 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralization Can Emerge in Tabular Foundation Models From a Single Table
Nov 12, 2025



Deep tabular modelling increasingly relies on in-context learning where, during inference, a model receives a set of $(x,y)$ pairs as context and predicts labels for new inputs without weight updates. We challenge the prevailing view that broad generalization here requires pre-training on large synthetic corpora (e.g., TabPFN priors) or a large collection of real data (e.g., TabDPT training datasets), discovering that a relatively small amount of data suffices for generalization. We find that simple self-supervised pre-training on just a \emph{single} real table can produce surprisingly strong transfer across heterogeneous benchmarks. By systematically pre-training and evaluating on many diverse datasets, we analyze what aspects of the data are most important for building a Tabular Foundation Model (TFM) generalizing across domains. We then connect this to the pre-training procedure shared by most TFMs and show that the number and quality of \emph{tasks} one can construct from a dataset is key to downstream performance.
CausalPFN: Amortized Causal Effect Estimation via In-Context Learning
Jun 09, 2025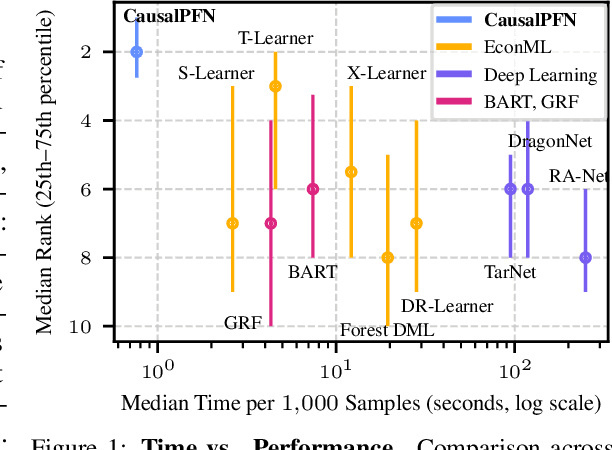
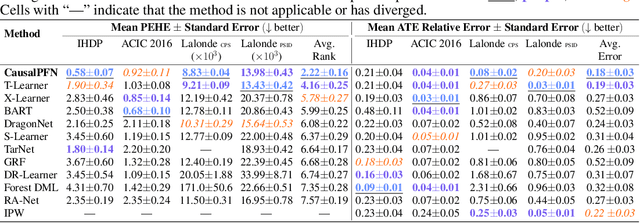
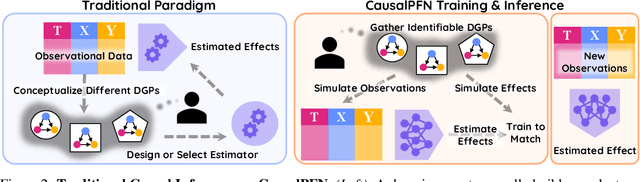
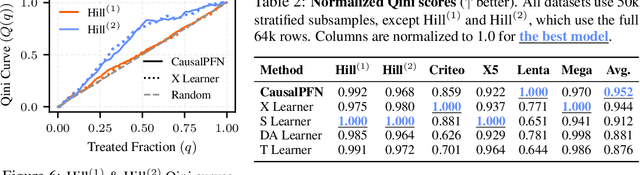
Causal effect estimation from observational data is fundamental across various applications. However, selecting an appropriate estimator from dozens of specialized methods demands substantial manual effort and domain expertise. We present CausalPFN, a single transformer that amortizes this workflow: trained once on a large library of simulated data-generating processes that satisfy ignorability, it infers causal effects for new observational datasets out-of-the-box. CausalPFN combines ideas from Bayesian causal inference with the large-scale training protocol of prior-fitted networks (PFNs), learning to map raw observations directly to causal effects without any task-specific adjustment. Our approach achieves superior average performance on heterogeneous and average treatment effect estimation benchmarks (IHDP, Lalonde, ACIC). Moreover, it shows competitive performance for real-world policy making on uplift modeling tasks. CausalPFN provides calibrated uncertainty estimates to support reliable decision-making based on Bayesian principles. This ready-to-use model does not require any further training or tuning and takes a step toward automated causal inference (https://github.com/vdblm/CausalPFN).
TabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
In-Context Data Distillation with TabPFN
Feb 10, 2024Foundation models have revolutionized tasks in computer vision and natural language processing. However, in the realm of tabular data, tree-based models like XGBoost continue to dominate. TabPFN, a transformer model tailored for tabular data, mirrors recent foundation models in its exceptional in-context learning capability, being competitive with XGBoost's performance without the need for task-specific training or hyperparameter tuning. Despite its promise, TabPFN's applicability is hindered by its data size constraint, limiting its use in real-world scenarios. To address this, we present in-context data distillation (ICD), a novel methodology that effectively eliminates these constraints by optimizing TabPFN's context. ICD efficiently enables TabPFN to handle significantly larger datasets with a fixed memory budget, improving TabPFN's quadratic memory complexity but at the cost of a linear number of tuning steps. Notably, TabPFN, enhanced with ICD, demonstrates very strong performance against established tree-based models and modern deep learning methods on 48 large tabular datasets from OpenML.
The Role of Baselines in Policy Gradient Optimization
Jan 16, 2023We study the effect of baselines in on-policy stochastic policy gradient optimization, and close the gap between the theory and practice of policy optimization methods. Our first contribution is to show that the \emph{state value} baseline allows on-policy stochastic \emph{natural} policy gradient (NPG) to converge to a globally optimal policy at an $O(1/t)$ rate, which was not previously known. The analysis relies on two novel findings: the expected progress of the NPG update satisfies a stochastic version of the non-uniform \L{}ojasiewicz (N\L{}) inequality, and with probability 1 the state value baseline prevents the optimal action's probability from vanishing, thus ensuring sufficient exploration. Importantly, these results provide a new understanding of the role of baselines in stochastic policy gradient: by showing that the variance of natural policy gradient estimates remains unbounded with or without a baseline, we find that variance reduction \emph{cannot} explain their utility in this setting. Instead, the analysis reveals that the primary effect of the value baseline is to \textbf{reduce the aggressiveness of the updates} rather than their variance. That is, we demonstrate that a finite variance is \emph{not necessary} for almost sure convergence of stochastic NPG, while controlling update aggressiveness is both necessary and sufficient. Additional experimental results verify these theoretical findings.
Beyond variance reduction: Understanding the true impact of baselines on policy optimization
Aug 31, 2020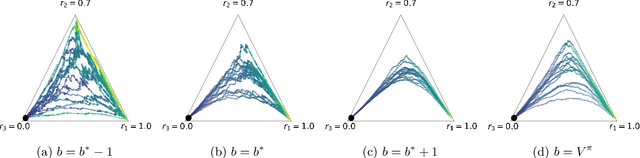
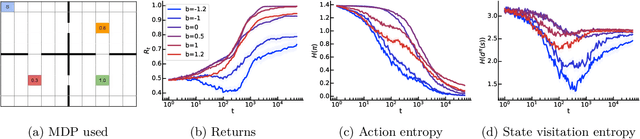
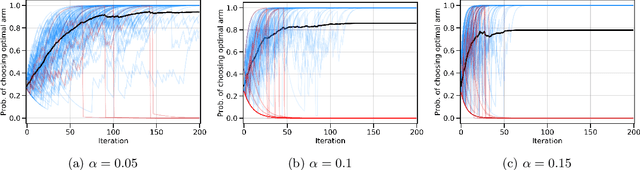
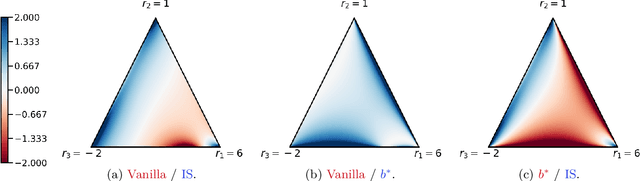
Policy gradients methods are a popular and effective choice to train reinforcement learning agents in complex environments. The variance of the stochastic policy gradient is often seen as a key quantity to determine the effectiveness of the algorithm. Baselines are a common addition to reduce the variance of the gradient, but previous works have hardly ever considered other effects baselines may have on the optimization process. Using simple examples, we find that baselines modify the optimization dynamics even when the variance is the same. In certain cases, a baseline with lower variance may even be worse than another with higher variance. Furthermore, we find that the choice of baseline can affect the convergence of natural policy gradient, where certain baselines may lead to convergence to a suboptimal policy for any stepsize. Such behaviour emerges when sampling is constrained to be done using the current policy and we show how decoupling the sampling policy from the current policy guarantees convergence for a much wider range of baselines. More broadly, this work suggests that a more careful treatment of stochasticity in the updates---beyond the immediate variance---is necessary to understand the optimization process of policy gradient algorithms.
Information matrices and generalization
Jun 18, 2019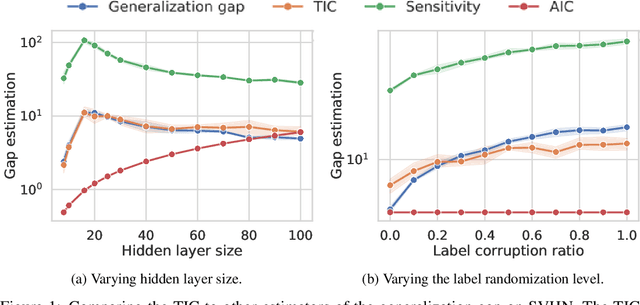
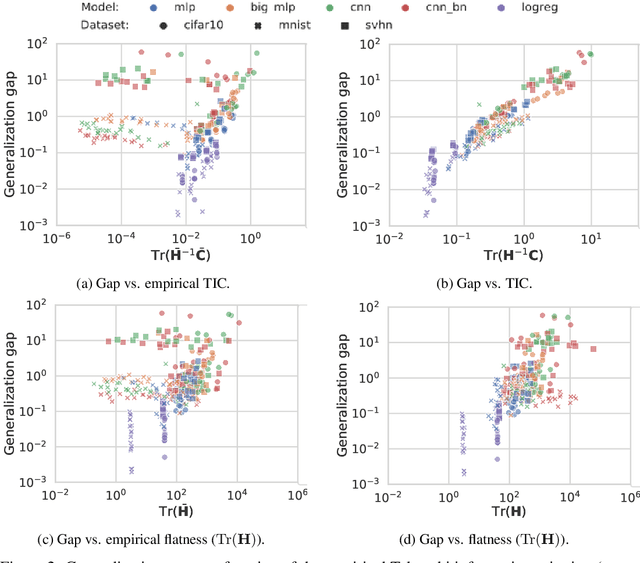
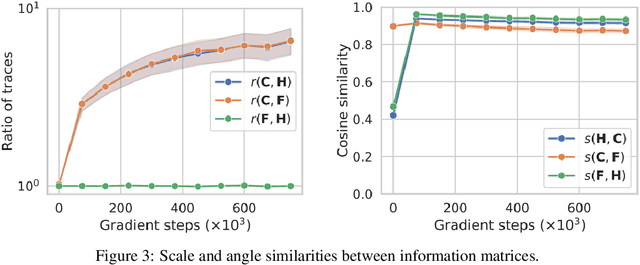
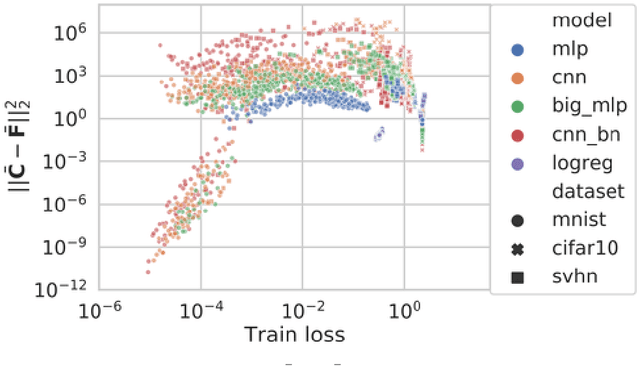
This work revisits the use of information criteria to characterize the generalization of deep learning models. In particular, we empirically demonstrate the effectiveness of the Takeuchi information criterion (TIC), an extension of the Akaike information criterion (AIC) for misspecified models, in estimating the generalization gap, shedding light on why quantities such as the number of parameters cannot quantify generalization. The TIC depends on both the Hessian of the loss H and the covariance of the gradients C. By exploring the similarities and differences between these two matrices as well as the Fisher information matrix F, we study the interplay between noise and curvature in deep models. We also address the question of whether C is a reasonable approximation to F, as is commonly assumed.
Disentangling the independently controllable factors of variation by interacting with the world
Feb 26, 2018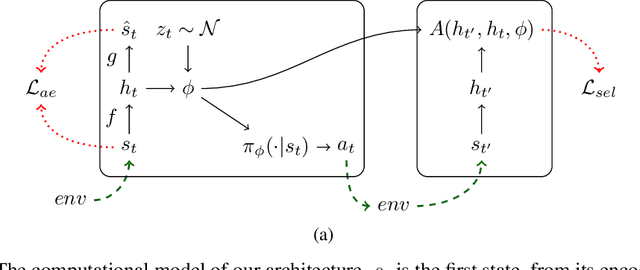
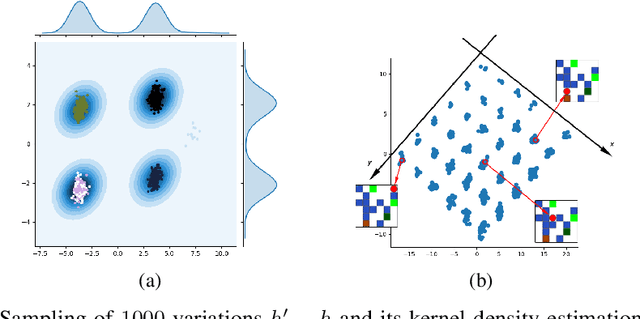
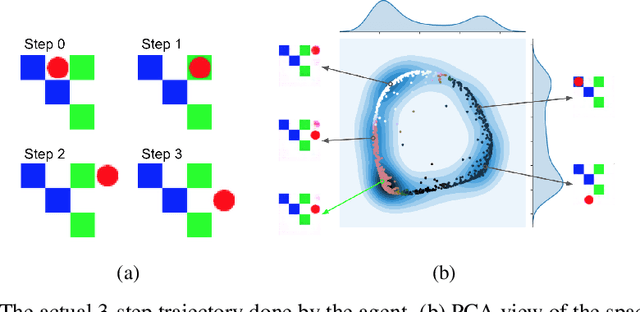
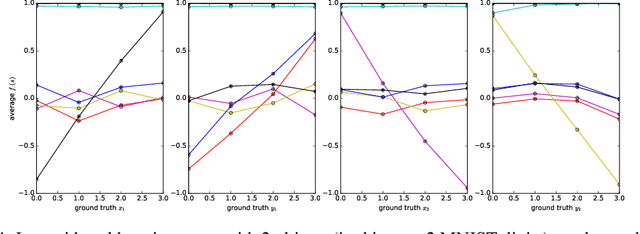
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors, and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.
Independently Controllable Factors
Aug 25, 2017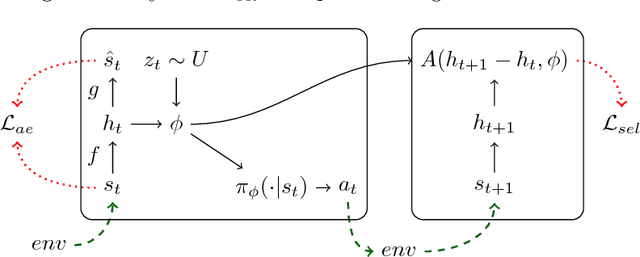
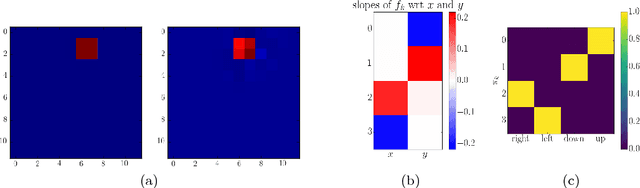
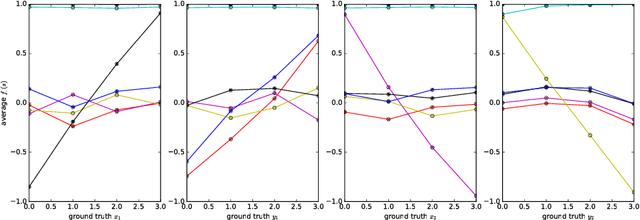
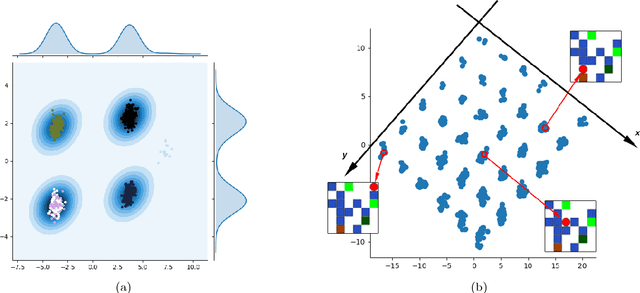
It has been postulated that a good representation is one that disentangles the underlying explanatory factors of variation. However, it remains an open question what kind of training framework could potentially achieve that. Whereas most previous work focuses on the static setting (e.g., with images), we postulate that some of the causal factors could be discovered if the learner is allowed to interact with its environment. The agent can experiment with different actions and observe their effects. More specifically, we hypothesize that some of these factors correspond to aspects of the environment which are independently controllable, i.e., that there exists a policy and a learnable feature for each such aspect of the environment, such that this policy can yield changes in that feature with minimal changes to other features that explain the statistical variations in the observed data. We propose a specific objective function to find such factors and verify experimentally that it can indeed disentangle independently controllable aspects of the environment without any extrinsic reward signal.