 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Dense Retrievers with LLM Utility via DistillationAligning Dense Retrievers with LLM Utility via Distillation
Apr 24, 2026Dense vector retrieval is the practical backbone of Retrieval- Augmented Generation (RAG), but similarity search can suffer from precision limitations. Conversely, utility-based approaches leveraging LLM re-ranking often achieve superior performance but are computationally prohibitive and prone to noise inherent in perplexity estimation. We propose Utility-Aligned Embeddings (UAE), a framework designed to merge these advantages into a practical, high-performance retrieval method. We formulate retrieval as a distribution matching problem, training a bi-encoder to imitate a utility distribution derived from perplexity reduction using a Utility-Modulated InfoNCE objective. This approach injects graded utility signals directly into the embedding space without requiring test-time LLM inference. On the QASPER benchmark, UAE improves retrieval Recall@1 by 30.59%, MAP by 30.16% and Token F1 by 17.3% over the strong semantic baseline BGE-Base. Crucially, UAE is over 180x faster than the efficient LLM re-ranking methods preserving competitive performance, demonstrating that aligning retrieval with generative utility yields reliable contexts at scale.
TabDPT: Scaling Tabular Foundation Models
Oct 23, 2024



The challenges faced by neural networks on tabular data are well-documented and have hampered the progress of tabular foundation models. Techniques leveraging in-context learning (ICL) have shown promise here, allowing for dynamic adaptation to unseen data. ICL can provide predictions for entirely new datasets without further training or hyperparameter tuning, therefore providing very fast inference when encountering a novel task. However, scaling ICL for tabular data remains an issue: approaches based on large language models cannot efficiently process numeric tables, and tabular-specific techniques have not been able to effectively harness the power of real data to improve performance and generalization. We are able to overcome these challenges by training tabular-specific ICL-based architectures on real data with self-supervised learning and retrieval, combining the best of both worlds. Our resulting model -- the Tabular Discriminative Pre-trained Transformer (TabDPT) -- achieves state-of-the-art performance on the CC18 (classification) and CTR23 (regression) benchmarks with no task-specific fine-tuning, demonstrating the adapatability and speed of ICL once the model is pre-trained. TabDPT also demonstrates strong scaling as both model size and amount of available data increase, pointing towards future improvements simply through the curation of larger tabular pre-training datasets and training larger models.
Retrieval & Fine-Tuning for In-Context Tabular Models
Jun 07, 2024Tabular data is a pervasive modality spanning a wide range of domains, and the inherent diversity poses a considerable challenge for deep learning. Recent advancements using transformer-based in-context learning have shown promise on smaller and less complex datasets, but have struggled to scale to larger and more complex ones. To address this limitation, we propose a combination of retrieval and fine-tuning: we can adapt the transformer to a local subset of the data by collecting nearest neighbours, and then perform task-specific fine-tuning with this retrieved set of neighbours in context. Using TabPFN as the base model -- currently the best tabular in-context learner -- and applying our retrieval and fine-tuning scheme on top results in what we call a locally-calibrated PFN, or LoCalPFN. We conduct extensive evaluation on 95 datasets curated by TabZilla from OpenML, upon which we establish a new state-of-the-art with LoCalPFN -- even with respect to tuned tree-based models. Notably, we show a significant boost in performance compared to the base in-context model, demonstrating the efficacy of our approach and advancing the frontier of deep learning in tabular data.
Data-Efficient Multimodal Fusion on a Single GPU
Jan 02, 2024



The goal of multimodal alignment is to learn a single latent space that is shared between multimodal inputs. The most powerful models in this space have been trained using massive datasets of paired inputs and large-scale computational resources, making them prohibitively expensive to train in many practical scenarios. We surmise that existing unimodal encoders pre-trained on large amounts of unimodal data should provide an effective bootstrap to create multimodal models from unimodal ones at much lower costs. We therefore propose FuseMix, a multimodal augmentation scheme that operates on the latent spaces of arbitrary pre-trained unimodal encoders. Using FuseMix for multimodal alignment, we achieve competitive performance -- and in certain cases outperform state-of-the art methods -- in both image-text and audio-text retrieval, with orders of magnitude less compute and data: for example, we outperform CLIP on the Flickr30K text-to-image retrieval task with $\sim \! 600\times$ fewer GPU days and $\sim \! 80\times$ fewer image-text pairs. Additionally, we show how our method can be applied to convert pre-trained text-to-image generative models into audio-to-image ones. Code is available at: https://github.com/layer6ai-labs/fusemix.
MultiResFormer: Transformer with Adaptive Multi-Resolution Modeling for General Time Series Forecasting
Nov 30, 2023



Transformer-based models have greatly pushed the boundaries of time series forecasting recently. Existing methods typically encode time series data into $\textit{patches}$ using one or a fixed set of patch lengths. This, however, could result in a lack of ability to capture the variety of intricate temporal dependencies present in real-world multi-periodic time series. In this paper, we propose MultiResFormer, which dynamically models temporal variations by adaptively choosing optimal patch lengths. Concretely, at the beginning of each layer, time series data is encoded into several parallel branches, each using a detected periodicity, before going through the transformer encoder block. We conduct extensive evaluations on long- and short-term forecasting datasets comparing MultiResFormer with state-of-the-art baselines. MultiResFormer outperforms patch-based Transformer baselines on long-term forecasting tasks and also consistently outperforms CNN baselines by a large margin, while using much fewer parameters than these baselines.
Self-supervised Representation Learning From Random Data Projectors
Oct 11, 2023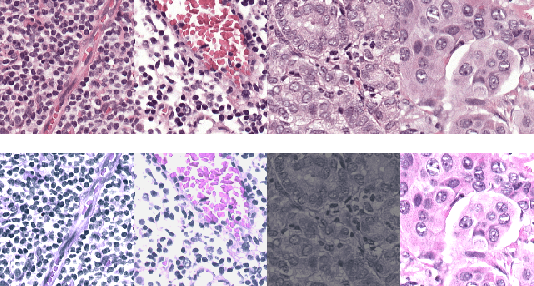

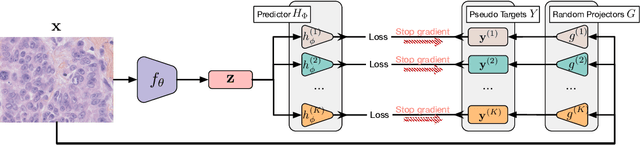
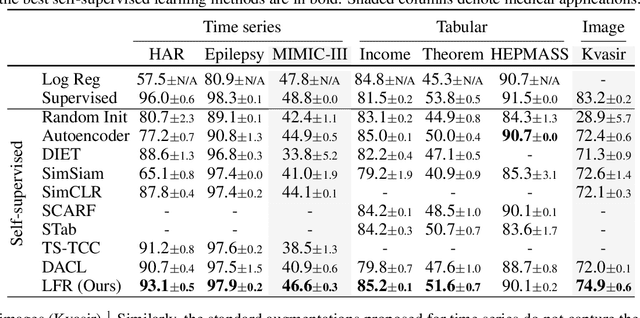
Self-supervised representation learning~(SSRL) has advanced considerably by exploiting the transformation invariance assumption under artificially designed data augmentations. While augmentation-based SSRL algorithms push the boundaries of performance in computer vision and natural language processing, they are often not directly applicable to other data modalities, and can conflict with application-specific data augmentation constraints. This paper presents an SSRL approach that can be applied to any data modality and network architecture because it does not rely on augmentations or masking. Specifically, we show that high-quality data representations can be learned by reconstructing random data projections. We evaluate the proposed approach on a wide range of representation learning tasks that span diverse modalities and real-world applications. We show that it outperforms multiple state-of-the-art SSRL baselines. Due to its wide applicability and strong empirical results, we argue that learning from randomness is a fruitful research direction worthy of attention and further study.
DuETT: Dual Event Time Transformer for Electronic Health Records
Apr 25, 2023Electronic health records (EHRs) recorded in hospital settings typically contain a wide range of numeric time series data that is characterized by high sparsity and irregular observations. Effective modelling for such data must exploit its time series nature, the semantic relationship between different types of observations, and information in the sparsity structure of the data. Self-supervised Transformers have shown outstanding performance in a variety of structured tasks in NLP and computer vision. But multivariate time series data contains structured relationships over two dimensions: time and recorded event type, and straightforward applications of Transformers to time series data do not leverage this distinct structure. The quadratic scaling of self-attention layers can also significantly limit the input sequence length without appropriate input engineering. We introduce the DuETT architecture, an extension of Transformers designed to attend over both time and event type dimensions, yielding robust representations from EHR data. DuETT uses an aggregated input where sparse time series are transformed into a regular sequence with fixed length; this lowers the computational complexity relative to previous EHR Transformer models and, more importantly, enables the use of larger and deeper neural networks. When trained with self-supervised prediction tasks, that provide rich and informative signals for model pre-training, our model outperforms state-of-the-art deep learning models on multiple downstream tasks from the MIMIC-IV and PhysioNet-2012 EHR datasets.
DiMS: Distilling Multiple Steps of Iterative Non-Autoregressive Transformers
Jun 07, 2022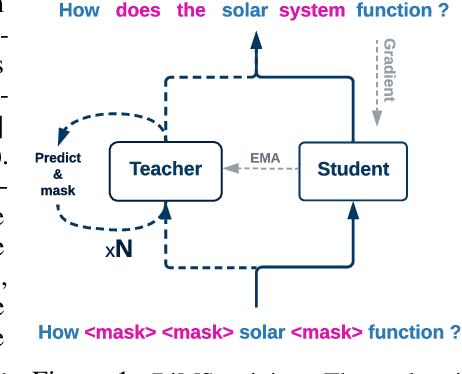
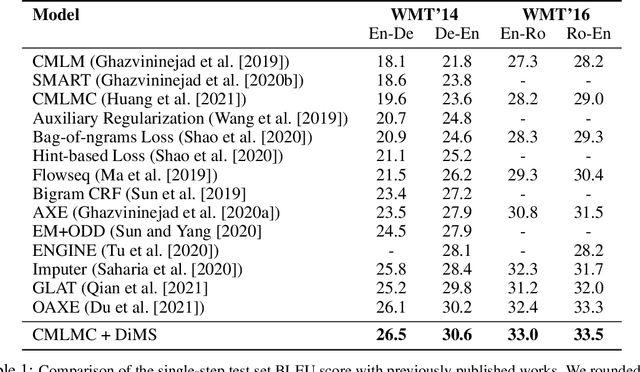
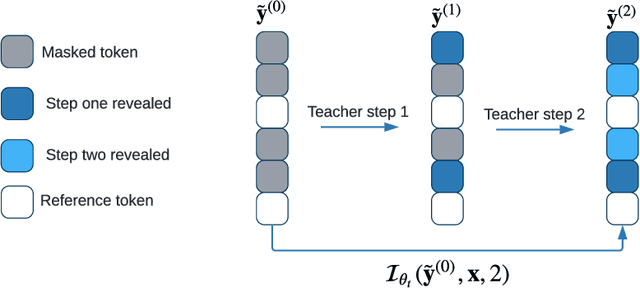

The computational benefits of iterative non-autoregressive transformers decrease as the number of decoding steps increases. As a remedy, we introduce Distill Multiple Steps (DiMS), a simple yet effective distillation technique to decrease the number of required steps to reach a certain translation quality. The distilled model enjoys the computational benefits of early iterations while preserving the enhancements from several iterative steps. DiMS relies on two models namely student and teacher. The student is optimized to predict the output of the teacher after multiple decoding steps while the teacher follows the student via a slow-moving average. The moving average keeps the teacher's knowledge updated and enhances the quality of the labels provided by the teacher. During inference, the student is used for translation and no additional computation is added. We verify the effectiveness of DiMS on various models obtaining improvements of up to 7 BLEU points on distilled and 12 BLEU points on raw WMT datasets for single-step translation. We release our code at https://github.com/layer6ai-labs/DiMS.
X-Pool: Cross-Modal Language-Video Attention for Text-Video Retrieval
Mar 28, 2022
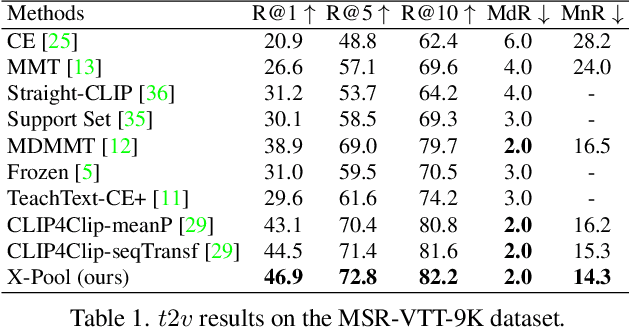
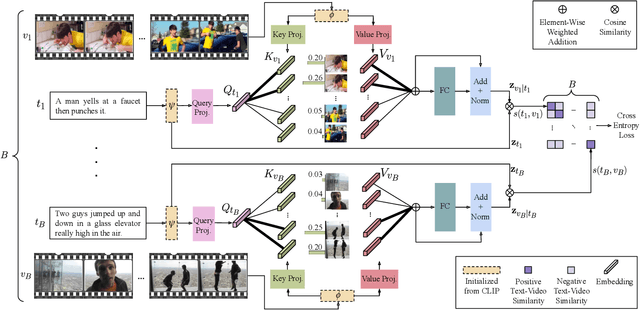
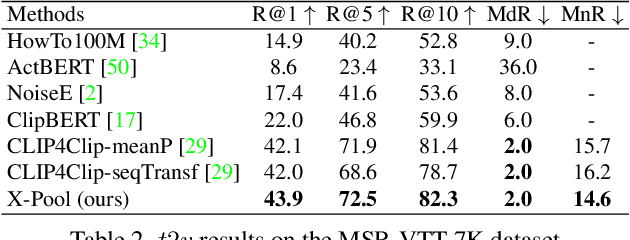
In text-video retrieval, the objective is to learn a cross-modal similarity function between a text and a video that ranks relevant text-video pairs higher than irrelevant pairs. However, videos inherently express a much wider gamut of information than texts. Instead, texts often capture sub-regions of entire videos and are most semantically similar to certain frames within videos. Therefore, for a given text, a retrieval model should focus on the text's most semantically similar video sub-regions to make a more relevant comparison. Yet, most existing works aggregate entire videos without directly considering text. Common text-agnostic aggregations schemes include mean-pooling or self-attention over the frames, but these are likely to encode misleading visual information not described in the given text. To address this, we propose a cross-modal attention model called X-Pool that reasons between a text and the frames of a video. Our core mechanism is a scaled dot product attention for a text to attend to its most semantically similar frames. We then generate an aggregated video representation conditioned on the text's attention weights over the frames. We evaluate our method on three benchmark datasets of MSR-VTT, MSVD and LSMDC, achieving new state-of-the-art results by up to 12% in relative improvement in Recall@1. Our findings thereby highlight the importance of joint text-video reasoning to extract important visual cues according to text. Full code and demo can be found at: https://layer6ai-labs.github.io/xpool/
ProxyFL: Decentralized Federated Learning through Proxy Model Sharing
Nov 22, 2021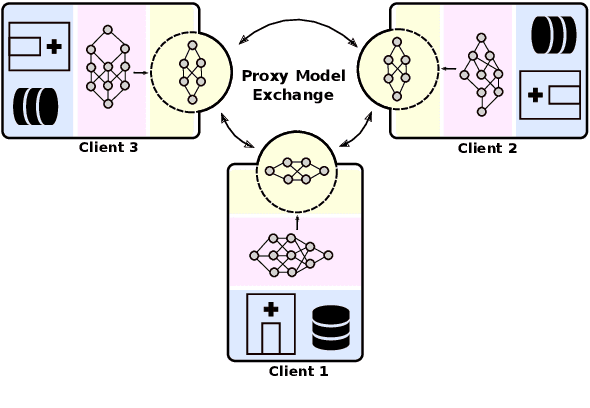
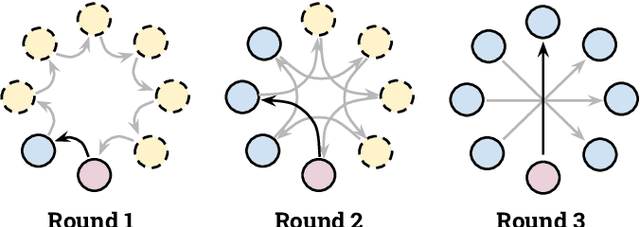
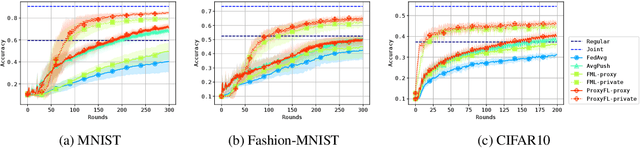
Institutions in highly regulated domains such as finance and healthcare often have restrictive rules around data sharing. Federated learning is a distributed learning framework that enables multi-institutional collaborations on decentralized data with improved protection for each collaborator's data privacy. In this paper, we propose a communication-efficient scheme for decentralized federated learning called ProxyFL, or proxy-based federated learning. Each participant in ProxyFL maintains two models, a private model, and a publicly shared proxy model designed to protect the participant's privacy. Proxy models allow efficient information exchange among participants using the PushSum method without the need of a centralized server. The proposed method eliminates a significant limitation of canonical federated learning by allowing model heterogeneity; each participant can have a private model with any architecture. Furthermore, our protocol for communication by proxy leads to stronger privacy guarantees using differential privacy analysis. Experiments on popular image datasets, and a pan-cancer diagnostic problem using over 30,000 high-quality gigapixel histology whole slide images, show that ProxyFL can outperform existing alternatives with much less communication overhead and stronger privacy.