visually grounded, humanly-interpretable summary reports.
Multimodal Whole Slide Foundation Model for Pathology
Nov 29, 2024



The field of computational pathology has been transformed with recent advances in foundation models that encode histopathology region-of-interests (ROIs) into versatile and transferable feature representations via self-supervised learning (SSL). However, translating these advancements to address complex clinical challenges at the patient and slide level remains constrained by limited clinical data in disease-specific cohorts, especially for rare clinical conditions. We propose TITAN, a multimodal whole slide foundation model pretrained using 335,645 WSIs via visual self-supervised learning and vision-language alignment with corresponding pathology reports and 423,122 synthetic captions generated from a multimodal generative AI copilot for pathology. Without any finetuning or requiring clinical labels, TITAN can extract general-purpose slide representations and generate pathology reports that generalize to resource-limited clinical scenarios such as rare disease retrieval and cancer prognosis. We evaluate TITAN on diverse clinical tasks and find that TITAN outperforms both ROI and slide foundation models across machine learning settings such as linear probing, few-shot and zero-shot classification, rare cancer retrieval and cross-modal retrieval, and pathology report generation.
Scaling Vision Transformers to Gigapixel Images via Hierarchical Self-Supervised Learning
Jun 06, 2022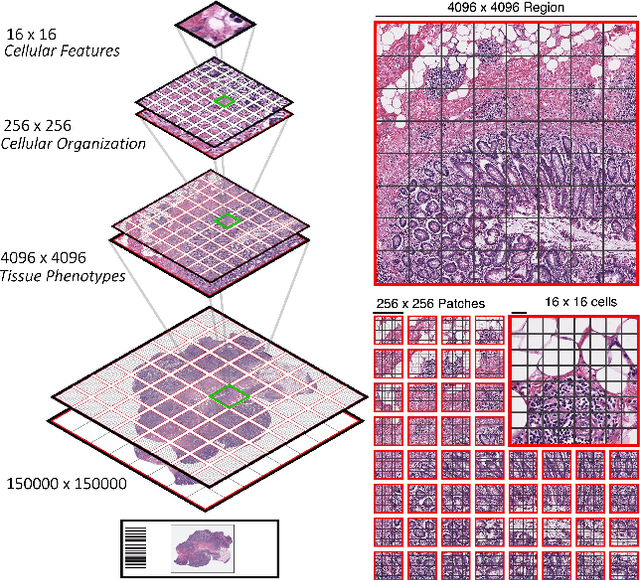
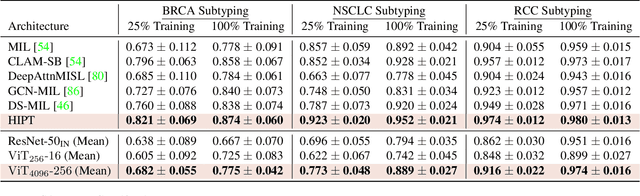
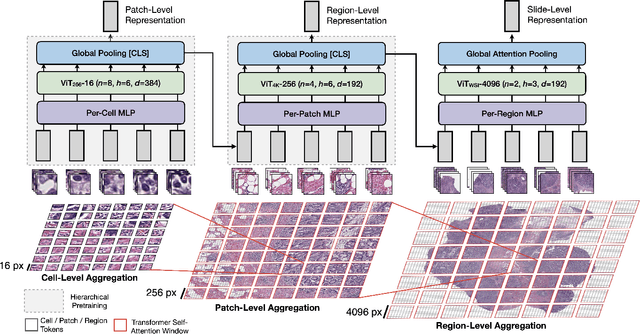

Vision Transformers (ViTs) and their multi-scale and hierarchical variations have been successful at capturing image representations but their use has been generally studied for low-resolution images (e.g. - 256x256, 384384). For gigapixel whole-slide imaging (WSI) in computational pathology, WSIs can be as large as 150000x150000 pixels at 20X magnification and exhibit a hierarchical structure of visual tokens across varying resolutions: from 16x16 images capture spatial patterns among cells, to 4096x4096 images characterizing interactions within the tissue microenvironment. We introduce a new ViT architecture called the Hierarchical Image Pyramid Transformer (HIPT), which leverages the natural hierarchical structure inherent in WSIs using two levels of self-supervised learning to learn high-resolution image representations. HIPT is pretrained across 33 cancer types using 10,678 gigapixel WSIs, 408,218 4096x4096 images, and 104M 256x256 images. We benchmark HIPT representations on 9 slide-level tasks, and demonstrate that: 1) HIPT with hierarchical pretraining outperforms current state-of-the-art methods for cancer subtyping and survival prediction, 2) self-supervised ViTs are able to model important inductive biases about the hierarchical structure of phenotypes in the tumor microenvironment.
Fast and Scalable Image Search For Histology
Jul 28, 2021



The expanding adoption of digital pathology has enabled the curation of large repositories of histology whole slide images (WSIs), which contain a wealth of information. Similar pathology image search offers the opportunity to comb through large historical repositories of gigapixel WSIs to identify cases with similar morphological features and can be particularly useful for diagnosing rare diseases, identifying similar cases for predicting prognosis, treatment outcomes, and potential clinical trial success. A critical challenge in developing a WSI search and retrieval system is scalability, which is uniquely challenging given the need to search a growing number of slides that each can consist of billions of pixels and are several gigabytes in size. Such systems are typically slow and retrieval speed often scales with the size of the repository they search through, making their clinical adoption tedious and are not feasible for repositories that are constantly growing. Here we present Fast Image Search for Histopathology (FISH), a histology image search pipeline that is infinitely scalable and achieves constant search speed that is independent of the image database size while being interpretable and without requiring detailed annotations. FISH uses self-supervised deep learning to encode meaningful representations from WSIs and a Van Emde Boas tree for fast search, followed by an uncertainty-based ranking algorithm to retrieve similar WSIs. We evaluated FISH on multiple tasks and datasets with over 22,000 patient cases spanning 56 disease subtypes. We additionally demonstrate that FISH can be used to assist with the diagnosis of rare cancer types where sufficient cases may not be available to train traditional supervised deep models. FISH is available as an easy-to-use, open-source software package (https://github.com/mahmoodlab/FISH).
Whole Slide Images are 2D Point Clouds: Context-Aware Survival Prediction using Patch-based Graph Convolutional Networks
Jul 27, 2021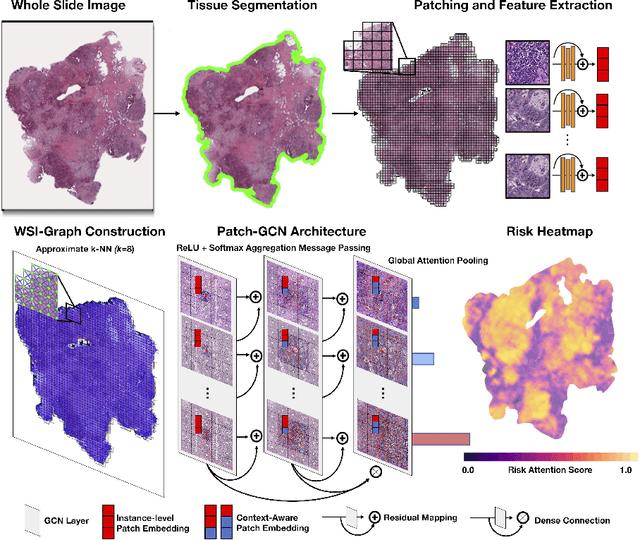
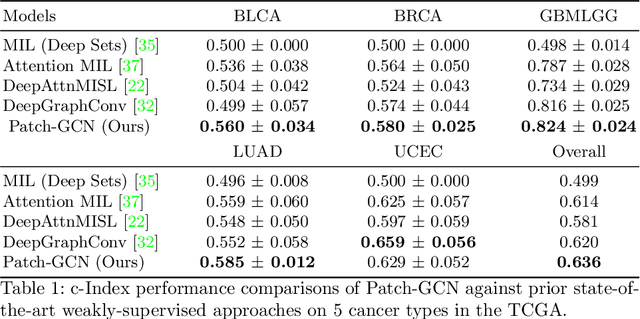
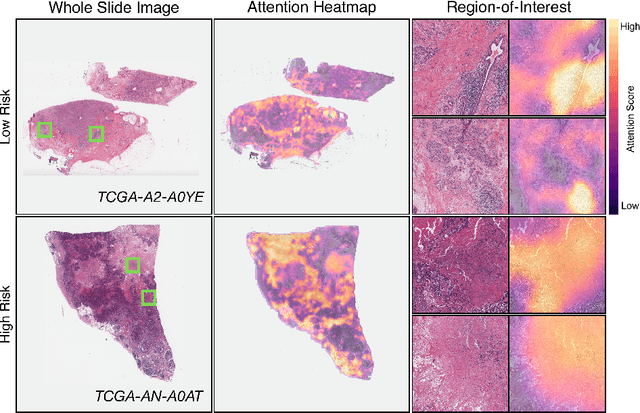
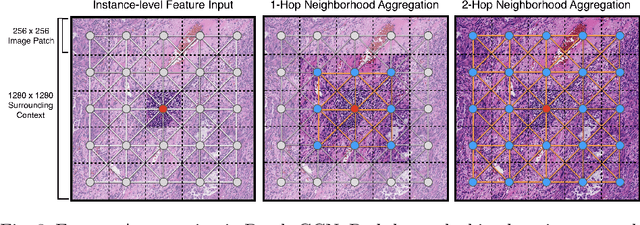
Cancer prognostication is a challenging task in computational pathology that requires context-aware representations of histology features to adequately infer patient survival. Despite the advancements made in weakly-supervised deep learning, many approaches are not context-aware and are unable to model important morphological feature interactions between cell identities and tissue types that are prognostic for patient survival. In this work, we present Patch-GCN, a context-aware, spatially-resolved patch-based graph convolutional network that hierarchically aggregates instance-level histology features to model local- and global-level topological structures in the tumor microenvironment. We validate Patch-GCN with 4,370 gigapixel WSIs across five different cancer types from the Cancer Genome Atlas (TCGA), and demonstrate that Patch-GCN outperforms all prior weakly-supervised approaches by 3.58-9.46%. Our code and corresponding models are publicly available at https://github.com/mahmoodlab/Patch-GCN.