 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic BrailleNet: Accurate and Generalizable Braille Reading Beyond Single Characters through Event-Based Optical Tactile Sensing
Jan 27, 2026Conventional robotic Braille readers typically rely on discrete, character-by-character scanning, limiting reading speed and disrupting natural flow. Vision-based alternatives often require substantial computation, introduce latency, and degrade in real-world conditions. In this work, we present a high accuracy, real-time pipeline for continuous Braille recognition using Evetac, an open-source neuromorphic event-based tactile sensor. Unlike frame-based vision systems, the neuromorphic tactile modality directly encodes dynamic contact events during continuous sliding, closely emulating human finger-scanning strategies. Our approach combines spatiotemporal segmentation with a lightweight ResNet-based classifier to process sparse event streams, enabling robust character recognition across varying indentation depths and scanning speeds. The proposed system achieves near-perfect accuracy (>=98%) at standard depths, generalizes across multiple Braille board layouts, and maintains strong performance under fast scanning. On a physical Braille board containing daily-living vocabulary, the system attains over 90% word-level accuracy, demonstrating robustness to temporal compression effects that challenge conventional methods. These results position neuromorphic tactile sensing as a scalable, low latency solution for robotic Braille reading, with broader implications for tactile perception in assistive and robotic applications.
On the Importance of Tactile Sensing for Imitation Learning: A Case Study on Robotic Match Lighting
Apr 18, 2025The field of robotic manipulation has advanced significantly in the last years. At the sensing level, several novel tactile sensors have been developed, capable of providing accurate contact information. On a methodological level, learning from demonstrations has proven an efficient paradigm to obtain performant robotic manipulation policies. The combination of both holds the promise to extract crucial contact-related information from the demonstration data and actively exploit it during policy rollouts. However, despite its potential, it remains an underexplored direction. This work therefore proposes a multimodal, visuotactile imitation learning framework capable of efficiently learning fast and dexterous manipulation policies. We evaluate our framework on the dynamic, contact-rich task of robotic match lighting - a task in which tactile feedback influences human manipulation performance. The experimental results show that adding tactile information into the policies significantly improves performance by over 40%, thereby underlining the importance of tactile sensing for contact-rich manipulation tasks. Project website: https://sites.google.com/view/tactile-il .
Particle-based 6D Object Pose Estimation from Point Clouds using Diffusion Models
Dec 01, 2024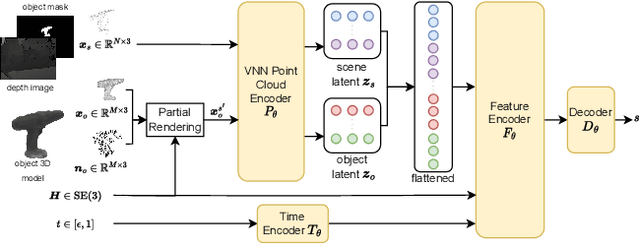


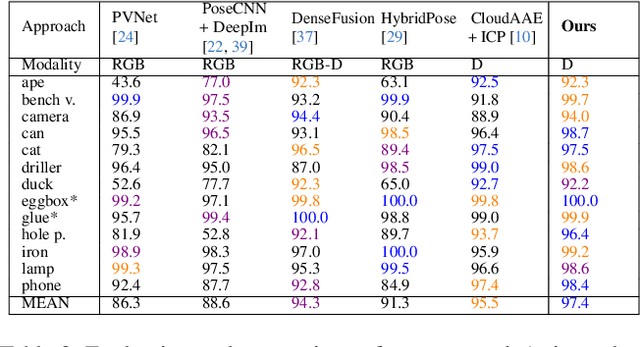
Object pose estimation from a single view remains a challenging problem. In particular, partial observability, occlusions, and object symmetries eventually result in pose ambiguity. To account for this multimodality, this work proposes training a diffusion-based generative model for 6D object pose estimation. During inference, the trained generative model allows for sampling multiple particles, i.e., pose hypotheses. To distill this information into a single pose estimate, we propose two novel and effective pose selection strategies that do not require any additional training or computationally intensive operations. Moreover, while many existing methods for pose estimation primarily focus on the image domain and only incorporate depth information for final pose refinement, our model solely operates on point cloud data. The model thereby leverages recent advancements in point cloud processing and operates upon an SE(3)-equivariant latent space that forms the basis for the particle selection strategies and allows for improved inference times. Our thorough experimental results demonstrate the competitive performance of our approach on the Linemod dataset and showcase the effectiveness of our design choices. Code is available at https://github.com/zitronian/6DPoseDiffusion .
A Retrospective on the Robot Air Hockey Challenge: Benchmarking Robust, Reliable, and Safe Learning Techniques for Real-world Robotics
Nov 08, 2024Machine learning methods have a groundbreaking impact in many application domains, but their application on real robotic platforms is still limited. Despite the many challenges associated with combining machine learning technology with robotics, robot learning remains one of the most promising directions for enhancing the capabilities of robots. When deploying learning-based approaches on real robots, extra effort is required to address the challenges posed by various real-world factors. To investigate the key factors influencing real-world deployment and to encourage original solutions from different researchers, we organized the Robot Air Hockey Challenge at the NeurIPS 2023 conference. We selected the air hockey task as a benchmark, encompassing low-level robotics problems and high-level tactics. Different from other machine learning-centric benchmarks, participants need to tackle practical challenges in robotics, such as the sim-to-real gap, low-level control issues, safety problems, real-time requirements, and the limited availability of real-world data. Furthermore, we focus on a dynamic environment, removing the typical assumption of quasi-static motions of other real-world benchmarks. The competition's results show that solutions combining learning-based approaches with prior knowledge outperform those relying solely on data when real-world deployment is challenging. Our ablation study reveals which real-world factors may be overlooked when building a learning-based solution. The successful real-world air hockey deployment of best-performing agents sets the foundation for future competitions and follow-up research directions.
ActionFlow: Equivariant, Accurate, and Efficient Policies with Spatially Symmetric Flow Matching
Sep 06, 2024



Spatial understanding is a critical aspect of most robotic tasks, particularly when generalization is important. Despite the impressive results of deep generative models in complex manipulation tasks, the absence of a representation that encodes intricate spatial relationships between observations and actions often limits spatial generalization, necessitating large amounts of demonstrations. To tackle this problem, we introduce a novel policy class, ActionFlow. ActionFlow integrates spatial symmetry inductive biases while generating expressive action sequences. On the representation level, ActionFlow introduces an SE(3) Invariant Transformer architecture, which enables informed spatial reasoning based on the relative SE(3) poses between observations and actions. For action generation, ActionFlow leverages Flow Matching, a state-of-the-art deep generative model known for generating high-quality samples with fast inference - an essential property for feedback control. In combination, ActionFlow policies exhibit strong spatial and locality biases and SE(3)-equivariant action generation. Our experiments demonstrate the effectiveness of ActionFlow and its two main components on several simulated and real-world robotic manipulation tasks and confirm that we can obtain equivariant, accurate, and efficient policies with spatially symmetric flow matching. Project website: https://flowbasedpolicies.github.io/
Evetac: An Event-based Optical Tactile Sensor for Robotic Manipulation
Dec 02, 2023
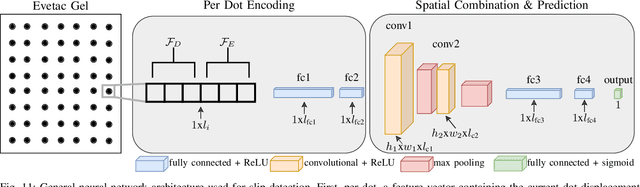
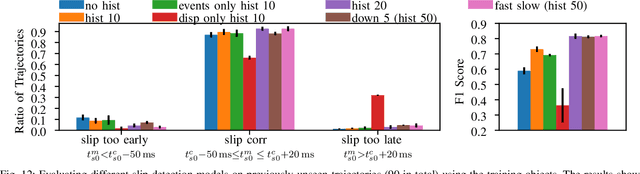
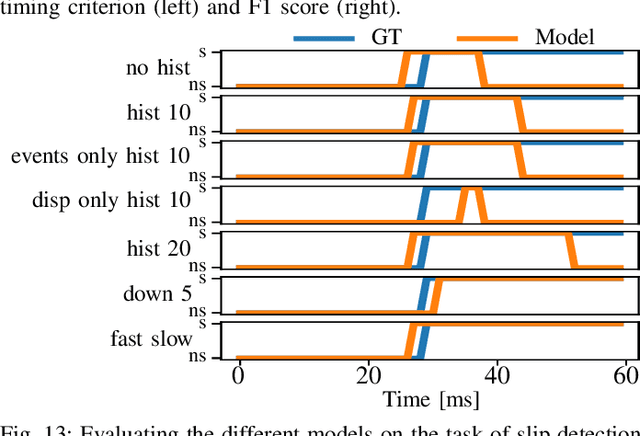
Optical tactile sensors have recently become popular. They provide high spatial resolution, but struggle to offer fine temporal resolutions. To overcome this shortcoming, we study the idea of replacing the RGB camera with an event-based camera and introduce a new event-based optical tactile sensor called Evetac. Along with hardware design, we develop touch processing algorithms to process its measurements online at 1000 Hz. We devise an efficient algorithm to track the elastomer's deformation through the imprinted markers despite the sensor's sparse output. Benchmarking experiments demonstrate Evetac's capabilities of sensing vibrations up to 498 Hz, reconstructing shear forces, and significantly reducing data rates compared to RGB optical tactile sensors. Moreover, Evetac's output and the marker tracking provide meaningful features for learning data-driven slip detection and prediction models. The learned models form the basis for a robust and adaptive closed-loop grasp controller capable of handling a wide range of objects. We believe that fast and efficient event-based tactile sensors like Evetac will be essential for bringing human-like manipulation capabilities to robotics. The sensor design is open-sourced at https://sites.google.com/view/evetac .
Placing by Touching: An empirical study on the importance of tactile sensing for precise object placing
Oct 05, 2022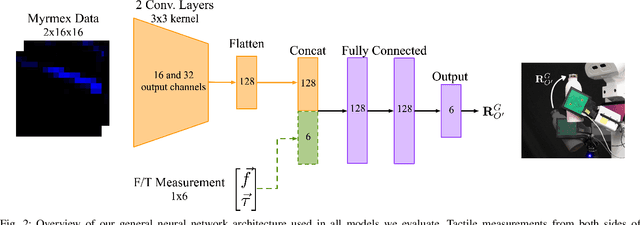
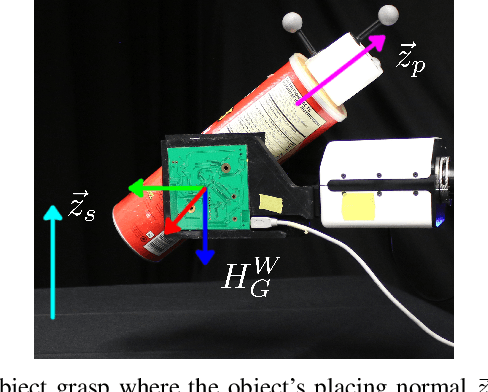
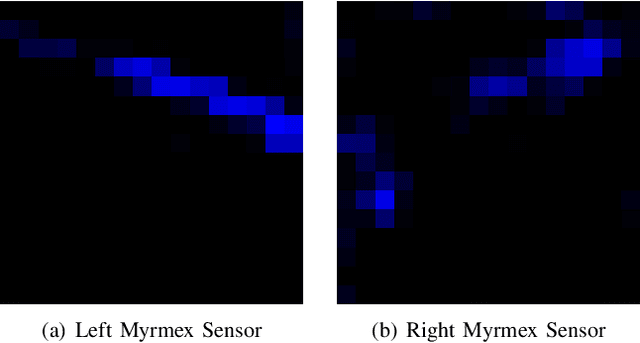

Tactile sensors are promising tools for endowing robots with embodied intelligence and increased dexterity. These sensors can provide robotic systems with direct information about physical interactions with the world, which is difficult to obtain from extrinsic perception systems. This work deals with a practical everyday living problem: stable object placement on flat surfaces starting from unknown initial poses. Common approaches for object placing either require complete scene specifications or indirect sensor measurements, such as cameras which are prone to suffer from occlusions. Instead, this work proposes a novel approach for stable object placing that combines tactile feedback and proprioceptive sensing. We devise a neural architecture that estimates a rotation matrix which results in a corrective gripper movement that aligns the object with the table and paves the way for the subsequent stable object placement. We compare models with different sensing modalities, such as force-torque and an external motion capture system, in real-world object placement tasks with different objects. Our experimental evaluation of the placing policies with a set of unknown everyday objects reveals an impressive generalization of the tactile-based pipeline and suggests that tactile sensing plays a vital role in the intrinsic understanding of dexterous object manipulation. Videos of our approach are available at https://sites.google.com/view/placing-by-touching.
SE(3)-DiffusionFields: Learning smooth cost functions for joint grasp and motion optimization through diffusion
Sep 19, 2022
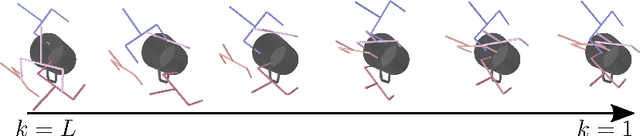

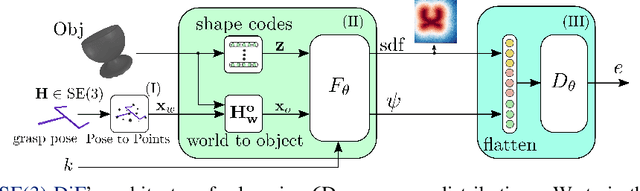
Multi-objective optimization problems are ubiquitous in robotics, e.g., the optimization of a robot manipulation task requires a joint consideration of grasp pose configurations, collisions and joint limits. While some demands can be easily hand-designed, e.g., the smoothness of a trajectory, several task-specific objectives need to be learned from data. This work introduces a method for learning data-driven SE(3) cost functions as diffusion models. Diffusion models can represent highly-expressive multimodal distributions and exhibit proper gradients over the entire space due to their score-matching training objective. Learning costs as diffusion models allows their seamless integration with other costs into a single differentiable objective function, enabling joint gradient-based motion optimization. In this work, we focus on learning SE(3) diffusion models for 6DoF grasping, giving rise to a novel framework for joint grasp and motion optimization without needing to decouple grasp selection from trajectory generation. We evaluate the representation power of our SE(3) diffusion models w.r.t. classical generative models, and we showcase the superior performance of our proposed optimization framework in a series of simulated and real-world robotic manipulation tasks against representative baselines.
Graph-based Reinforcement Learning meets Mixed Integer Programs: An application to 3D robot assembly discovery
Mar 08, 2022
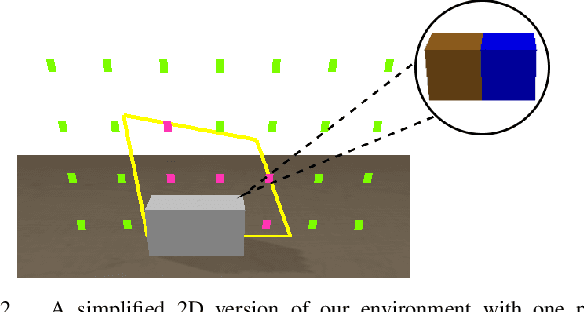

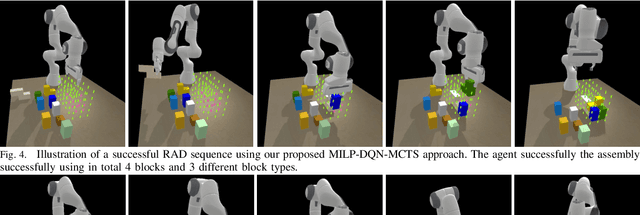
Robot assembly discovery is a challenging problem that lives at the intersection of resource allocation and motion planning. The goal is to combine a predefined set of objects to form something new while considering task execution with the robot-in-the-loop. In this work, we tackle the problem of building arbitrary, predefined target structures entirely from scratch using a set of Tetris-like building blocks and a robotic manipulator. Our novel hierarchical approach aims at efficiently decomposing the overall task into three feasible levels that benefit mutually from each other. On the high level, we run a classical mixed-integer program for global optimization of block-type selection and the blocks' final poses to recreate the desired shape. Its output is then exploited to efficiently guide the exploration of an underlying reinforcement learning (RL) policy. This RL policy draws its generalization properties from a flexible graph-based representation that is learned through Q-learning and can be refined with search. Moreover, it accounts for the necessary conditions of structural stability and robotic feasibility that cannot be effectively reflected in the previous layer. Lastly, a grasp and motion planner transforms the desired assembly commands into robot joint movements. We demonstrate the performance of the proposed method on a set of competitive simulated robot assembly discovery environments and report performance and robustness gains compared to an unstructured end-to-end approach. Videos are available at https://sites.google.com/view/rl-meets-milp .
A Robot Cluster for Reproducible Research in Dexterous Manipulation
Sep 22, 2021

Dexterous manipulation remains an open problem in robotics. To coordinate efforts of the research community towards tackling this problem, we propose a shared benchmark. We designed and built robotic platforms that are hosted at the MPI-IS and can be accessed remotely. Each platform consists of three robotic fingers that are capable of dexterous object manipulation. Users are able to control the platforms remotely by submitting code that is executed automatically, akin to a computational cluster. Using this setup, i) we host robotics competitions, where teams from anywhere in the world access our platforms to tackle challenging tasks, ii) we publish the datasets collected during these competitions (consisting of hundreds of robot hours), and iii) we give researchers access to these platforms for their own projects.