 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreference Heads in Large Language Models: A Mechanistic Framework for Interpretable Personalization
Apr 24, 2026Large Language Models (LLMs) exhibit strong implicit personalization ability, yet most existing approaches treat this behavior as a black box, relying on prompt engineering or fine tuning on user data. In this work, we adopt a mechanistic interpretability perspective and hypothesize the existence of a sparse set of Preference Heads, attention heads that encode user specific stylistic and topical preferences and exert a causal influence on generation. We introduce Differential Preference Steering (DPS), a training free framework that (1) identifies Preference Heads through causal masking analysis and (2) leverages them for controllable and interpretable personalization at inference time. DPS computes a Preference Contribution Score (PCS) for each attention head, directly measuring its causal impact on user aligned outputs. During decoding, we contrast model predictions with and without Preference Heads, amplifying the difference between personalized and generic logits to selectively strengthen preference aligned continuations. Experiments on widely used personalization benchmarks across multiple LLMs demonstrate consistent gains in personalization fidelity while preserving content coherence and low computational overhead. Beyond empirical improvements, DPS provides a mechanistic explanation of where and how personalization emerges within transformer architectures. Our implementation is publicly available.
LLM Safety From Within: Detecting Harmful Content with Internal Representations
Apr 20, 2026Guard models are widely used to detect harmful content in user prompts and LLM responses. However, state-of-the-art guard models rely solely on terminal-layer representations and overlook the rich safety-relevant features distributed across internal layers. We present SIREN, a lightweight guard model that harnesses these internal features. By identifying safety neurons via linear probing and combining them through an adaptive layer-weighted strategy, SIREN builds a harmfulness detector from LLM internals without modifying the underlying model. Our comprehensive evaluation shows that SIREN substantially outperforms state-of-the-art open-source guard models across multiple benchmarks while using 250 times fewer trainable parameters. Moreover, SIREN exhibits superior generalization to unseen benchmarks, naturally enables real-time streaming detection, and significantly improves inference efficiency compared to generative guard models. Overall, our results highlight LLM internal states as a promising foundation for practical, high-performance harmfulness detection.
Optimizing User Profiles via Contextual Bandits for Retrieval-Augmented LLM Personalization
Jan 17, 2026Large Language Models (LLMs) excel at general-purpose tasks, yet adapting their responses to individual users remains challenging. Retrieval augmentation provides a lightweight alternative to fine-tuning by conditioning LLMs on user history records, and existing approaches typically select these records based on semantic relevance. We argue that relevance serves as an unreliable proxy for utility: a record may be semantically similar to a query yet fail to improve generation quality or even degrade it due to redundancy or conflicting information. To bridge this gap, we propose PURPLE, a contextual bandit framework that oPtimizes UseR Profiles for Llm pErsonalization. In contrast to a greedy selection of the most relevant records, PURPLE treats profile construction as a set generation process and utilizes a Plackett-Luce ranking model to capture complex inter-record dependencies. By training with dense feedback provided by the likelihood of the reference response, our method aligns retrieval directly with generation quality. Extensive experiments on nine personalization tasks demonstrate that PURPLE consistently outperforms strong heuristic and retrieval-augmented baselines in both effectiveness and efficiency, establishing a principled and scalable solution for optimizing user profiles.
DAPO: Design Structure-Aware Pass Ordering in High-Level Synthesis with Graph Contrastive and Reinforcement Learning
Dec 12, 2025High-Level Synthesis (HLS) tools are widely adopted in FPGA-based domain-specific accelerator design. However, existing tools rely on fixed optimization strategies inherited from software compilations, limiting their effectiveness. Tailoring optimization strategies to specific designs requires deep semantic understanding, accurate hardware metric estimation, and advanced search algorithms -- capabilities that current approaches lack. We propose DAPO, a design structure-aware pass ordering framework that extracts program semantics from control and data flow graphs, employs contrastive learning to generate rich embeddings, and leverages an analytical model for accurate hardware metric estimation. These components jointly guide a reinforcement learning agent to discover design-specific optimization strategies. Evaluations on classic HLS designs demonstrate that our end-to-end flow delivers a 2.36 speedup over Vitis HLS on average.
Timing is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS
Apr 09, 2024



One of the primary challenges impeding the progress of Neural Architecture Search (NAS) is its extensive reliance on exorbitant computational resources. NAS benchmarks aim to simulate runs of NAS experiments at zero cost, remediating the need for extensive compute. However, existing NAS benchmarks use synthetic datasets and model proxies that make simplified assumptions about the characteristics of these datasets and models, leading to unrealistic evaluations. We present a technique that allows searching for training proxies that reduce the cost of benchmark construction by significant margins, making it possible to construct realistic NAS benchmarks for large-scale datasets. Using this technique, we construct an open-source bi-objective NAS benchmark for the ImageNet2012 dataset combined with the on-device performance of accelerators, including GPUs, TPUs, and FPGAs. Through extensive experimentation with various NAS optimizers and hardware platforms, we show that the benchmark is accurate and allows searching for state-of-the-art hardware-aware models at zero cost.
MultiResFormer: Transformer with Adaptive Multi-Resolution Modeling for General Time Series Forecasting
Nov 30, 2023



Transformer-based models have greatly pushed the boundaries of time series forecasting recently. Existing methods typically encode time series data into $\textit{patches}$ using one or a fixed set of patch lengths. This, however, could result in a lack of ability to capture the variety of intricate temporal dependencies present in real-world multi-periodic time series. In this paper, we propose MultiResFormer, which dynamically models temporal variations by adaptively choosing optimal patch lengths. Concretely, at the beginning of each layer, time series data is encoded into several parallel branches, each using a detected periodicity, before going through the transformer encoder block. We conduct extensive evaluations on long- and short-term forecasting datasets comparing MultiResFormer with state-of-the-art baselines. MultiResFormer outperforms patch-based Transformer baselines on long-term forecasting tasks and also consistently outperforms CNN baselines by a large margin, while using much fewer parameters than these baselines.
Mobile APP User Attribute Prediction by Heterogeneous Information Network Modeling
Oct 06, 2019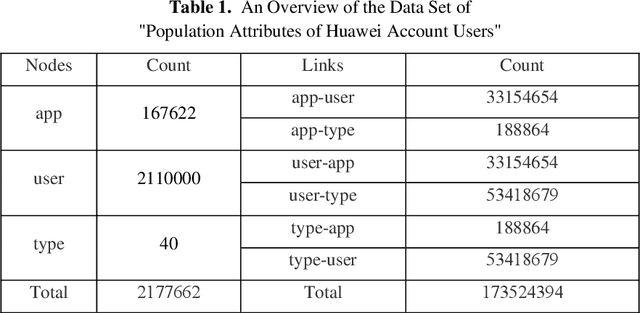
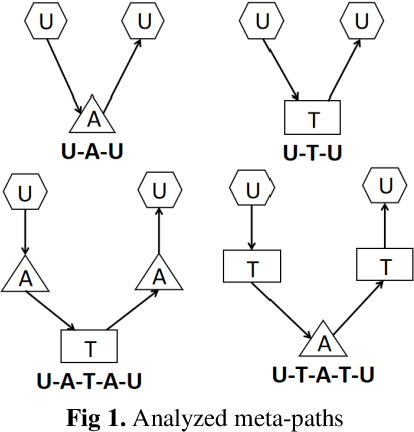
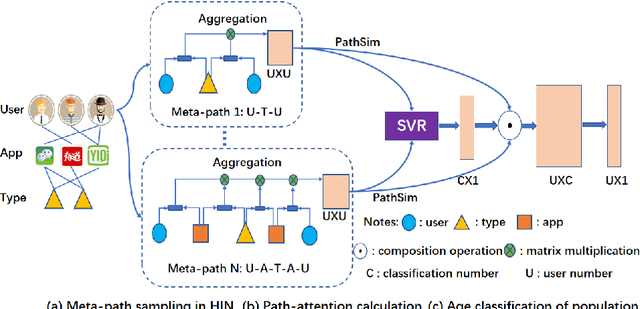
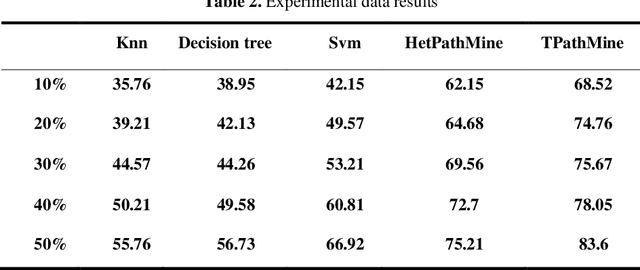
User-based attribute information, such as age and gender, is usually considered as user privacy information. It is difficult for enterprises to obtain user-based privacy attribute information. However, user-based privacy attribute information has a wide range of applications in personalized services, user behavior analysis and other aspects. this paper advances the HetPathMine model and puts forward TPathMine model. With applying the number of clicks of attributes under each node to express the user's emotional preference information, optimizations of the solution of meta-path weight are also presented. Based on meta-path in heterogeneous information networks, the new model integrates all relationships among objects into isomorphic relationships of classified objects. Matrix is used to realize the knowledge dissemination of category knowledge among isomorphic objects. The experimental results show that: (1) the prediction of user attributes based on heterogeneous information networks can achieve higher accuracy than traditional machine learning classification methods; (2) TPathMine model based on the number of clicks is more accurate in classifying users of different age groups, and the weight of each meta-path is consistent with human intuition or the real world situation.