 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaSubVAE: Adaptive Subgrouping for Scalable and Robust OOD Detection
Jun 11, 2025Real-world observational data often contain existing or emerging heterogeneous subpopulations that deviate from global patterns. The majority of models tend to overlook these underrepresented groups, leading to inaccurate or even harmful predictions. Existing solutions often rely on detecting these samples as Out-of-domain (OOD) rather than adapting the model to new emerging patterns. We introduce DynaSubVAE, a Dynamic Subgrouping Variational Autoencoder framework that jointly performs representation learning and adaptive OOD detection. Unlike conventional approaches, DynaSubVAE evolves with the data by dynamically updating its latent structure to capture new trends. It leverages a novel non-parametric clustering mechanism, inspired by Gaussian Mixture Models, to discover and model latent subgroups based on embedding similarity. Extensive experiments show that DynaSubVAE achieves competitive performance in both near-OOD and far-OOD detection, and excels in class-OOD scenarios where an entire class is missing during training. We further illustrate that our dynamic subgrouping mechanism outperforms standalone clustering methods such as GMM and KMeans++ in terms of both OOD accuracy and regret precision.
CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
Jun 09, 2025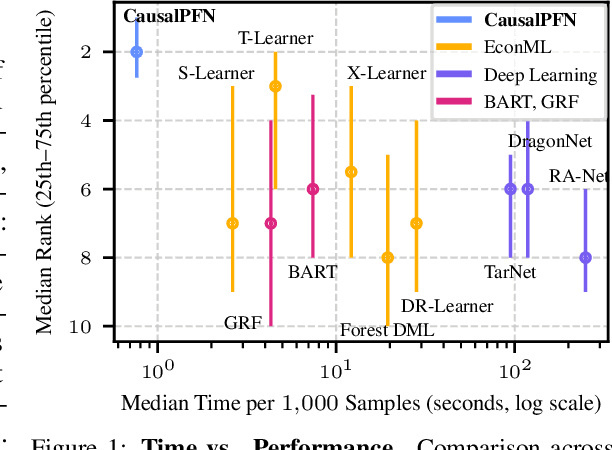
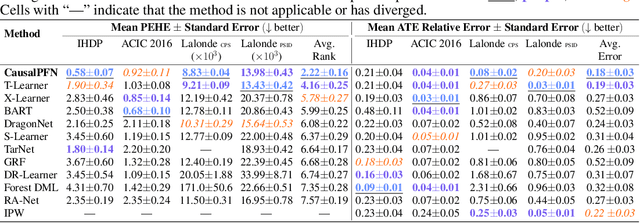
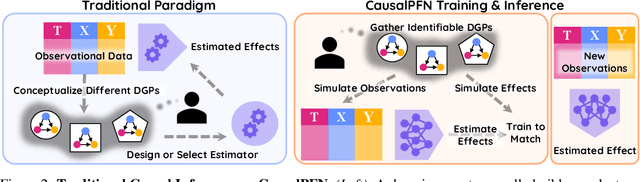
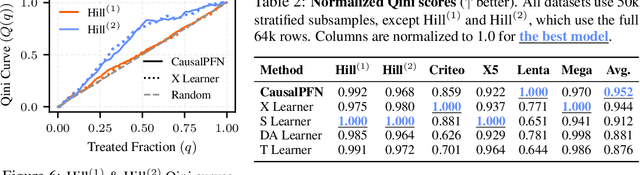
Causal effect estimation from observational data is fundamental across various applications. However, selecting an appropriate estimator from dozens of specialized methods demands substantial manual effort and domain expertise. We present CausalPFN, a single transformer that amortizes this workflow: trained once on a large library of simulated data-generating processes that satisfy ignorability, it infers causal effects for new observational datasets out-of-the-box. CausalPFN combines ideas from Bayesian causal inference with the large-scale training protocol of prior-fitted networks (PFNs), learning to map raw observations directly to causal effects without any task-specific adjustment. Our approach achieves superior average performance on heterogeneous and average treatment effect estimation benchmarks (IHDP, Lalonde, ACIC). Moreover, it shows competitive performance for real-world policy making on uplift modeling tasks. CausalPFN provides calibrated uncertainty estimates to support reliable decision-making based on Bayesian principles. This ready-to-use model does not require any further training or tuning and takes a step toward automated causal inference (https://github.com/vdblm/CausalPFN).
Reliably detecting model failures in deployment without labels
Jun 05, 2025The distribution of data changes over time; models operating operating in dynamic environments need retraining. But knowing when to retrain, without access to labels, is an open challenge since some, but not all shifts degrade model performance. This paper formalizes and addresses the problem of post-deployment deterioration (PDD) monitoring. We propose D3M, a practical and efficient monitoring algorithm based on the disagreement of predictive models, achieving low false positive rates under non-deteriorating shifts and provides sample complexity bounds for high true positive rates under deteriorating shifts. Empirical results on both standard benchmark and a real-world large-scale internal medicine dataset demonstrate the effectiveness of the framework and highlight its viability as an alert mechanism for high-stakes machine learning pipelines.
Diverse Prototypical Ensembles Improve Robustness to Subpopulation Shift
May 29, 2025The subpopulationtion shift, characterized by a disparity in subpopulation distributibetween theween the training and target datasets, can significantly degrade the performance of machine learning models. Current solutions to subpopulation shift involve modifying empirical risk minimization with re-weighting strategies to improve generalization. This strategy relies on assumptions about the number and nature of subpopulations and annotations on group membership, which are unavailable for many real-world datasets. Instead, we propose using an ensemble of diverse classifiers to adaptively capture risk associated with subpopulations. Given a feature extractor network, we replace its standard linear classification layer with a mixture of prototypical classifiers, where each member is trained to classify the data while focusing on different features and samples from other members. In empirical evaluation on nine real-world datasets, covering diverse domains and kinds of subpopulation shift, our method of Diverse Prototypical Ensembles (DPEs) often outperforms the prior state-of-the-art in worst-group accuracy. The code is available at https://github.com/minhto2802/dpe4subpop
Beyond Masked and Unmasked: Discrete Diffusion Models via Partial Masking
May 24, 2025Masked diffusion models (MDM) are powerful generative models for discrete data that generate samples by progressively unmasking tokens in a sequence. Each token can take one of two states: masked or unmasked. We observe that token sequences often remain unchanged between consecutive sampling steps; consequently, the model repeatedly processes identical inputs, leading to redundant computation. To address this inefficiency, we propose the Partial masking scheme (Prime), which augments MDM by allowing tokens to take intermediate states interpolated between the masked and unmasked states. This design enables the model to make predictions based on partially observed token information, and facilitates a fine-grained denoising process. We derive a variational training objective and introduce a simple architectural design to accommodate intermediate-state inputs. Our method demonstrates superior performance across a diverse set of generative modeling tasks. On text data, it achieves a perplexity of 15.36 on OpenWebText, outperforming previous MDM (21.52), autoregressive models (17.54), and their hybrid variants (17.58), without relying on an autoregressive formulation. On image data, it attains competitive FID scores of 3.26 on CIFAR-10 and 6.98 on ImageNet-32, comparable to leading continuous generative models.
ExOSITO: Explainable Off-Policy Learning with Side Information for Intensive Care Unit Blood Test Orders
Apr 24, 2025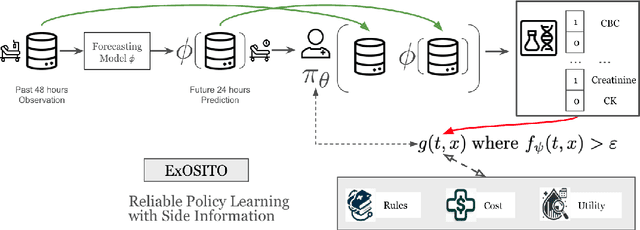
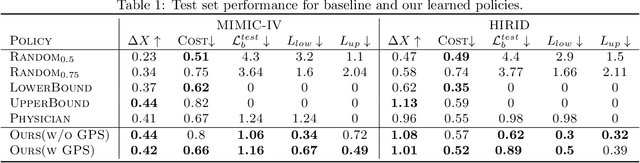
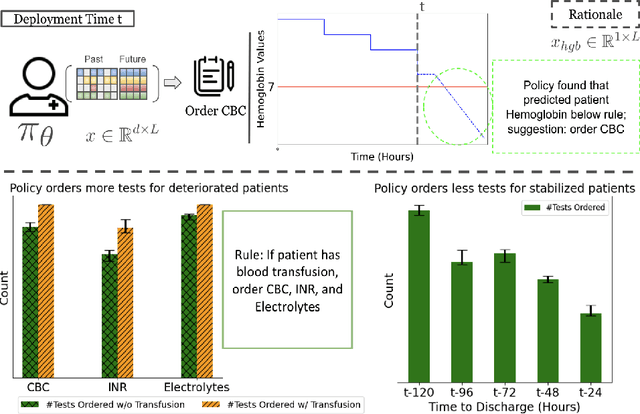

Ordering a minimal subset of lab tests for patients in the intensive care unit (ICU) can be challenging. Care teams must balance between ensuring the availability of the right information and reducing the clinical burden and costs associated with each lab test order. Most in-patient settings experience frequent over-ordering of lab tests, but are now aiming to reduce this burden on both hospital resources and the environment. This paper develops a novel method that combines off-policy learning with privileged information to identify the optimal set of ICU lab tests to order. Our approach, EXplainable Off-policy learning with Side Information for ICU blood Test Orders (ExOSITO) creates an interpretable assistive tool for clinicians to order lab tests by considering both the observed and predicted future status of each patient. We pose this problem as a causal bandit trained using offline data and a reward function derived from clinically-approved rules; we introduce a novel learning framework that integrates clinical knowledge with observational data to bridge the gap between the optimal and logging policies. The learned policy function provides interpretable clinical information and reduces costs without omitting any vital lab orders, outperforming both a physician's policy and prior approaches to this practical problem.
Teaching LLMs How to Learn with Contextual Fine-Tuning
Mar 12, 2025Prompting Large Language Models (LLMs), or providing context on the expected model of operation, is an effective way to steer the outputs of such models to satisfy human desiderata after they have been trained. But in rapidly evolving domains, there is often need to fine-tune LLMs to improve either the kind of knowledge in their memory or their abilities to perform open ended reasoning in new domains. When human's learn new concepts, we often do so by linking the new material that we are studying to concepts we have already learned before. To that end, we ask, "can prompting help us teach LLMs how to learn". In this work, we study a novel generalization of instruction tuning, called contextual fine-tuning, to fine-tune LLMs. Our method leverages instructional prompts designed to mimic human cognitive strategies in learning and problem-solving to guide the learning process during training, aiming to improve the model's interpretation and understanding of domain-specific knowledge. We empirically demonstrate that this simple yet effective modification improves the ability of LLMs to be fine-tuned rapidly on new datasets both within the medical and financial domains.
Adaptive Knowledge Graphs Enhance Medical Question Answering: Bridging the Gap Between LLMs and Evolving Medical Knowledge
Feb 18, 2025



Large Language Models (LLMs) have significantly advanced medical question-answering by leveraging extensive clinical data and medical literature. However, the rapid evolution of medical knowledge and the labor-intensive process of manually updating domain-specific resources pose challenges to the reliability of these systems. To address this, we introduce Adaptive Medical Graph-RAG (AMG-RAG), a comprehensive framework that automates the construction and continuous updating of medical knowledge graphs, integrates reasoning, and retrieves current external evidence, such as PubMed and WikiSearch. By dynamically linking new findings and complex medical concepts, AMG-RAG not only improves accuracy but also enhances interpretability in medical queries. Evaluations on the MEDQA and MEDMCQA benchmarks demonstrate the effectiveness of AMG-RAG, achieving an F1 score of 74.1 percent on MEDQA and an accuracy of 66.34 percent on MEDMCQA, outperforming both comparable models and those 10 to 100 times larger. Notably, these improvements are achieved without increasing computational overhead, highlighting the critical role of automated knowledge graph generation and external evidence retrieval in delivering up-to-date, trustworthy medical insights.
A generalizable 3D framework and model for self-supervised learning in medical imaging
Jan 20, 2025



Current self-supervised learning methods for 3D medical imaging rely on simple pretext formulations and organ- or modality-specific datasets, limiting their generalizability and scalability. We present 3DINO, a cutting-edge SSL method adapted to 3D datasets, and use it to pretrain 3DINO-ViT: a general-purpose medical imaging model, on an exceptionally large, multimodal, and multi-organ dataset of ~100,000 3D medical imaging scans from over 10 organs. We validate 3DINO-ViT using extensive experiments on numerous medical imaging segmentation and classification tasks. Our results demonstrate that 3DINO-ViT generalizes across modalities and organs, including out-of-distribution tasks and datasets, outperforming state-of-the-art methods on the majority of evaluation metrics and labeled dataset sizes. Our 3DINO framework and 3DINO-ViT will be made available to enable research on 3D foundation models or further finetuning for a wide range of medical imaging applications.
Synthetic Vision: Training Vision-Language Models to Understand Physics
Dec 11, 2024



Physical reasoning, which involves the interpretation, understanding, and prediction of object behavior in dynamic environments, remains a significant challenge for current Vision-Language Models (VLMs). In this work, we propose two methods to enhance VLMs' physical reasoning capabilities using simulated data. First, we fine-tune a pre-trained VLM using question-answer (QA) pairs generated from simulations relevant to physical reasoning tasks. Second, we introduce Physics Context Builders (PCBs), specialized VLMs fine-tuned to create scene descriptions enriched with physical properties and processes. During physical reasoning tasks, these PCBs can be leveraged as context to assist a Large Language Model (LLM) to improve its performance. We evaluate both of our approaches using multiple benchmarks, including a new stability detection QA dataset called Falling Tower, which includes both simulated and real-world scenes, and CLEVRER. We demonstrate that a small QA fine-tuned VLM can significantly outperform larger state-of-the-art foundational models. We also show that integrating PCBs boosts the performance of foundational LLMs on physical reasoning tasks. Using the real-world scenes from the Falling Tower dataset, we also validate the robustness of both approaches in Sim2Real transfer. Our results highlight the utility that simulated data can have in the creation of learning systems capable of advanced physical reasoning.