 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and Principled Scientific Discovery through Bayesian Optimization: A Tutorial
Apr 01, 2026Traditional scientific discovery relies on an iterative hypothesise-experiment-refine cycle that has driven progress for centuries, but its intuitive, ad-hoc implementation often wastes resources, yields inefficient designs, and misses critical insights. This tutorial presents Bayesian Optimisation (BO), a principled probability-driven framework that formalises and automates this core scientific cycle. BO uses surrogate models (e.g., Gaussian processes) to model empirical observations as evolving hypotheses, and acquisition functions to guide experiment selection, balancing exploitation of known knowledge and exploration of uncharted domains to eliminate guesswork and manual trial-and-error. We first frame scientific discovery as an optimisation problem, then unpack BO's core components, end-to-end workflows, and real-world efficacy via case studies in catalysis, materials science, organic synthesis, and molecule discovery. We also cover critical technical extensions for scientific applications, including batched experimentation, heteroscedasticity, contextual optimisation, and human-in-the-loop integration. Tailored for a broad audience, this tutorial bridges AI advances in BO with practical natural science applications, offering tiered content to empower cross-disciplinary researchers to design more efficient experiments and accelerate principled scientific discovery.
The $\mathbf{Y}$-Combinator for LLMs: Solving Long-Context Rot with $λ$-Calculus
Mar 20, 2026LLMs are increasingly used as general-purpose reasoners, but long inputs remain bottlenecked by a fixed context window. Recursive Language Models (RLMs) address this by externalising the prompt and recursively solving subproblems. Yet existing RLMs depend on an open-ended read-eval-print loop (REPL) in which the model generates arbitrary control code, making execution difficult to verify, predict, and analyse. We introduce $λ$-RLM, a framework for long-context reasoning that replaces free-form recursive code generation with a typed functional runtime grounded in $λ$-calculus. It executes a compact library of pre-verified combinators and uses neural inference only on bounded leaf subproblems, turning recursive reasoning into a structured functional program with explicit control flow. We show that $λ$-RLM admits formal guarantees absent from standard RLMs, including termination, closed-form cost bounds, controlled accuracy scaling with recursion depth, and an optimal partition rule under a simple cost model. Empirically, across four long-context reasoning tasks and nine base models, $λ$-RLM outperforms standard RLM in 29 of 36 model-task comparisons, improves average accuracy by up to +21.9 points across model tiers, and reduces latency by up to 4.1x. These results show that typed symbolic control yields a more reliable and efficient foundation for long-context reasoning than open-ended recursive code generation. The complete implementation of $λ$-RLM, is open-sourced for the community at: https://github.com/lambda-calculus-LLM/lambda-RLM.
Why the Brain Consolidates: Predictive Forgetting for Optimal Generalisation
Mar 05, 2026Standard accounts of memory consolidation emphasise the stabilisation of stored representations, but struggle to explain representational drift, semanticisation, or the necessity of offline replay. Here we propose that high-capacity neocortical networks optimise stored representations for generalisation by reducing complexity via predictive forgetting, i.e. the selective retention of experienced information that predicts future outcomes or experience. We show that predictive forgetting formally improves information-theoretic generalisation bounds on stored representations. Under high-fidelity encoding constraints, such compression is generally unattainable in a single pass; high-capacity networks therefore benefit from temporally separated, iterative refinement of stored traces without re-accessing sensory input. We demonstrate this capacity dependence with simulations in autoencoder-based neocortical models, biologically plausible predictive coding circuits, and Transformer-based language models, and derive quantitative predictions for consolidation-dependent changes in neural representational geometry. These results identify a computational role for off-line consolidation beyond stabilisation, showing that outcome-conditioned compression optimises the retention-generalisation trade-off.
A Brain-like Synergistic Core in LLMs Drives Behaviour and Learning
Jan 11, 2026The independent evolution of intelligence in biological and artificial systems offers a unique opportunity to identify its fundamental computational principles. Here we show that large language models spontaneously develop synergistic cores -- components where information integration exceeds individual parts -- remarkably similar to those in the human brain. Using principles of information decomposition across multiple LLM model families and architectures, we find that areas in middle layers exhibit synergistic processing while early and late layers rely on redundancy, mirroring the informational organisation in biological brains. This organisation emerges through learning and is absent in randomly initialised networks. Crucially, ablating synergistic components causes disproportionate behavioural changes and performance loss, aligning with theoretical predictions about the fragility of synergy. Moreover, fine-tuning synergistic regions through reinforcement learning yields significantly greater performance gains than training redundant components, yet supervised fine-tuning shows no such advantage. This convergence suggests that synergistic information processing is a fundamental property of intelligence, providing targets for principled model design and testable predictions for biological intelligence.
Data-driven Interpretable Hybrid Robot Dynamics
Dec 10, 2025We study data-driven identification of interpretable hybrid robot dynamics, where an analytical rigid-body dynamics model is complemented by a learned residual torque term. Using symbolic regression and sparse identification of nonlinear dynamics (SINDy), we recover compact closed-form expressions for this residual from joint-space data. In simulation on a 7-DoF Franka arm with known dynamics, these interpretable models accurately recover inertial, Coriolis, gravity, and viscous effects with very small relative error and outperform neural-network baselines in both accuracy and generalization. On real data from a 7-DoF WAM arm, symbolic-regression residuals generalize substantially better than SINDy and neural networks, which tend to overfit, and suggest candidate new closed-form formulations that extend the nominal dynamics model for this robot. Overall, the results indicate that interpretable residual dynamics models provide compact, accurate, and physically meaningful alternatives to black-box function approximators for torque prediction.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
Experience is the Best Teacher: Grounding VLMs for Robotics through Self-Generated Memory
Jul 22, 2025Vision-language models (VLMs) have been widely adopted in robotics to enable autonomous planning. However, grounding VLMs, originally trained on internet data, to diverse real-world robots remains a challenge. This paper presents ExpTeach, a framework that grounds VLMs to physical robots by building a self-generated memory of real-world experiences. In ExpTeach, the VLM autonomously plans actions, verifies outcomes, reflects on failures, and adapts robot behaviors in a closed loop. The self-generated experiences during this process are then summarized into a long-term memory, enabling retrieval of learned knowledge to guide future tasks via retrieval-augmented generation (RAG). Additionally, ExpTeach enhances the spatial understanding of VLMs with an on-demand image annotation module. In experiments, we show that reflection improves success rates from 36% to 84% on four challenging robotic tasks and observe the emergence of intelligent object interactions, including creative tool use. Across extensive tests on 12 real-world scenarios (including eight unseen ones), we find that grounding with long-term memory boosts single-trial success rates from 22% to 80%, demonstrating the effectiveness and generalizability of ExpTeach.
Bottlenecked Transformers: Periodic KV Cache Abstraction for Generalised Reasoning
May 22, 2025Despite their impressive capabilities, Large Language Models struggle with generalisation beyond their training distribution, often exhibiting sophisticated pattern interpolation rather than true abstract reasoning (extrapolation). In this work, we approach this limitation through the lens of Information Bottleneck (IB) theory, which posits that model generalisation emerges from an optimal balance between input compression and retention of predictive information in latent representations. We prove using IB theory that decoder-only Transformers are inherently constrained in their ability to form task-optimal sequence representations. We then use this result to demonstrate that periodic global transformation of the internal sequence-level representations (KV cache) is a necessary computational step for improving Transformer generalisation in reasoning tasks. Based on these theoretical insights, we propose a modification to the Transformer architecture, in the form of an additional module that globally rewrites the KV cache at periodic intervals, shifting its capacity away from memorising input prefixes and toward encoding features most useful for predicting future tokens. Our model delivers substantial gains on mathematical reasoning benchmarks, outperforming both vanilla Transformers with up to 3.5x more parameters, as well as heuristic-driven pruning mechanisms for cache compression. Our approach can be seen as a principled generalisation of existing KV-cache compression methods; whereas such methods focus solely on compressing input representations, they often do so at the expense of retaining predictive information, and thus their capabilities are inherently bounded by those of an unconstrained model. This establishes a principled framework to manipulate Transformer memory using information theory, addressing fundamental reasoning limitations that scaling alone cannot overcome.
Al-Khwarizmi: Discovering Physical Laws with Foundation Models
Feb 03, 2025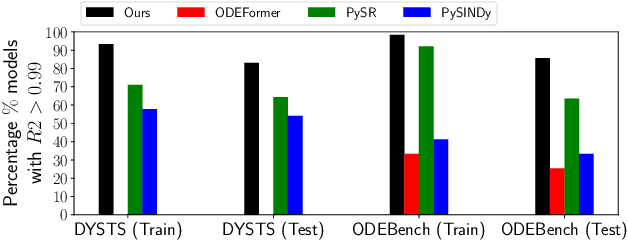



Inferring physical laws from data is a central challenge in science and engineering, including but not limited to healthcare, physical sciences, biosciences, social sciences, sustainability, climate, and robotics. Deep networks offer high-accuracy results but lack interpretability, prompting interest in models built from simple components. The Sparse Identification of Nonlinear Dynamics (SINDy) method has become the go-to approach for building such modular and interpretable models. SINDy leverages sparse regression with L1 regularization to identify key terms from a library of candidate functions. However, SINDy's choice of candidate library and optimization method requires significant technical expertise, limiting its widespread applicability. This work introduces Al-Khwarizmi, a novel agentic framework for physical law discovery from data, which integrates foundational models with SINDy. Leveraging LLMs, VLMs, and Retrieval-Augmented Generation (RAG), our approach automates physical law discovery, incorporating prior knowledge and iteratively refining candidate solutions via reflection. Al-Khwarizmi operates in two steps: it summarizes system observations-comprising textual descriptions, raw data, and plots-followed by a secondary step that generates candidate feature libraries and optimizer configurations to identify hidden physics laws correctly. Evaluating our algorithm on over 198 models, we demonstrate state-of-the-art performance compared to alternatives, reaching a 20 percent increase against the best-performing alternative.
Many of Your DPOs are Secretly One: Attempting Unification Through Mutual Information
Jan 02, 2025Post-alignment of large language models (LLMs) is critical in improving their utility, safety, and alignment with human intentions. Direct preference optimisation (DPO) has become one of the most widely used algorithms for achieving this alignment, given its ability to optimise models based on human feedback directly. However, the vast number of DPO variants in the literature has made it increasingly difficult for researchers to navigate and fully grasp the connections between these approaches. This paper introduces a unifying framework inspired by mutual information, which proposes a new loss function with flexible priors. By carefully specifying these priors, we demonstrate that many existing algorithms, such as SimPO, TDPO, SparsePO, and others, can be derived from our framework. This unification offers a clearer and more structured approach, allowing researchers to understand the relationships between different DPO variants better. We aim to simplify the landscape of DPO algorithms, making it easier for the research community to gain insights and foster further advancements in LLM alignment. Ultimately, we hope our framework can be a foundation for developing more robust and interpretable alignment techniques.