 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTextual Bayes: Quantifying Uncertainty in LLM-Based Systems
Jun 11, 2025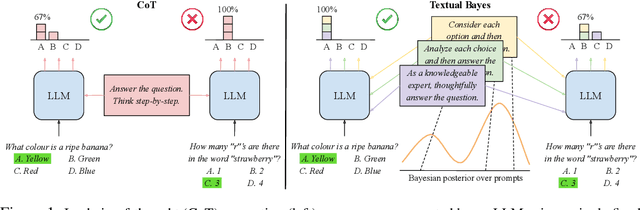
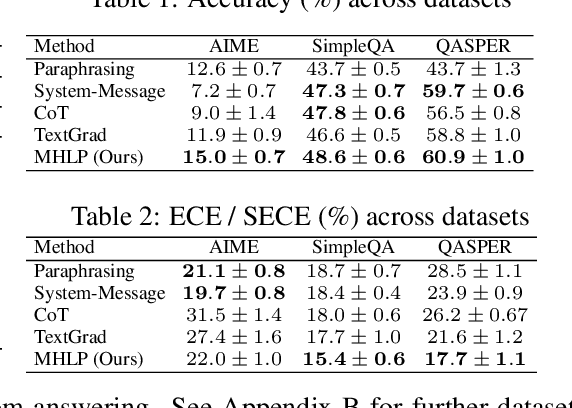
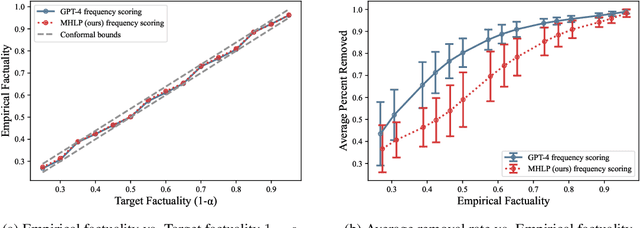
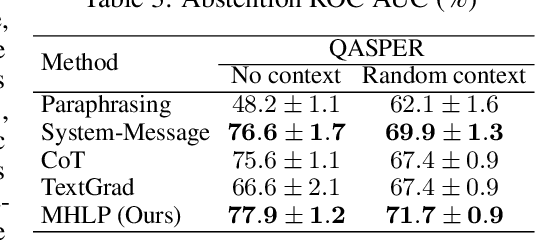
Although large language models (LLMs) are becoming increasingly capable of solving challenging real-world tasks, accurately quantifying their uncertainty remains a critical open problem, which limits their applicability in high-stakes domains. This challenge is further compounded by the closed-source, black-box nature of many state-of-the-art LLMs. Moreover, LLM-based systems can be highly sensitive to the prompts that bind them together, which often require significant manual tuning (i.e., prompt engineering). In this work, we address these challenges by viewing LLM-based systems through a Bayesian lens. We interpret prompts as textual parameters in a statistical model, allowing us to use a small training dataset to perform Bayesian inference over these prompts. This novel perspective enables principled uncertainty quantification over both the model's textual parameters and its downstream predictions, while also incorporating prior beliefs about these parameters expressed in free-form text. To perform Bayesian inference, a difficult problem even for well-studied data modalities, we introduce Metropolis-Hastings through LLM Proposals (MHLP), a novel Markov chain Monte Carlo (MCMC) algorithm that combines prompt optimization techniques with standard MCMC methods. MHLP is a turnkey modification to existing LLM pipelines, including those that rely exclusively on closed-source models. Empirically, we demonstrate that our method yields improvements in both predictive accuracy and uncertainty quantification (UQ) on a range of LLM benchmarks and UQ tasks. More broadly, our work demonstrates a viable path for incorporating methods from the rich Bayesian literature into the era of LLMs, paving the way for more reliable and calibrated LLM-based systems.
MultiResFormer: Transformer with Adaptive Multi-Resolution Modeling for General Time Series Forecasting
Nov 30, 2023



Transformer-based models have greatly pushed the boundaries of time series forecasting recently. Existing methods typically encode time series data into $\textit{patches}$ using one or a fixed set of patch lengths. This, however, could result in a lack of ability to capture the variety of intricate temporal dependencies present in real-world multi-periodic time series. In this paper, we propose MultiResFormer, which dynamically models temporal variations by adaptively choosing optimal patch lengths. Concretely, at the beginning of each layer, time series data is encoded into several parallel branches, each using a detected periodicity, before going through the transformer encoder block. We conduct extensive evaluations on long- and short-term forecasting datasets comparing MultiResFormer with state-of-the-art baselines. MultiResFormer outperforms patch-based Transformer baselines on long-term forecasting tasks and also consistently outperforms CNN baselines by a large margin, while using much fewer parameters than these baselines.
Building an Efficiency Pipeline: Commutativity and Cumulativeness of Efficiency Operators for Transformers
Jul 31, 2022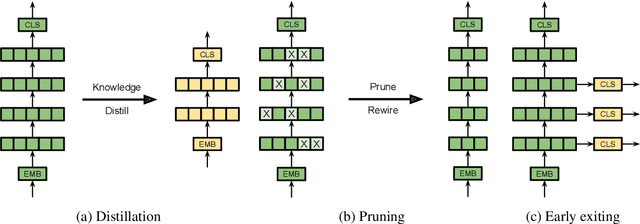
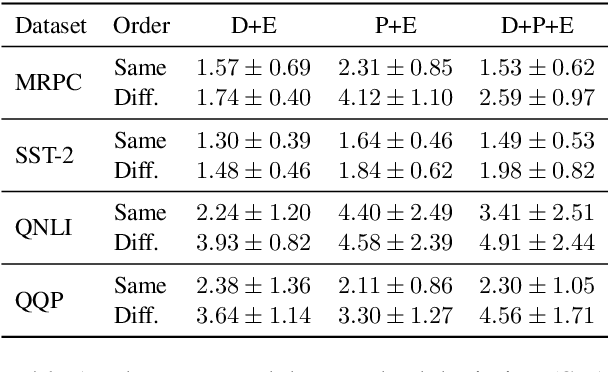
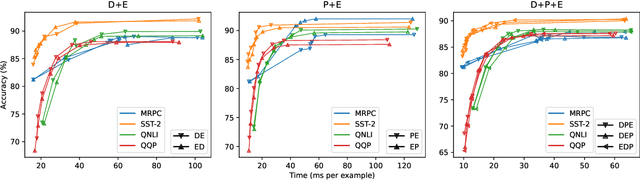
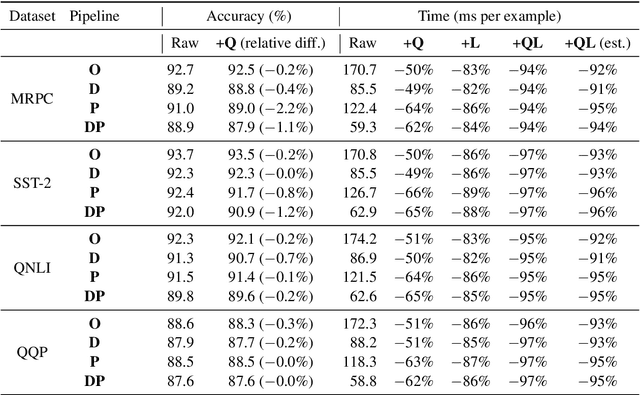
There exists a wide variety of efficiency methods for natural language processing (NLP) tasks, such as pruning, distillation, dynamic inference, quantization, etc. We can consider an efficiency method as an operator applied on a model. Naturally, we may construct a pipeline of multiple efficiency methods, i.e., to apply multiple operators on the model sequentially. In this paper, we study the plausibility of this idea, and more importantly, the commutativity and cumulativeness of efficiency operators. We make two interesting observations: (1) Efficiency operators are commutative -- the order of efficiency methods within the pipeline has little impact on the final results; (2) Efficiency operators are also cumulative -- the final results of combining several efficiency methods can be estimated by combining the results of individual methods. These observations deepen our understanding of efficiency operators and provide useful guidelines for their real-world applications.
Few-Shot Non-Parametric Learning with Deep Latent Variable Model
Jun 23, 2022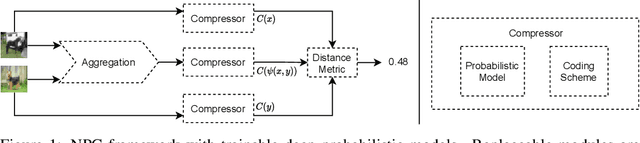
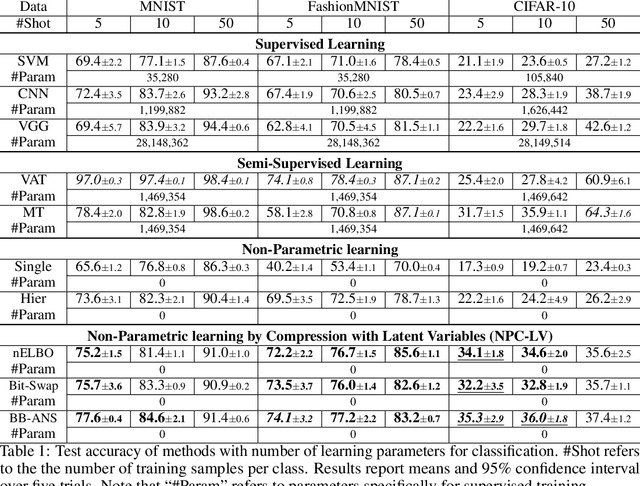
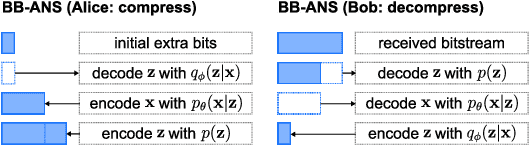
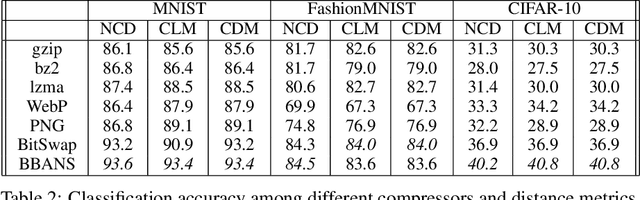
Most real-world problems that machine learning algorithms are expected to solve face the situation with 1) unknown data distribution; 2) little domain-specific knowledge; and 3) datasets with limited annotation. We propose Non-Parametric learning by Compression with Latent Variables (NPC-LV), a learning framework for any dataset with abundant unlabeled data but very few labeled ones. By only training a generative model in an unsupervised way, the framework utilizes the data distribution to build a compressor. Using a compressor-based distance metric derived from Kolmogorov complexity, together with few labeled data, NPC-LV classifies without further training. We show that NPC-LV outperforms supervised methods on all three datasets on image classification in low data regime and even outperform semi-supervised learning methods on CIFAR-10. We demonstrate how and when negative evidence lowerbound (nELBO) can be used as an approximate compressed length for classification. By revealing the correlation between compression rate and classification accuracy, we illustrate that under NPC-LV, the improvement of generative models can enhance downstream classification accuracy.
Certified Error Control of Candidate Set Pruning for Two-Stage Relevance Ranking
May 19, 2022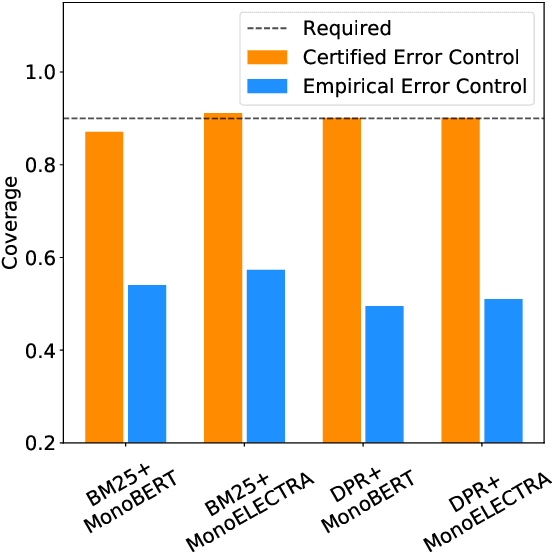

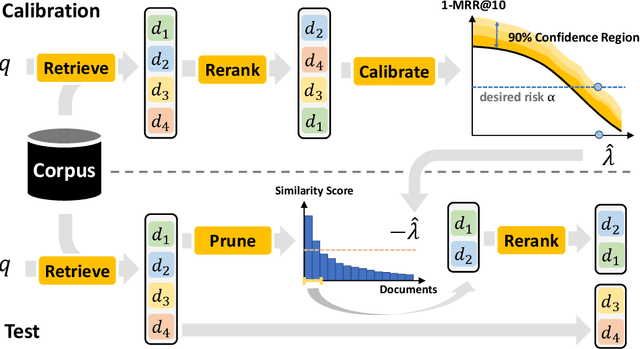
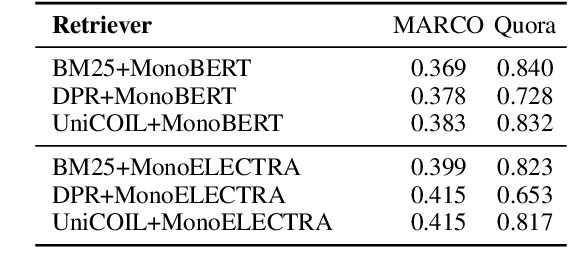
In information retrieval (IR), candidate set pruning has been commonly used to speed up two-stage relevance ranking. However, such an approach lacks accurate error control and often trades accuracy off against computational efficiency in an empirical fashion, lacking theoretical guarantees. In this paper, we propose the concept of certified error control of candidate set pruning for relevance ranking, which means that the test error after pruning is guaranteed to be controlled under a user-specified threshold with high probability. Both in-domain and out-of-domain experiments show that our method successfully prunes the first-stage retrieved candidate sets to improve the second-stage reranking speed while satisfying the pre-specified accuracy constraints in both settings. For example, on MS MARCO Passage v1, our method yields an average candidate set size of 27 out of 1,000 which increases the reranking speed by about 37 times, while the MRR@10 is greater than a pre-specified value of 0.38 with about 90% empirical coverage and the empirical baselines fail to provide such guarantee. Code and data are available at: https://github.com/alexlimh/CEC-Ranking.
Zero-Shot Dense Retrieval with Momentum Adversarial Domain Invariant Representations
Oct 14, 2021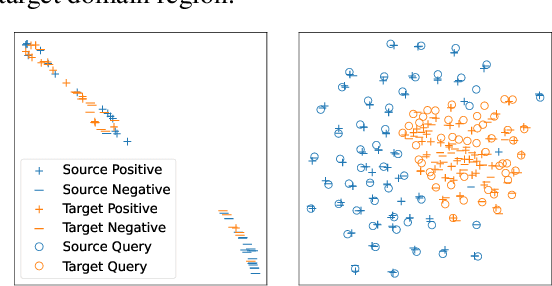
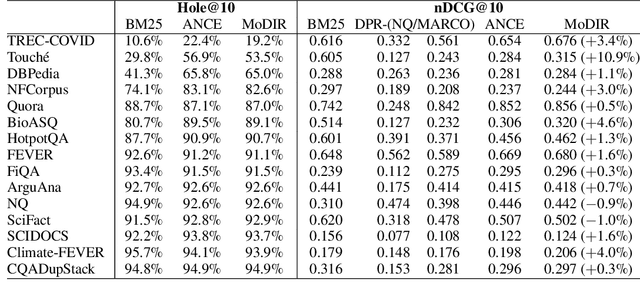
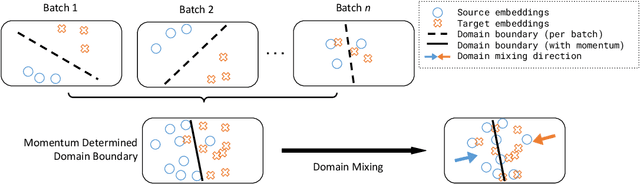

Dense retrieval (DR) methods conduct text retrieval by first encoding texts in the embedding space and then matching them by nearest neighbor search. This requires strong locality properties from the representation space, i.e, the close allocations of each small group of relevant texts, which are hard to generalize to domains without sufficient training data. In this paper, we aim to improve the generalization ability of DR models from source training domains with rich supervision signals to target domains without any relevant labels, in the zero-shot setting. To achieve that, we propose Momentum adversarial Domain Invariant Representation learning (MoDIR), which introduces a momentum method in the DR training process to train a domain classifier distinguishing source versus target, and then adversarially updates the DR encoder to learn domain invariant representations. Our experiments show that MoDIR robustly outperforms its baselines on 10+ ranking datasets from the BEIR benchmark in the zero-shot setup, with more than 10% relative gains on datasets with enough sensitivity for DR models' evaluation. Source code of this paper will be released.
Inserting Information Bottlenecks for Attribution in Transformers
Dec 27, 2020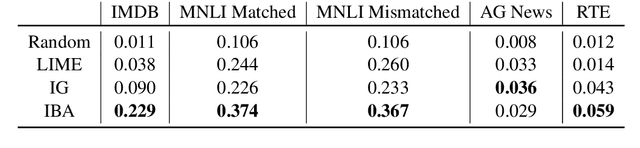
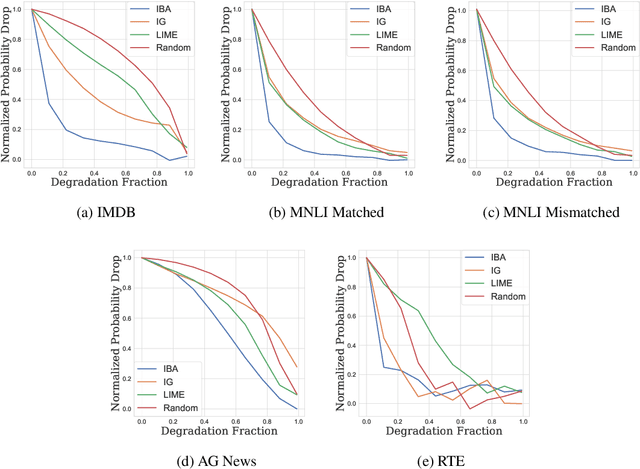
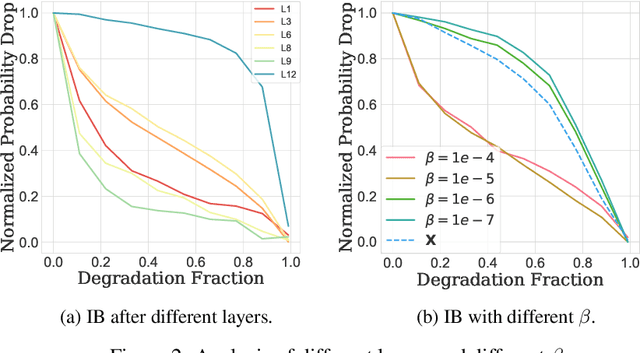
Pretrained transformers achieve the state of the art across tasks in natural language processing, motivating researchers to investigate their inner mechanisms. One common direction is to understand what features are important for prediction. In this paper, we apply information bottlenecks to analyze the attribution of each feature for prediction on a black-box model. We use BERT as the example and evaluate our approach both quantitatively and qualitatively. We show the effectiveness of our method in terms of attribution and the ability to provide insight into how information flows through layers. We demonstrate that our technique outperforms two competitive methods in degradation tests on four datasets. Code is available at https://github.com/bazingagin/IBA.
Showing Your Work Doesn't Always Work
Apr 28, 2020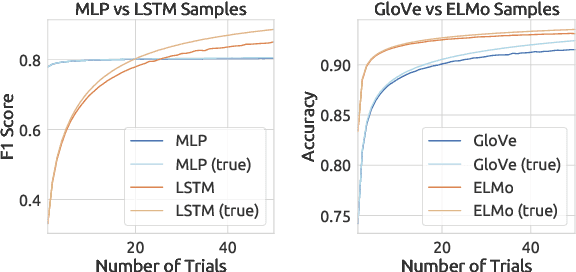

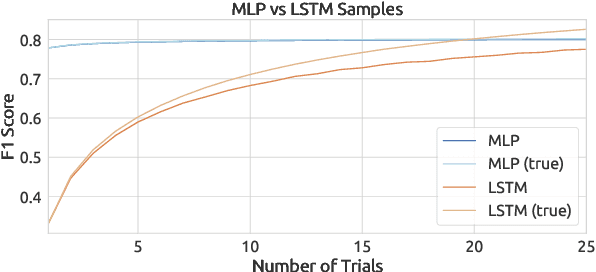
In natural language processing, a recently popular line of work explores how to best report the experimental results of neural networks. One exemplar publication, titled "Show Your Work: Improved Reporting of Experimental Results," advocates for reporting the expected validation effectiveness of the best-tuned model, with respect to the computational budget. In the present work, we critically examine this paper. As far as statistical generalizability is concerned, we find unspoken pitfalls and caveats with this approach. We analytically show that their estimator is biased and uses error-prone assumptions. We find that the estimator favors negative errors and yields poor bootstrapped confidence intervals. We derive an unbiased alternative and bolster our claims with empirical evidence from statistical simulation. Our codebase is at http://github.com/castorini/meanmax.
DeeBERT: Dynamic Early Exiting for Accelerating BERT Inference
Apr 27, 2020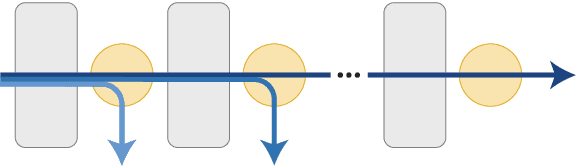
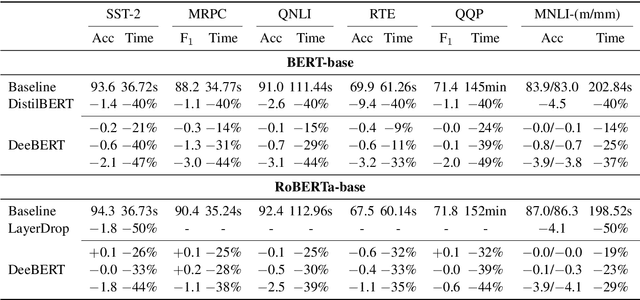
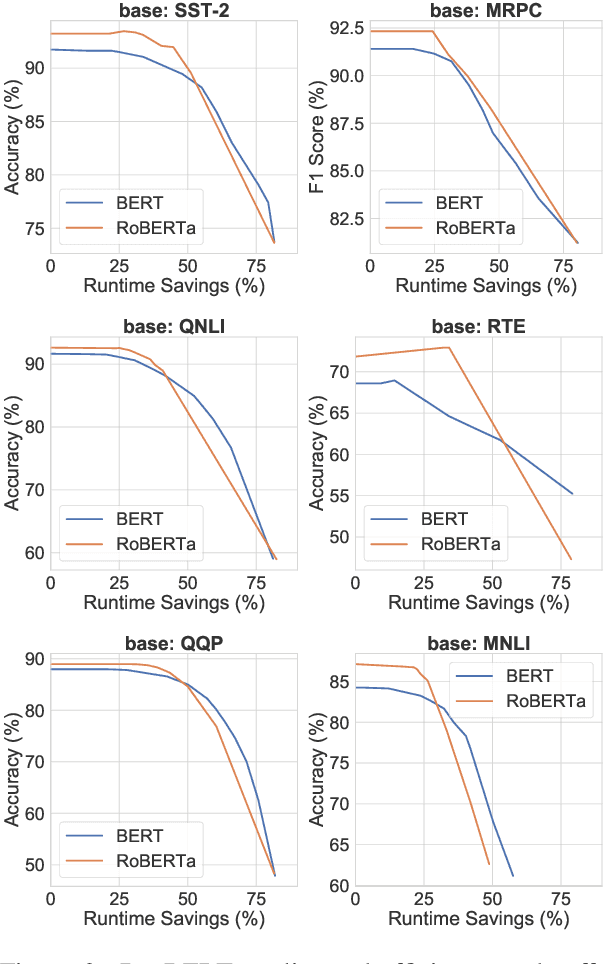
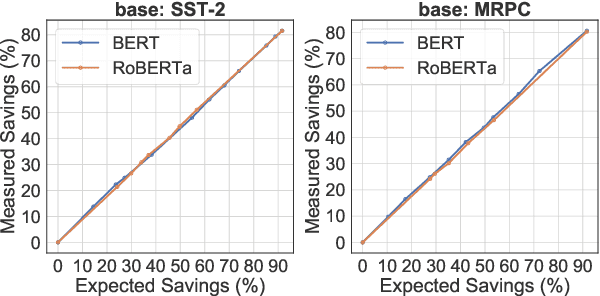
Large-scale pre-trained language models such as BERT have brought significant improvements to NLP applications. However, they are also notorious for being slow in inference, which makes them difficult to deploy in real-time applications. We propose a simple but effective method, DeeBERT, to accelerate BERT inference. Our approach allows samples to exit earlier without passing through the entire model. Experiments show that DeeBERT is able to save up to ~40% inference time with minimal degradation in model quality. Further analyses show different behaviors in the BERT transformer layers and also reveal their redundancy. Our work provides new ideas to efficiently apply deep transformer-based models to downstream tasks. Code is available at https://github.com/castorini/DeeBERT.
Exploiting Token and Path-based Representations of Code for Identifying Security-Relevant Commits
Nov 15, 2019
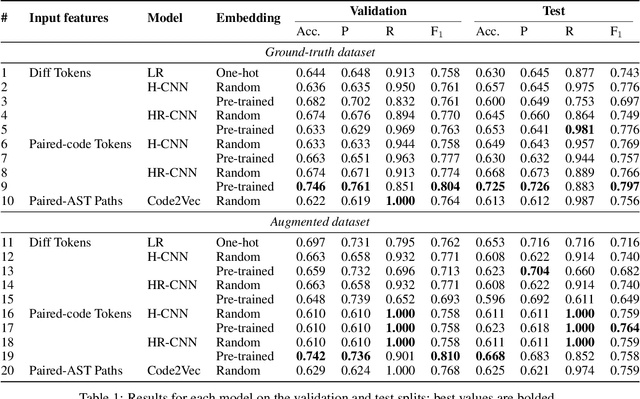
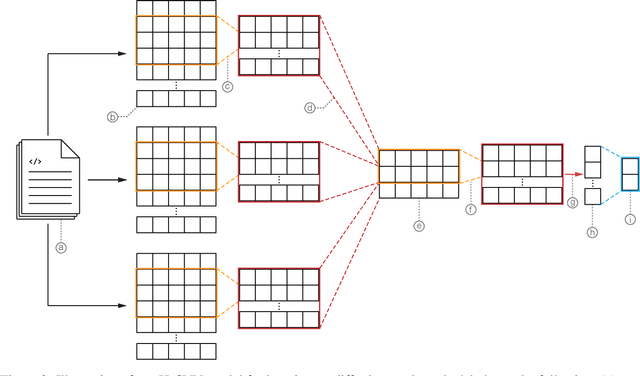
Public vulnerability databases such as CVE and NVD account for only 60% of security vulnerabilities present in open-source projects, and are known to suffer from inconsistent quality. Over the last two years, there has been considerable growth in the number of known vulnerabilities across projects available in various repositories such as NPM and Maven Central. Such an increasing risk calls for a mechanism to infer the presence of security threats in a timely manner. We propose novel hierarchical deep learning models for the identification of security-relevant commits from either the commit diff or the source code for the Java classes. By comparing the performance of our model against code2vec, a state-of-the-art model that learns from path-based representations of code, and a logistic regression baseline, we show that deep learning models show promising results in identifying security-related commits. We also conduct a comparative analysis of how various deep learning models learn across different input representations and the effect of regularization on the generalization of our models.