 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRTL-BenchLS: A Large-Scale Benchmark for RTL Reasoning and Generation with Large Language Models
Jun 08, 2026LLM-based RTL generation and reasoning is a promising direction for hardware design automation. High-quality benchmarks are critical infrastructure for tracking progress in this direction. However, existing RTL benchmarks face inherent limitations in both scale and task scope. The designs they cover are typically small and simple, and the tasks focus almost entirely on specification-to-RTL generation. Frontier models' performance already saturates on the existing benchmarks. Scaling these benchmarks up is fundamentally difficult because aligned labels are required for benchmarking, such as specifications and testbenches. Such aligned high-quality data are rarely available for real-world designs. We introduce RTL-BenchLS, a large-scale benchmark addressing both limitations above. It contains over 10,000 formally verified Verilog designs, covering substantially larger and more complex designs than existing benchmarks. Beyond specification-to-RTL generation, we propose three novel tasks that jointly evaluate reasoning and generation: round-trip reasoning, masked-content reasoning, and repository-issue reasoning. The first two are self-supervised, which directly resolves the scaling bottleneck. All tasks are verified through formal equivalence checking without any manual testbenches. We evaluate eight LLMs on RTL-BenchLS. Even the best model reaches only 23% on natural-language round-trip reasoning, 28% on masked-content reasoning, and 12% on repository-issue fixing. RTL-BenchLS is substantially more challenging than existing benchmarks. It leaves ample room for future improvement and offers guidance for developing LLM-based methods for hardware design.
AssertLLM2: A Comprehensive LLM Benchmark for Assertion Generation from Design Specifications
May 26, 2026Assertion-based verification (ABV) is a cornerstone of modern hardware design, yet manually translating design intent into formal SystemVerilog Assertions (SVAs) remains labor-intensive and error-prone. While Large Language Models (LLMs) show promise for automating this process, existing benchmarks remain limited by unrealistic task formulations, weak specification inputs, and oversimplified evaluation. To address these limitations, we introduce AssertLLM2, an open-source benchmark for realistic assertion generation in hardware verification. AssertLLM2 contains 83 real-world designs across 13 functional categories. For each design, the benchmark provides a structured design specification, a verified dependency-complete golden RTL, and systematically mutated buggy RTL variants. These support two practical settings: bug-prevention, where assertions are generated from specifications to guard against design errors, and bug-hunting, where assertions are generated to expose discrepancies between intended behavior and faulty implementations. To the best of our knowledge, AssertLLM2 is the first benchmark to explicitly use buggy RTL as input to evaluate bug-detection capability. AssertLLM2 further adopts a more rigorous evaluation framework spanning syntactic validity, formal provability, coverage, and mutation-based bug detection. Our benchmark enables a more realistic and extensive assessment of assertion generation and establishes rigorous baselines for state-of-the-art LLMs in practical hardware verification.
Dr.~RTL: Autonomous Agentic RTL Optimization through Tool-Grounded Self-Improvement
Apr 16, 2026Recent advances in large language models (LLMs) have sparked growing interest in automatic RTL optimization for better performance, power, and area (PPA). However, existing methods are still far from realistic RTL optimization. Their evaluation settings are often unrealistic: they are tested on manually degraded, small-scale RTL designs and rely on weak open-source tools. Their optimization methods are also limited, relying on coarse design-level feedback and simple pre-defined rewriting rules. To address these limitations, we present Dr. RTL, an agentic framework for RTL timing optimization in a realistic evaluation environment, with continual self-improvement through reusable optimization skills. We establish a realistic evaluation setting with more challenging RTL designs and an industrial EDA workflow. Within this setting, Dr. RTL performs closed-loop optimization through a multi-agent framework for critical-path analysis, parallel RTL rewriting, and tool-based evaluation. We further introduce group-relative skill learning, which compares parallel RTL rewrites and distills the optimization experience into an interpretable skill library. Currently, this library contains 47 pattern--strategy entries for cross-design reuse to improve PPA and accelerate convergence, and it can continue evolving over time. Evaluated on 20 real-world RTL designs, Dr. RTL achieves average WNS/TNS improvements of 21\%/17\% with a 6\% area reduction over the industry-leading commercial synthesis tool.
A New Benchmark for the Appropriate Evaluation of RTL Code Optimization
Jan 05, 2026The rapid progress of artificial intelligence increasingly relies on efficient integrated circuit (IC) design. Recent studies have explored the use of large language models (LLMs) for generating Register Transfer Level (RTL) code, but existing benchmarks mainly evaluate syntactic correctness rather than optimization quality in terms of power, performance, and area (PPA). This work introduces RTL-OPT, a benchmark for assessing the capability of LLMs in RTL optimization. RTL-OPT contains 36 handcrafted digital designs that cover diverse implementation categories including combinational logic, pipelined datapaths, finite state machines, and memory interfaces. Each task provides a pair of RTL codes, a suboptimal version and a human-optimized reference that reflects industry-proven optimization patterns not captured by conventional synthesis tools. Furthermore, RTL-OPT integrates an automated evaluation framework to verify functional correctness and quantify PPA improvements, enabling standardized and meaningful assessment of generative models for hardware design optimization.
DAPO: Design Structure-Aware Pass Ordering in High-Level Synthesis with Graph Contrastive and Reinforcement Learning
Dec 12, 2025High-Level Synthesis (HLS) tools are widely adopted in FPGA-based domain-specific accelerator design. However, existing tools rely on fixed optimization strategies inherited from software compilations, limiting their effectiveness. Tailoring optimization strategies to specific designs requires deep semantic understanding, accurate hardware metric estimation, and advanced search algorithms -- capabilities that current approaches lack. We propose DAPO, a design structure-aware pass ordering framework that extracts program semantics from control and data flow graphs, employs contrastive learning to generate rich embeddings, and leverages an analytical model for accurate hardware metric estimation. These components jointly guide a reinforcement learning agent to discover design-specific optimization strategies. Evaluations on classic HLS designs demonstrate that our end-to-end flow delivers a 2.36 speedup over Vitis HLS on average.
ELF: Efficient Logic Synthesis by Pruning Redundancy in Refactoring
Aug 11, 2025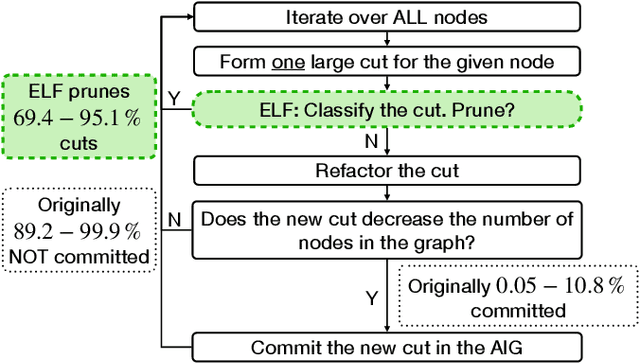
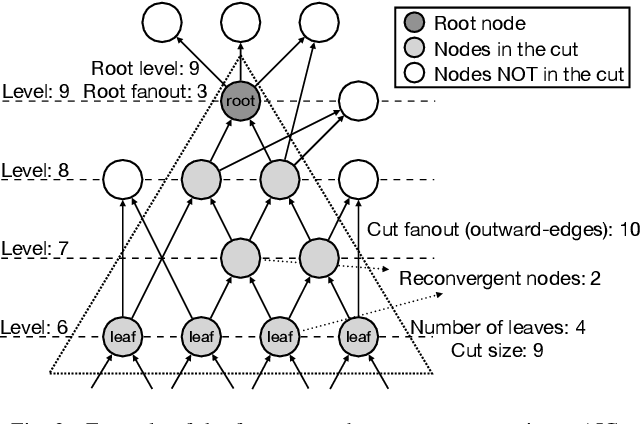
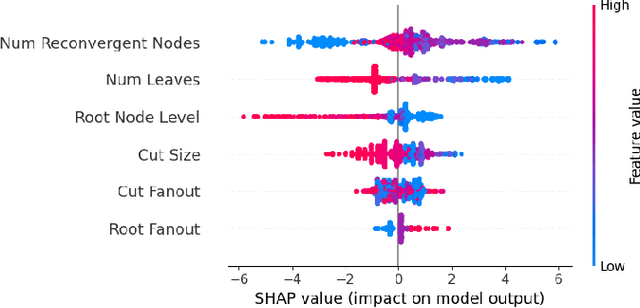
In electronic design automation, logic optimization operators play a crucial role in minimizing the gate count of logic circuits. However, their computation demands are high. Operators such as refactor conventionally form iterative cuts for each node, striving for a more compact representation - a task which often fails 98% on average. Prior research has sought to mitigate computational cost through parallelization. In contrast, our approach leverages a classifier to prune unsuccessful cuts preemptively, thus eliminating unnecessary resynthesis operations. Experiments on the refactor operator using the EPFL benchmark suite and 10 large industrial designs demonstrate that this technique can speedup logic optimization by 3.9x on average compared with the state-of-the-art ABC implementation.
GenEDA: Unleashing Generative Reasoning on Netlist via Multimodal Encoder-Decoder Aligned Foundation Model
Apr 13, 2025



The success of foundation AI has motivated the research of circuit foundation models, which are customized to assist the integrated circuit (IC) design process. However, existing pre-trained circuit models are typically limited to standalone encoders for predictive tasks or decoders for generative tasks. These two model types are developed independently, operate on different circuit modalities, and reside in separate latent spaces, which restricts their ability to complement each other for more advanced applications. In this work, we present GenEDA, the first framework that aligns circuit encoders with decoders within a shared latent space. GenEDA bridges the gap between graph-based circuit representations and text-based large language models (LLMs), enabling communication between their respective latent spaces. To achieve the alignment, we propose two paradigms that support both open-source trainable LLMs and commercial frozen LLMs. Built on this aligned architecture, GenEDA enables three unprecedented generative reasoning tasks over netlists, where the model reversely generates the high-level functionality from low-level netlists in different granularities. These tasks extend traditional gate-type prediction to direct generation of full-circuit functionality. Experiments demonstrate that GenEDA significantly boosts advanced LLMs' (e.g., GPT-4o and DeepSeek-V3) performance in all tasks.
NetTAG: A Multimodal RTL-and-Layout-Aligned Netlist Foundation Model via Text-Attributed Graph
Apr 12, 2025



Circuit representation learning has shown promise in advancing Electronic Design Automation (EDA) by capturing structural and functional circuit properties for various tasks. Existing pre-trained solutions rely on graph learning with complex functional supervision, such as truth table simulation. However, they only handle simple and-inverter graphs (AIGs), struggling to fully encode other complex gate functionalities. While large language models (LLMs) excel at functional understanding, they lack the structural awareness for flattened netlists. To advance netlist representation learning, we present NetTAG, a netlist foundation model that fuses gate semantics with graph structure, handling diverse gate types and supporting a variety of functional and physical tasks. Moving beyond existing graph-only methods, NetTAG formulates netlists as text-attributed graphs, with gates annotated by symbolic logic expressions and physical characteristics as text attributes. Its multimodal architecture combines an LLM-based text encoder for gate semantics and a graph transformer for global structure. Pre-trained with gate and graph self-supervised objectives and aligned with RTL and layout stages, NetTAG captures comprehensive circuit intrinsics. Experimental results show that NetTAG consistently outperforms each task-specific method on four largely different functional and physical tasks and surpasses state-of-the-art AIG encoders, demonstrating its versatility.
ShortCircuit: AlphaZero-Driven Circuit Design
Aug 19, 2024



Chip design relies heavily on generating Boolean circuits, such as AND-Inverter Graphs (AIGs), from functional descriptions like truth tables. While recent advances in deep learning have aimed to accelerate circuit design, these efforts have mostly focused on tasks other than synthesis, and traditional heuristic methods have plateaued. In this paper, we introduce ShortCircuit, a novel transformer-based architecture that leverages the structural properties of AIGs and performs efficient space exploration. Contrary to prior approaches attempting end-to-end generation of logic circuits using deep networks, ShortCircuit employs a two-phase process combining supervised with reinforcement learning to enhance generalization to unseen truth tables. We also propose an AlphaZero variant to handle the double exponentially large state space and the sparsity of the rewards, enabling the discovery of near-optimal designs. To evaluate the generative performance of our trained model , we extract 500 truth tables from a benchmark set of 20 real-world circuits. ShortCircuit successfully generates AIGs for 84.6% of the 8-input test truth tables, and outperforms the state-of-the-art logic synthesis tool, ABC, by 14.61% in terms of circuits size.
Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS
Apr 09, 2024



One of the primary challenges impeding the progress of Neural Architecture Search (NAS) is its extensive reliance on exorbitant computational resources. NAS benchmarks aim to simulate runs of NAS experiments at zero cost, remediating the need for extensive compute. However, existing NAS benchmarks use synthetic datasets and model proxies that make simplified assumptions about the characteristics of these datasets and models, leading to unrealistic evaluations. We present a technique that allows searching for training proxies that reduce the cost of benchmark construction by significant margins, making it possible to construct realistic NAS benchmarks for large-scale datasets. Using this technique, we construct an open-source bi-objective NAS benchmark for the ImageNet2012 dataset combined with the on-device performance of accelerators, including GPUs, TPUs, and FPGAs. Through extensive experimentation with various NAS optimizers and hardware platforms, we show that the benchmark is accurate and allows searching for state-of-the-art hardware-aware models at zero cost.